Machine Learning Methods for Modeling and Classification of Fashion-MNIST
David Blumenstiel, Bonnie Cooper, Robert Welk, Leo Yi
"2021-12-10"
Fashion MNIST

Our Approach
Why Dimensionality Reduction?

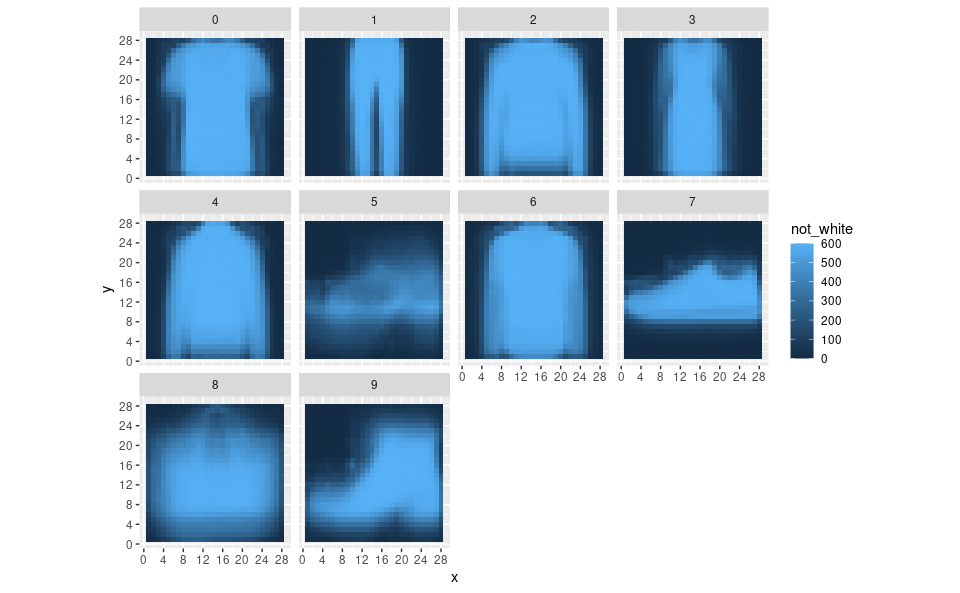
Dimensionality Reduction: Feature Engineering
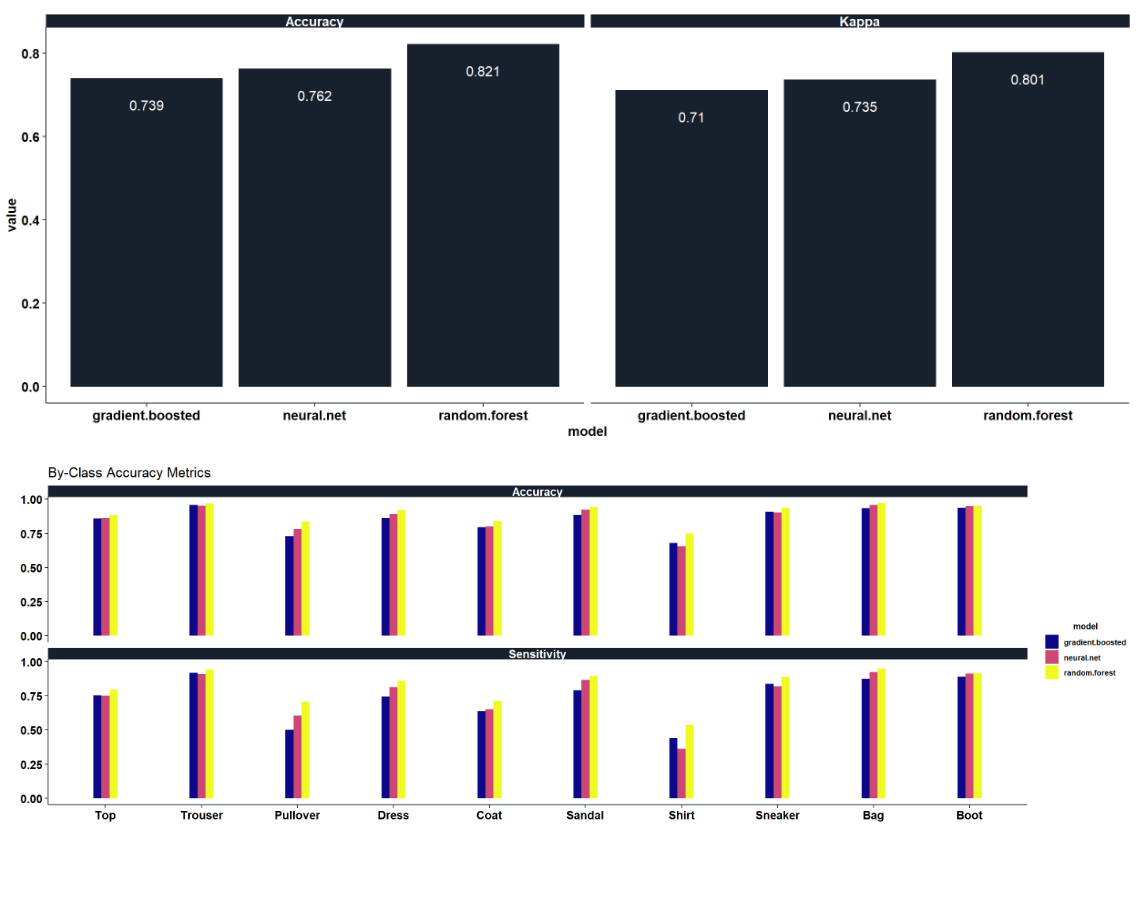
Modeling Fashion-MNIST with the Feature Engineered Dataset
Dimensionality Reduction: PCA
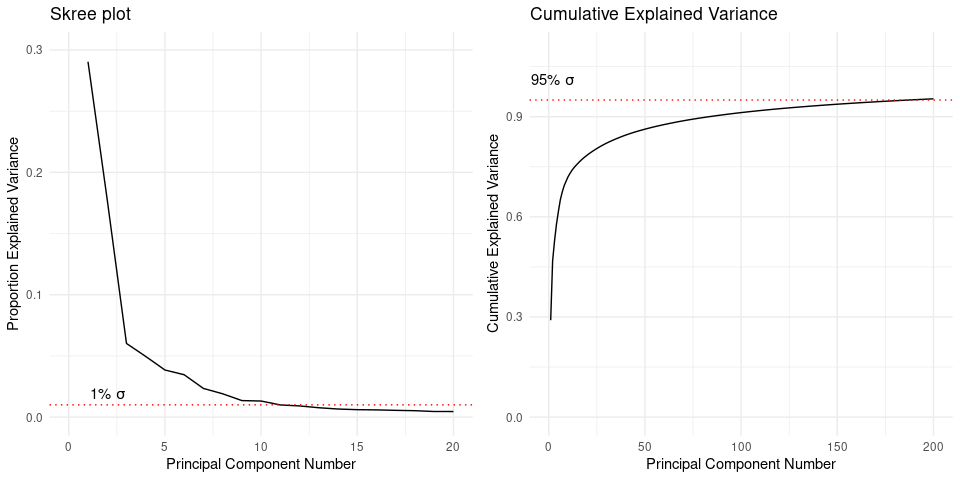
- We performed PCA on the 784 pixel value features from the original dataset.
- The skree plot (left) shows that the first ~12 components describe most of the data variance
- The Cumulative Explained Variance plot (right) shows that 95% of the variance can be explained by the first 187 components
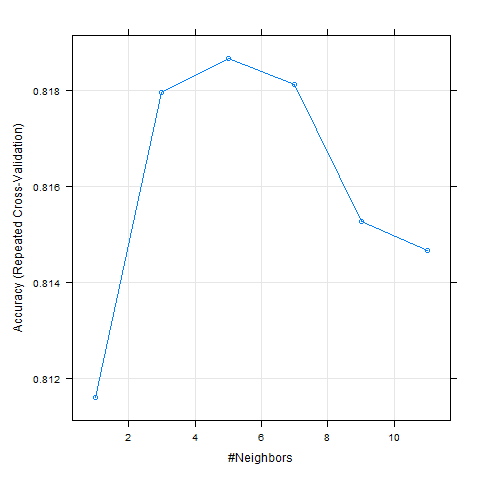
kNN with & without PCA dimensionality reduction
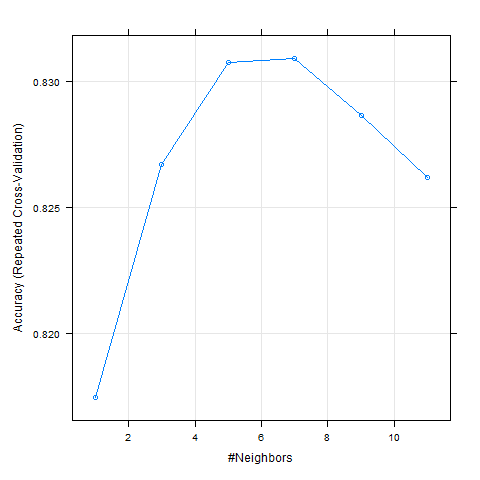
Modeling Fashion-MNIST using PCA: Additional Machine Learning Models