An Introduction to Bayesian Inference
Rose Maier & Jacob Levernier
PSY612, Winter 2015
Probability
Probability Examples
Conditional Probability
A conditional probability is NOT the same as its inverse
Conditional Probability and *p* = .05
Bayes' theorem, and its notation
Problems with NHST
The (muddled) logic of p values
- p = P(D|N)
- ? = P(N|D)
This was highlighted in a popular Nature article last year:
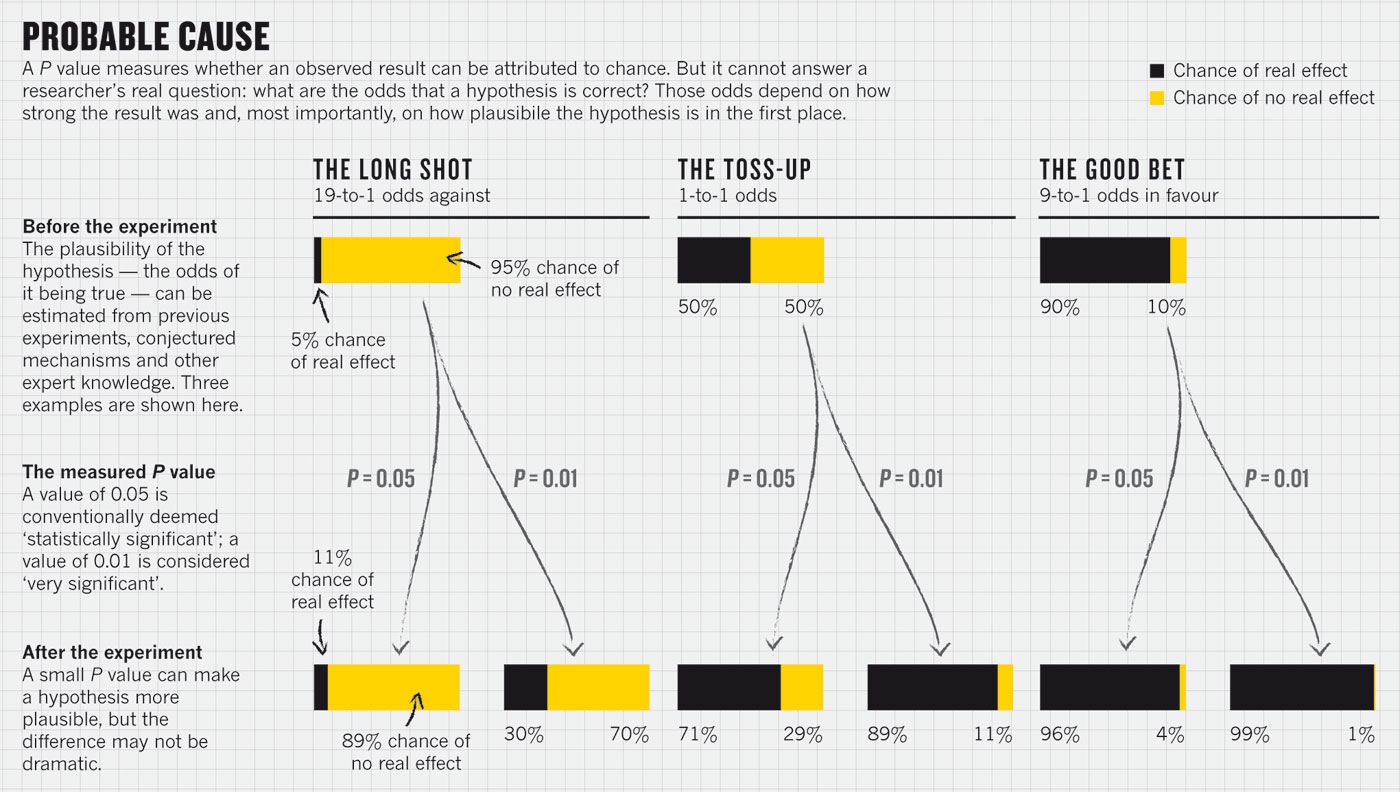
Problems with NHST, cont.
Bayes doesn't care about your intentions
Clarification: Bayes vs. Frequentist
Clarification: Bayes vs. Frequentist
Bringing in background knowledge
We can use *Distributions* of priors!

We can use *Distributions* of priors!

Nuts and bolts
Nuts and bolts
The prior!

Nuts and bolts
The data!

Nuts and bolts
The posterior!

Nuts and bolts
Nuts and bolts
Nuance in the results

Problems Bayes won't fix for you
How to learn more
Questions?
Bayesian inference elegantly incorporates background knowledge
Bayes Theorem revisited
- P(θ|D) = P(D|θ)*P(θ) / P(D)
- “posterior = likelihood * prior / evidence”
Silver 9-11 example:

Bringing in background knowledge
