Deep Learning with R for Modelling Molecular Interactions
Leon Eyrich Jessen, PhD
May 30th 2018

Postdoctoral Researcher
Immunoinformatics and Machine Learning group
Department of Bio and Health Informatics
Technical University of Denmark
Intelligent Cloud Conference 2018
Day 2 — AI / Data Science Track — session 4 — 13:30-14:30
 @jessenleon
@jessenleon
The difficult just-after-lunch session...
So... This happened!
- Keynote at rstudio::conf 2018 in San Diego: Official Announcement of
KerasandTensorFlowforRby RStudio CEO JJ Allaire

Why am I here?
Who am I?
This is my playground: Computerome - National Life Science Supercomputing Center

Computerome is in the top 150 largest supercomputers in the world

Located at DTU Campus Risø
So... Bioinformatics - What is that?
What is Data Science?
- Data Science is an intrinsic interdisciplinarity field, comprised as below

What is Bioinformatics?
- Bioinformatics is Data Science with domain specific knowledge in Biology

So, what are you?
What is Immunoinformatics?
- Immunoinformatics is Bioinformatics with a focus on immunology (The study of the human immune system)

More specifically... This is what I do...
- I use Machine Learning methodology (Artificial Neural Networks) to study the human immune system and how it responds

So What is Machine Learning?
So, let us take a look at Artificial Neural Networks
What are Artificial Neural Networks?

Source: Bruce Blaus | Multipolar Neuron | CC BY 3.0
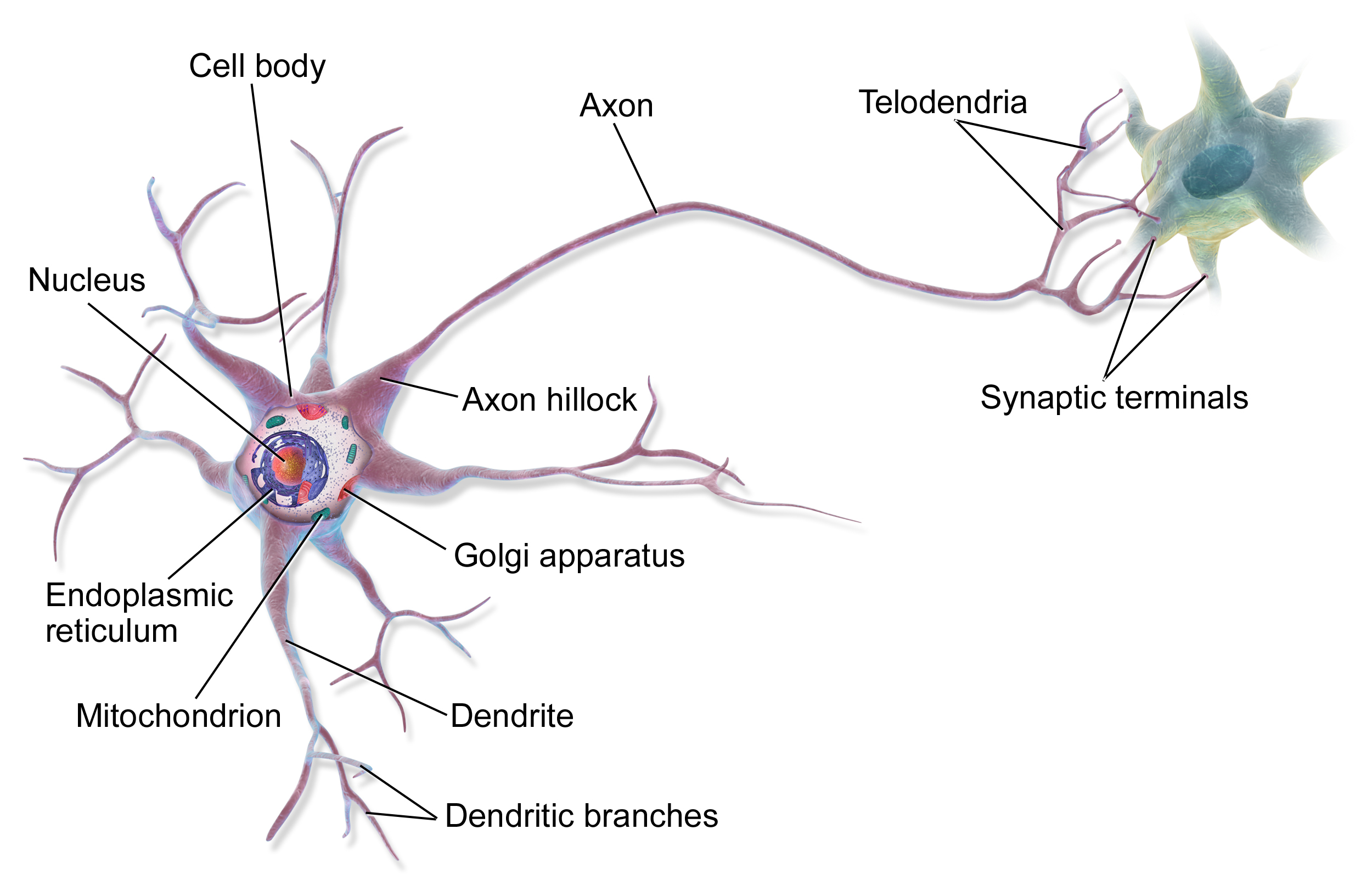{kind=link}
Basic Feed Forward Multilayer Perceptron - Architecture
- Fully connected dense neural network wih one input layer, one hidden layer and one output neuron

- Based on input, the neuron has to 'decide' whether to send a signal via the axon or not
Source: Bruce Blaus | Multipolar Neuron | CC BY 3.0
Basic Feed Forward Multilayer Perceptron - Information Flow Input to Hidden
Input:
- \( H_{j} = I_{i} \cdot v_{i,j} + I_{i+1} \cdot v_{i+1,j} + I_{i+...} \cdot v_{i+...,j} + I_{n} \cdot v_{n,j} + B_{I} \cdot v_{n+1,j} = \)
\( \sum_{i}^{n} I_{i} \cdot v_{i,j} + B_{I} \cdot v_{n+1,j} = \sum_{i}^{n+1} I_{i} \cdot v_{i,j} = \textbf{I} \cdot \textbf{v}_j \)
Output:
- \( S(H_{j}) = \frac{1}{1+e^{-H_{j}}} \)


- Low input and the neuron is turned off (emits 0)
- Medium input and the neuron emits a number inbetween 0 and 1
- High input and the neuron is turned on (emits 1)
Basic Feed Forward Multilayer Perceptron - Information Flow Hidden to Output
Input: \( O = H_{j} \cdot w_{j} + H_{j+1} \cdot w_{j+1} + H_{j+...} \cdot w_{j+...} + H_{m} \cdot w_{m} + B_{H} \cdot w_{m+1} = \sum_{j}^{m} H_{j} \cdot w_{j} + B_{H} \cdot w_{m+1} = \sum_{j}^{m+1} H_{j} \cdot w_{j} = \textbf{H} \cdot \textbf{w} \)
Output: \( S(O) = \frac{1}{1+e^{-O}} \)

Basic Feed Forward Multilayer Perceptron - Back Propagate Prediction Error
Error: \( E = MSE(O,T) = \frac{1}{2} \left( o - t \right)^2 \)
Updates: \( \Delta w = - \epsilon \frac{\delta E}{\delta w} \) and \( \Delta v = - \epsilon \frac{\delta E}{\delta v} \), where \( \epsilon \) is the learning rate

Why are artificial neural networs so powerful?
- They can identify context dependence!
- I.e. the “meaning” of each variable depends not only on its observed value, but also on the context in which it was observed!

Historic Highlights of Artificial Neural Networks?
Keras and TensorFlow - What you need to know
The suite of TensorFlow R packages
Let us get to it - Installing Keras and TensorFlow
Installing Keras and TensorFlow
Examples...
Example 1: Three-Class Classifier using the Classic Iris data set and Keras/TensorFlow
The Iris data set

The Iris data set

Neural Network Classifier Model
Here is an illustration of the model we will be building with 35 parameters, i.e. \( (n_{features} + 1) \cdot m_{hidden} + (m_{hidden} + 1) \cdot l_{output} \)

Prepare data
Scaling
Feature distributions before scaling
Feature distributions after scaling

Prepare data
Set Architecture, Compile Model and Train Classifier
Visualise training
The fit() function returns a history object, which we can plot like so
plot(history)

Evaluate Model Performance
Predict on New Data
Confusion Matrix Visualisation
…and finally we can visualise the confusion matrix based on the original 20% left out test data

Example 2: Three-Class Classifier using Copenhagen Apartment Prices
The Apartment data set
The Apartment data set - Data Prep
The Apartment data set - Feature selection
The Apartment data set - Feature scaling


The Apartment data set - Feature PCA (PC2 vs PC1)

The Apartment data set - Feature PCA (PC3 vs PC2)

The Apartment data set - Create Test and Training Partitions
The Apartment data set - Check Class Balances

Set Architecture, Compile Model and Train Classifier
Visualise training
The
fit()function returns ahistoryobject, which we can plot like soNote, how this time, we set a validation split, allowing us to see how the accuracy changes on both the training and the validation data
Here, it is quite clear that the accuracy on the training data is much better than that of the validation data
This is known as overfitting and results in learning the data, rather than the trend

plot(history)

Evaluate Model Performance
Predict on New Data
Confusion Matrix Visualisation
…and finally we can visualise the confusion matrix based on the original 20% left out test data

Example 3: Molecular Interactions
Immunology - What you need to know
 Figure by Eric A. J. Reits
Figure by Eric A. J. Reits
Cancer Immunotherapy

Source: Simon Caulton | Adoptive T-cell therapy | CC BY 3.0
{kind=link}
Data
Data - Class Balance
Once again, we check the class balance

Data
About Cross Validation

Defining and Compiling the Model
Training the model
Add Predictions to the Peptide Data Set
Visualisation of Predictions
Only allow each model to predict on the unseen test partition

Training
- Despite us only running the training for 10 epochs, the MSE decreases very rapidly!

Individual Model Performances
- The area under the Receiver Operator Characterstics curve (the ROC curve) is the so called AUC value.
- If \( AUC = 1 \), then you have a perfect predictor, if \( AUC = 0.5 \), then you have a random predictor

Wisdom of the crowd

Performance of overall model
Receiver Operator Characterstics curve

Performance on Left Out Test Set (Partition 6)
- For this set, we make 20 predictions for each \( x \) and assign the mean as the final prediction \( \hat{y} \)
Receiver Operator Characterstics curve

In summary
A few tips, tricks and words of advice...
Model Deployment
Model Deployment
Final Slides...
Resources
Acknowledgements

- Professor Morten Nielsen for allowing me to tab into his 25+ years of experience in using artificial neural networks for modeling biological systems
- Postdoctoral Researcher Vanessa Jurtz, with whom I collaborate on the netTCR project, part of which I prensented here today
- Professor Sine Reker Hadrup for generating data for me to play with
- The Independent Research Fund Denmark for paying my salery
- And then of course the organisers for giving me this oppertunity to talk about my research
- And should you be curious… Yes, I made this presentation in
R
Closing Remarks
