Advanced data wrangling
Goals of this lesson

- Introduction to the tidyverse
- tidyR and dplyr review
- Tidy data
- Data wrangling in the tidyverse
- Manipulating strings using stringr
I. The tidyverse: Tibbles and pipes oh my!
![]()
![]()
![]()
install.packages('tidyverse')
install.packages('stringr')
install.packages('lubridate')
I. The tidyverse: Tibbles and pipes oh my!
I. The tidyverse: Tibbles and pipes oh my!
I. The tidyverse: Tibbles and pipes oh my!
I. The tidyverse: Tibbles and pipes oh my!
I. The tidyverse: Tibbles and pipes oh my!
The Pipe operator (%>%) allows you to pass output from an argument on the left to an argument on the right without assigning a name or nesting functions.
For example, we can make use the tbl_df function and a pipe to turn a regular data frame to a tibble:
dataFrame %>%
tbl_df
I. The tidyverse: Tibbles and pipes oh my!
The Pipe operator (%>%) allows you to pass output from an argument on the left to an argument on the right without assigning a name or nesting functions.
For example, we can make use the tbl_df function and a pipe to turn a regular data frame to a tibble:
dataFrame %>%
tbl_df
Note the convention to start a new line after each pipe. This is to make your code more readable.
I. The tidyverse: Tibbles and pipes oh my!
II. Tidyr review
III. dplyr review
IV. Rules of the road for tidy data
- Tidy data are easy to:
- Manipulate
- Summarize
- Analyze
- Understanding dirty vs. clean data is key
IV. Rules of the road for tidy data
IV. Rules of the road for tidy data
IV. Rules of the road for tidy data
IV. Rules of the road for tidy data
IV. Rules of the road for tidy data
IV. Rules of the road for tidy data
IV. Rules of the road for tidy data
IV. Rules of the road for tidy data
IV. Rules of the road for tidy data
IV. Rules of the road for tidy data
IV. Rules of the road for tidy data
IV. Rules of the road for tidy data
IV. Rules of the road for tidy data
- Store all data in long format
- One level of observation per table
- One table per level of observation
- No derived variables!
- One data value per field
- Always use the international date standard
V. Data wrangling in the tidyverse: Rules of wrangling
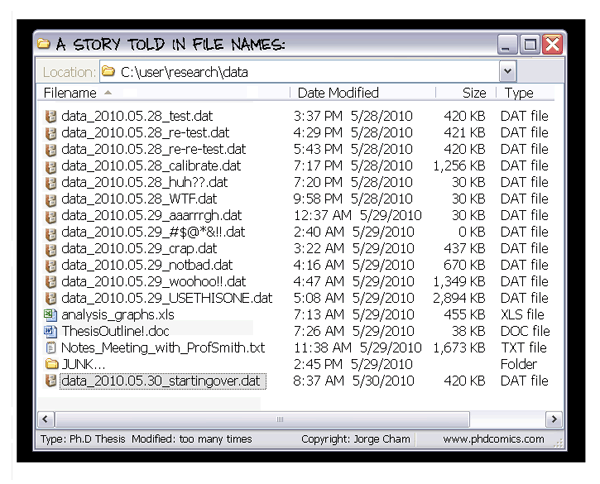
V. Data wrangling in the tidyverse: Rules of wrangling
V. Data wrangling in the tidyverse: Rules of wrangling
V. Data wrangling in the tidyverse: Rules of wrangling
V. Data wrangling in the tidyverse: Rules of wrangling
V. Data wrangling in the tidyverse: Rules of wrangling
V. Data wrangling in the tidyverse: Rules of wrangling
V. Data wrangling in the tidyverse: Rules of wrangling
V. Data wrangling in the tidyverse: Rules of wrangling
V. Data wrangling in the tidyverse: Rules of wrangling
V. Data wrangling in the tidyverse: Rules of wrangling
VI. String manipulation in stringr

Manipulating strings is a common data task that stringr has greatly simplified.
Here we'll look at the functions:
- str_to_upper: Make strings all upper case
- str_detect: Detect a string within a value
- str_trim: Remove white space from a string
- str_replace_all: Replace characters in a string
- str_sub: Extract part of a string by position
VI. String manipulation in stringr
VI. String manipulation in stringr
VI. String manipulation in stringr
VI. String manipulation in stringr
VI. String manipulation in stringr
VI. String manipulation in stringr
VI. String manipulation in stringr
VI. String manipulation in stringr
VI. String manipulation in stringr
Task: There are lots of problems with the band numbers in the file we've been using. Clean them using stringr!