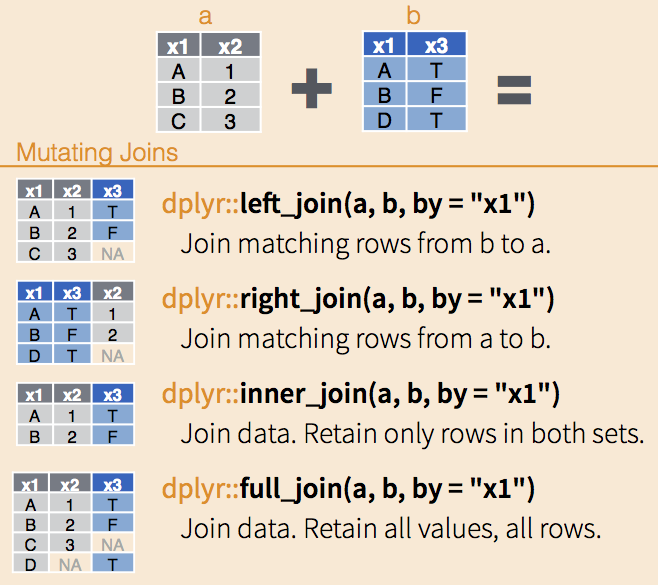
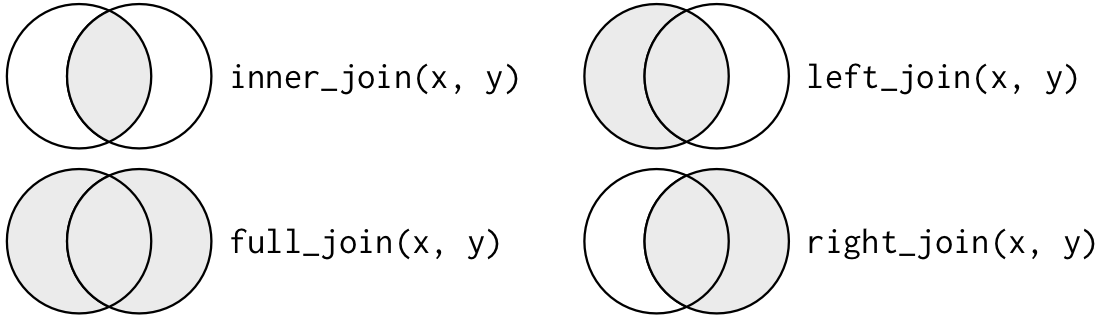install.packages(c('dplyr','data.table'))
library(data.table) # melt & aggregate data
library(dplyr) # data manipulation
install.packages('tidyverse')
library(tidyverse) #includes ggplot2, dplyr, tidy, + more
Burrito data:
url<-'https://raw.githubusercontent.com/collnell/burritos/master/sd_burritos.csv' ritos <- fread(url)