class: center, middle, inverse, title-slide # Scaling R with Spark ## using sparklyr ### Javier Luraschi ### 01/17/2019 --- class: panel-wide-slide, left # What to do when code is slow? ```r mtcars %>% lm(mpg ~ wt + cyl, .) ``` -- ```r # Sample mtcars %>% dplyr::sample_n(10) %>% lm(mpg ~ wt + cyl, .) ``` -- ```r # Profile profvis::profvis(mtcars %>% lm(mpg ~ wt + cyl, .)) ``` -- ```r # Scale Up cloudml::cloudml_train("train.R") ``` -- ```r # Scale Out mtcars_tbl %>% sparklyr::ml_linear_regression(mpg ~ wt + cyl) ``` -- .small-note[**Note:** There are many more ways to sample, scale-up and scale-out.] --- class: panel-narrow-slide, left # Scaling Out with R and Spark  ```r # Scale Out mtcars_tbl %>% sparklyr::ml_linear_regression(mpg ~ wt + cyl) ``` --- class: panel-narrow-slide, left # How to use R with Spark? ```r library(sparklyr) # R Interface to Apache Spark spark_install() # Install Apache Spark sc <- spark_connect(master = "local") # Connect to Spark cluster ``` -- ```r cars_tbl <- spark_read_csv(sc, "cars", "mtcars/") # Read data in Spark summarize(cars_tbl, n = n()) # Count records with dplyr dbGetQuery(sc, "SELECT count(*) FROM cars") # Count records with DBI ``` -- ```r ml_linear_regression(cars_tbl, mpg ~ wt + cyl) # Perform linear regression ``` -- ```r pipeline <- ml_pipeline(sc) %>% # Define Spark pipeline ft_r_formula(mpg ~ wt + cyl) %>% # Add formula transformation ml_linear_regression() # Add model to pipeline fitted <- ml_fit(pipeline, cars_tbl) # Fit pipeline ``` -- ```r spark_context(sc) %>% invoke("version") # Extend sparklyr with Scala spark_apply(cars_tbl, nrow) # Extend sparklyr with R ``` --- class: panel-narrow-slide, left # What about realtime data? 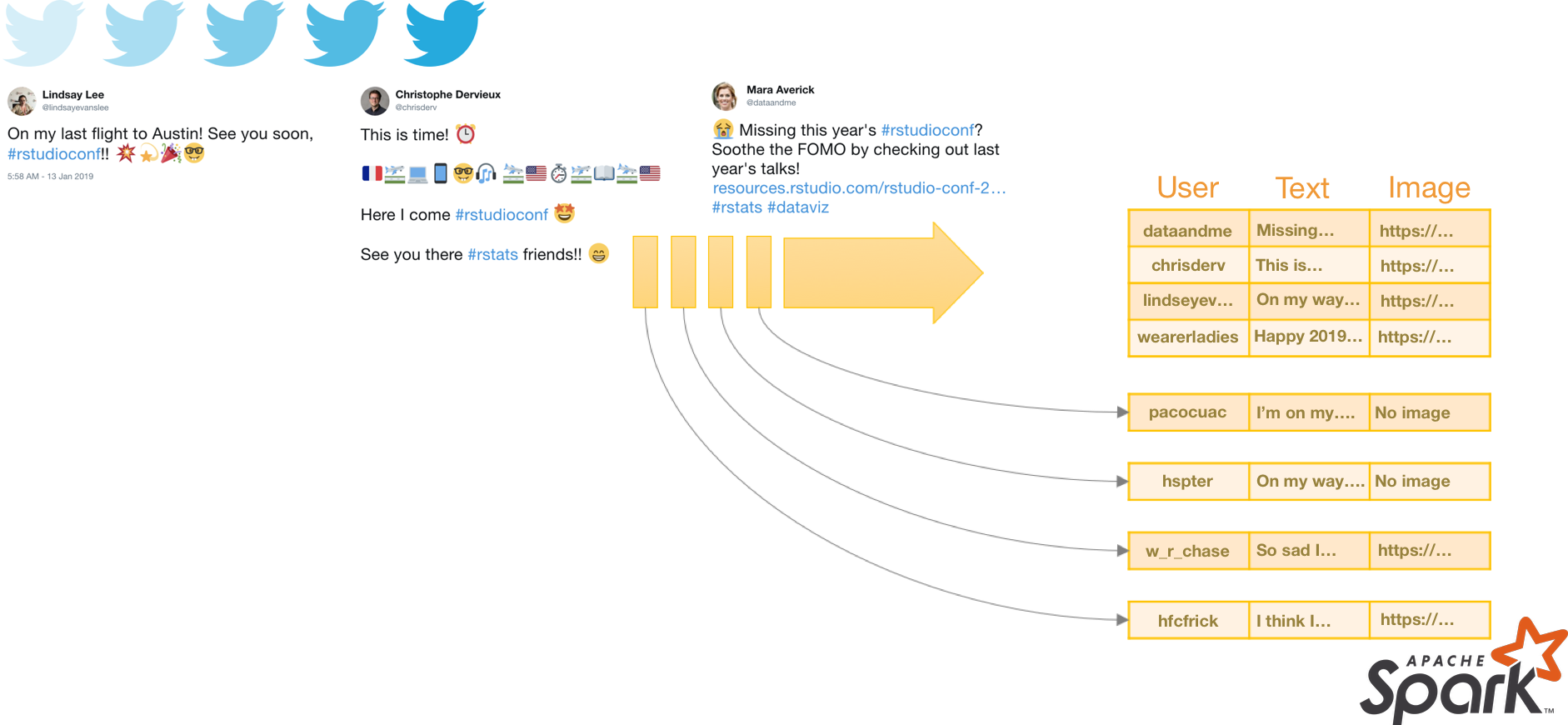 --- class: panel-narrow-slide, left # Spark Structured Streams ```r cars_str <- stream_read_csv(sc, "mtcars/", "cars") # Read stream in Spark ``` -- ```r out_str <- summarize(cars_str, n = n()) # Count records with dplyr out_str <- dbGetQuery(sc, "SELECT count(*) FROM cars") # Count records with DBI ``` -- ```r out_str <- ml_transform(fitted, cars_str) # Apply pipeline to stream ``` -- ```r out_str <- spark_apply(cars_str, nrow) # Extend streams with R ``` -- ```r stream_write_csv(out_str, "output/") # Write as a CSV stream reactiveSpark(out_str) # Use as a Shiny reactive ``` --- class: panel-narrow-slide, left # Streaming with Spark, Kafka and Shiny > Apache Kafka is an open-source stream-processing software platform that provides a unified, high-throughput and low-latency for handling real-time data feeds. --  --- class: panel-narrow-slide, left # What's new in Spark and R? **Streams**, **MLeap**, **Kubernetes** and **RStudio 1.2** integration. -- 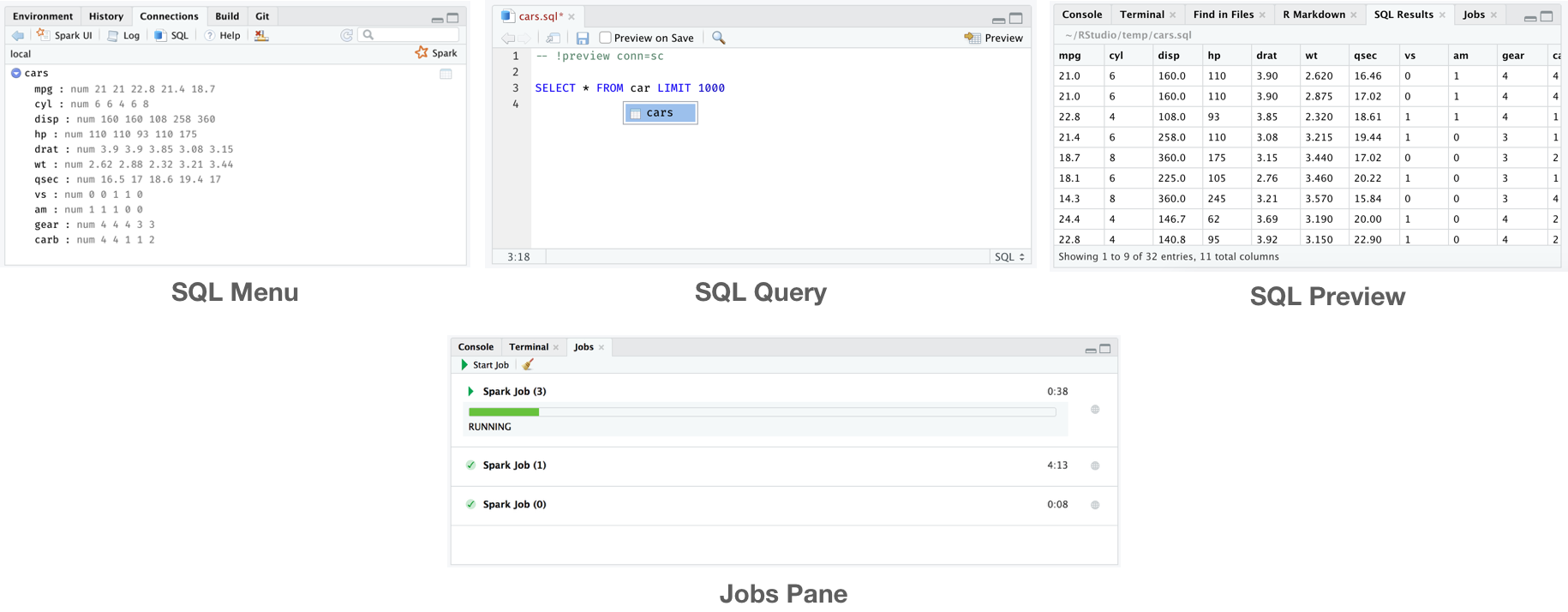 --- class: panel-narrow-slide, left # What are we currently working on? ### - Faster data transfer with Apache Arrow: [pull/1611](https://github.com/rstudio/sparklyr/pull/1611). -- ### - [XGBoost](https://github.com/rstudio/sparkxgb) on Spark: [rstudio/sparkxgb](https://github.com/rstudio/sparkxgb). --- class: panel-narrow-slide, left # Arrow on Spark > .small-quote[Arrow is a cross-language development platform for in-memory data.] -- ```r devtools::install_github("apache/arrow", subdir = "r", ref = "dc5df8f") devtools::install_github("rstudio/sparklyr") library(arrow) library(sparklyr) ``` -- .pull-left[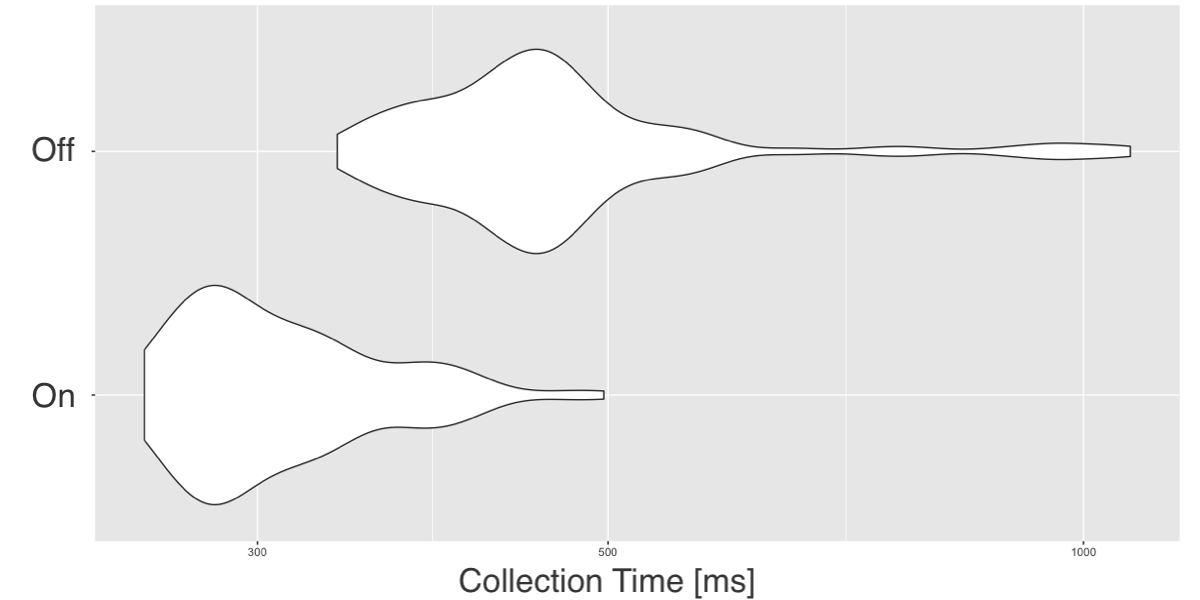] .pull-right[] --- class: panel-narrow-slide, left # XGBoost on Spark > sparkxgb is a sparklyr extension that provides an interface to XGBoost on Spark. -- ```r devtools::install_github("rstudio/sparkxgb") library(sparkxgb) ``` -- ```r iris_tbl <- sdf_copy_to(sc, iris) xgb_model <- xgboost_classifier( iris_tbl, Species ~ ., objective = "multi:softprob", num_class = 3, num_round = 50, max_depth = 4 ) xgb_model %>% ml_predict(iris_tbl) %>% glimpse() ``` --- class: panel-wide-slide, left # Thank you! ### **Docs**: .resource-link[spark.rstudio.com] ### **Blog**: blog.rstudio.com/tags/sparklyr ### **R Help**: community.rstudio.com ### **Spark Help**: stackoverflow.com/tags/sparklyr ### **Issues**: github.com/rstudio/sparklyr/issues ### **Chat**: gitter.im/rstudio.sparklyr