Predicting next words in mobile apps
E. Bertrand
October, 4th 2016
Helping mobile devices users to reduce typing effort
1. Purpose of the project
Reducing the typing effort of mobile devices users has become a necessity as time spent on these devices is growing rapidly.
One of the ways to meet this challenge is suggesting to users the most likely words, taking into account what they have typed so far. Then users can select one of the suggested words, thus reducing typing actions.
For this purpose, a prototype for predicting the next three most likely words after a phrase or sequence of words has been built. This prototype is based on sound statistical algorithms and models developed in the field of Natural Language Processing.
The prototype built shows an estimated accuracy of 26%, which is a considerable performance, while maintaining a size and speed appropriate for mobile devices.
2. Foundations: N-Grams models
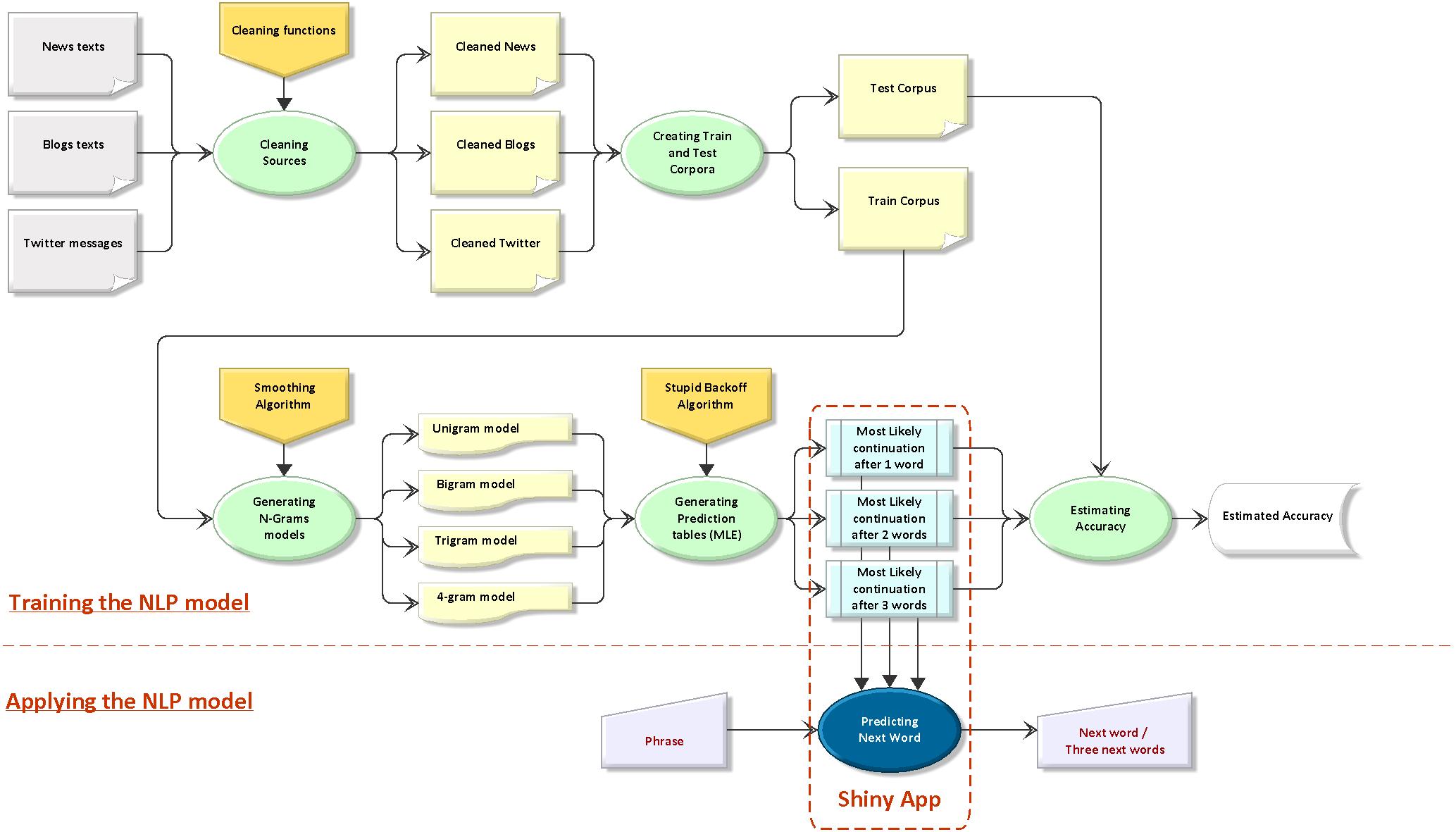
We predict next words based on statitiscal language models called N-grams, where the conditioned probability for a word given a previous limited sequences of N - 1 words is estimated (Markov's assumption).
For training and building these N-grams up, we use data from three different, heterogeneous text sources: news (~75,000 elements), blogs (~900,000 elements) and twitter messages (~2,300,000 elements).
Data has been cleaned (special characters, profanities, links, hashtags, etc.) and then splitted in two corpora: a train corpus, for building the models; and a test corpus, for estimating the performance of them. Then we produce a set of unigrams, bigrams, trigrams and 4-grams, pruned for frequencies below 1 to 3 (depending on the N-gram order) for the shake of reducing their size.
For being able to deal with word sequences not present in the training corpus we use the “stupid backoff” algorithm: if a sequence is not present in a higher-order N-gram, we remove the first word and backoff to a lower-order N-gram, weighing the result by a fixed factor (\( \lambda = 0.4 \), as recommended by method proponents).
3. Prediction tables and estimated model's performance
- N-grams models are transformed in prediction tables by selecting only the three most likely continuations (after scoring all possible results with “stupid backoff”). This strategy sacrifices some accuracy in favor of greater speed and less data footprint on the server, which are key requirements on mobile apps. See on the right a small sample of the 4-gram (3 + 1 words) prediction table.
- Model performance of this approach, estimated as accuracy against an independent test subset, shows consistent results with similar reported experiences. As it can be seen on the right, starting with 4-grams (backed off by lower-order N-grams) and the “anyone of three most likely words” option, we reach a 26.08% of right predictions, which is a good percentage.
| ngram | w_1 | w_2 | w_3 |
|---|---|---|---|
| new box of | crayons | chocolates | chocolate |
| new boy band | ever | for | like |
| new boyz performing | live | at | arts |
| model | accuracy_1w | accuracy_3w |
|---|---|---|
| bigrams | 11.57 | 20.46 |
| trigrams | 14.90 | 24.97 |
| 4-grams | 15.98 | 26.08 |
4. How do the Shiny applications work
Applications are in a Shiny dashboard together technical & general info. Wait some seconds before the supporting tables are fully loaded and ready (shown the in upper-right corner).
In the first application, simply type, or paste, a phrase and click the 'Next word' button. On the right, in bold red, you can see the predicted next word.
In the second application, we simulate a mobile app: you start typing and after you introduce a space or punctuation mark you can see the three most likely continuations. You can choose one of them (clicking on it) or continue typing.



5. Further information [*] and next steps
The R scripts for building the models and the Shiny dashboard is available in a GitHub repository. See also a diagram showing the whole process behind the solution.
The Shiny dashboard (including related documentation) can be accesed here.
Next version should consider and evaluate some improvements (among others):
- Adding 5-grams models and/or reducing pruning.
- More precise “Out-of-Vocabulary” smoothing algorithms than “stupid backoff”.
- Predictions depending on the context (twitter vs. blogs), and/or past user inputs.
{kind=link}
- [*] It has been reported that some external links from RPubs do not work properly (e.g. to GitHub). Circumvent this problem choosing “Open link in a new window” with the right mouse-button.