Strength of Concrete
Brian Kreis
April 24, 2018
Observational vs Designed Experiments
Designed Experiments
Concrete
Concrete is integral for the infrastructure of industrial societies. Its strength and the optimal makeup to improve that strength have been widely studied. We will look at the various proportions of mixture ingredients to maximize compressive strength.
The ingredients of interest are cement, fly ash, blast furnace slag, water, superplasticizer, coarse & fine aggregate. All at a scale of kg/m3.


A Quick Look at Each Variable


Predictor Plotted with Outcome

Predictors
The Models
Parallel Processing
Time functions
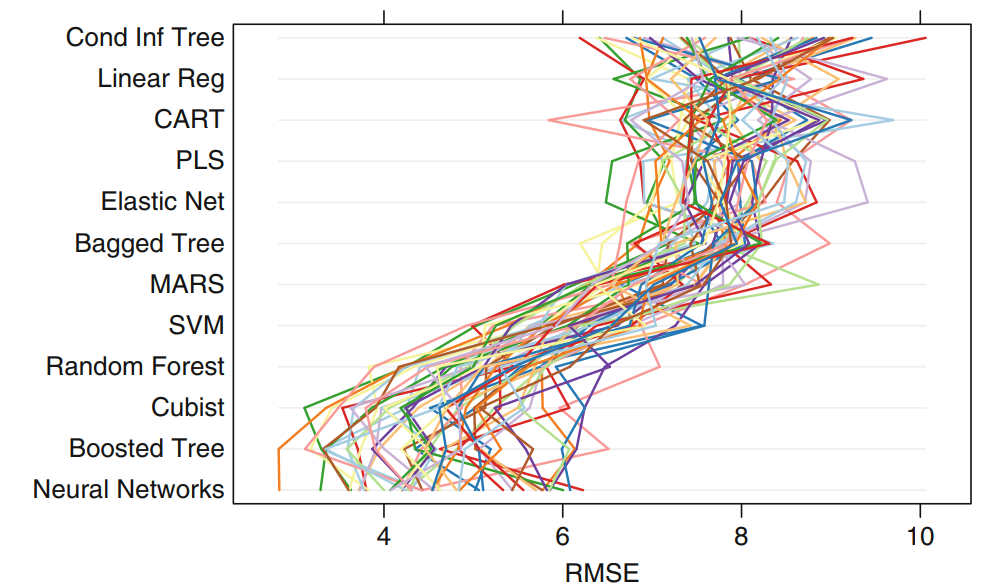
Results - RMSE
Parallel coordinate plot showing performance for each cross validation set
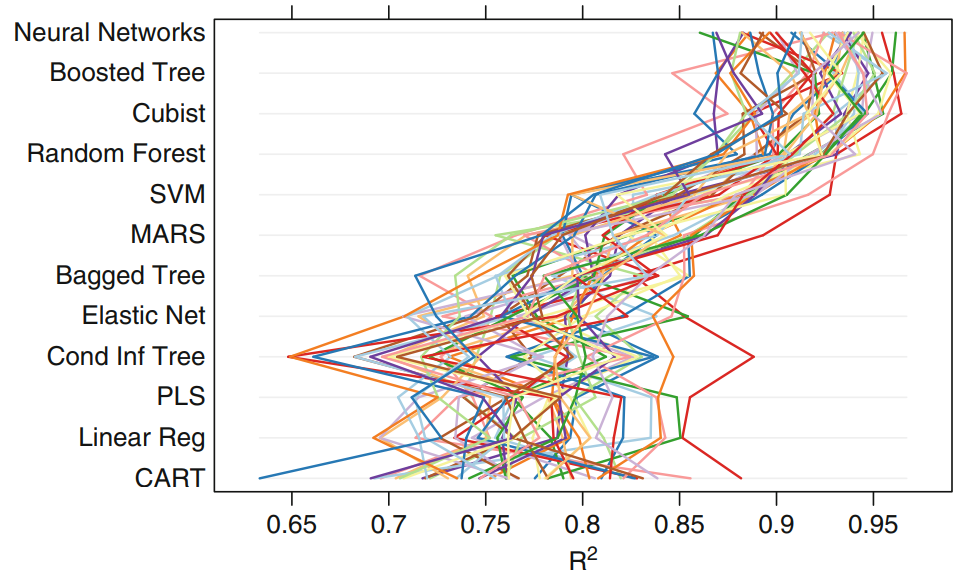
Results - R2
Parallel coordinate plot showing performance for each cross validation set
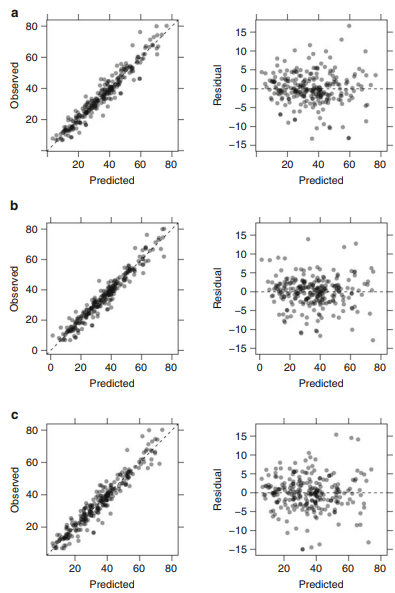
Top 3 Models - Based on RMSE
Optimizing Compressive Strength
Optimizing Compressive Strength - 2
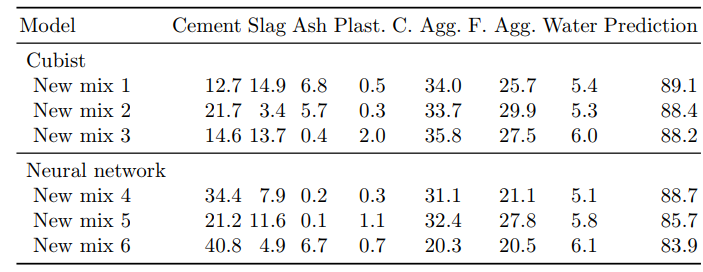
Search Results
Predicted compressive strength and mixture composition compared to our highest values of 81.75, 79.99 and 78.8 in our training set:
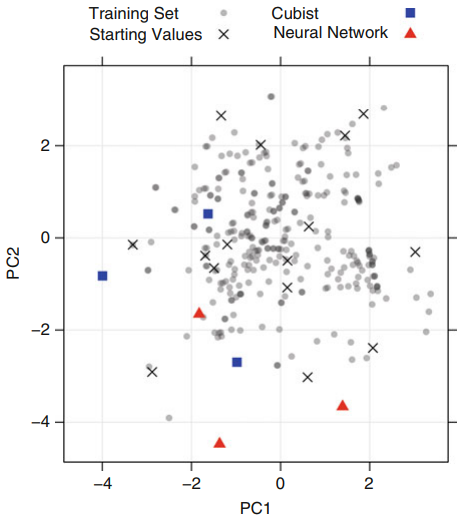
PCA Plot
Multiparameter Optimization
Multiparameter Optimization - 2
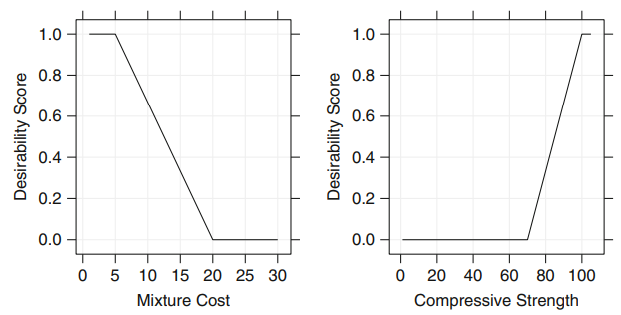
Two desirability functions for cost and strength