Exploratory Data Analysis with R
Jianhua Huang
05/31/2016
Why learn R

What R Can Do?
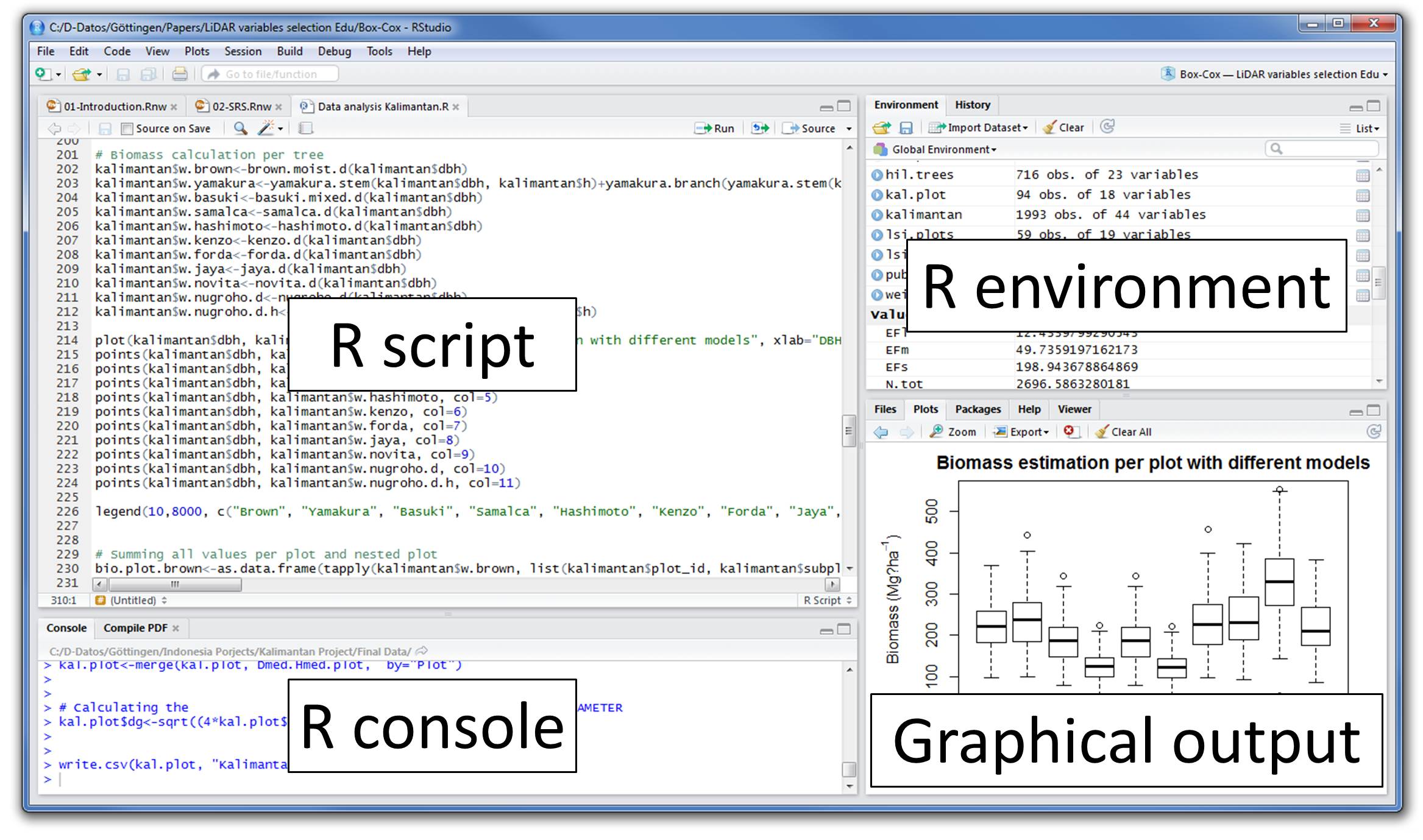
Rstudio Interface
Exploratory Data Analysis
History
- John Tukey (1961) -> Exploratory Data Analysis -> S -> R
Purposes
- Understand data properties
- Find data patterns
- Reveal data relationship
- Support the seleciton of modeling approach
Principles
- Preliminary!
- Fast!
- Informative!
Exploratory Data Analysis
Steps
- Read data
- Data overview
- Data type conversion
- Add new variables
- Exclude anomalous data
- Select rows
- Select columns
- Data transformation and aggregation
- Visualization
Reading data
Major functions
load(.rdata file)read.csvread.tableloadWorkbook->readWorksheet(XLConnect package, dependent on java)read_excel(readxl package)fread(data.table package, reading large csv fast)dbhandle->sqlQuery(RODBC package, work with SQL Server command)dbConnect->dbGetQuery(RMySQL package, work with MySQL command)- SQL Server built-in R Service since 2016
Reading data
# clean up memory
rm(list = ls()) # remove all variables saved in the memory
gc() # garbage collection
used (Mb) gc trigger (Mb) max used (Mb)
Ncells 290589 15.6 460000 24.6 350000 18.7
Vcells 489273 3.8 1023718 7.9 786398 6.0
load('C:/Projects/PDA/R_EDA/dt.eda.rpresentation.rdata') # load dt
dt.org <- dt
Data overview
head(dt)summary(dt)str(dt): shows the data structuretable(sapply(dt, class)): conclusion of all possible data types
Data overview
head(dt)
REGISTRATION_DATE STATE IS_ALUMNI_FLAG IS_US_CITIZEN_FLAG AGI AGE
1 2015-11-11 MO 0 1 10120 22
2 2015-11-19 IL 0 1 NA 38
3 2015-10-23 AL 0 1 0 28
4 2015-11-02 NC 0 1 100516 45
5 2015-11-23 LA 0 1 40994 24
6 2015-11-17 GA 0 1 33423 39
TRANSFER_CREDITS FIRST_GRADE SECOND_GRADE
1 0.00 A B
2 67.00 A A
3 0.00 A A
4 16.00 A <NA>
5 0.00 A A
6 33.67 C F
Data overview
library(knitr)
kable(head(dt)) # or use View(dt) to open the data in a excel-look window
| REGISTRATION_DATE | STATE | IS_ALUMNI_FLAG | IS_US_CITIZEN_FLAG | AGI | AGE | TRANSFER_CREDITS | FIRST_GRADE | SECOND_GRADE |
|---|---|---|---|---|---|---|---|---|
| 2015-11-11 | MO | 0 | 1 | 10120 | 22 | 0.00 | A | B |
| 2015-11-19 | IL | 0 | 1 | NA | 38 | 67.00 | A | A |
| 2015-10-23 | AL | 0 | 1 | 0 | 28 | 0.00 | A | A |
| 2015-11-02 | NC | 0 | 1 | 100516 | 45 | 16.00 | A | NA |
| 2015-11-23 | LA | 0 | 1 | 40994 | 24 | 0.00 | A | A |
| 2015-11-17 | GA | 0 | 1 | 33423 | 39 | 33.67 | C | F |
Data overview
summary(dt)
REGISTRATION_DATE STATE IS_ALUMNI_FLAG
Min. :2015-10-22 Length:8751 Min. :0.000000
1st Qu.:2015-11-10 Class :character 1st Qu.:0.000000
Median :2015-12-09 Mode :character Median :0.000000
Mean :2015-12-13 Mean :0.006856
3rd Qu.:2016-01-12 3rd Qu.:0.000000
Max. :2016-04-18 Max. :1.000000
IS_US_CITIZEN_FLAG AGI AGE TRANSFER_CREDITS
Min. :0.0000 Min. :-195061 Min. :18.00 Min. : 0.0
1st Qu.:1.0000 1st Qu.: 0 1st Qu.:25.00 1st Qu.: 0.0
Median :1.0000 Median : 13701 Median :30.00 Median : 0.0
Mean :0.9904 Mean : 22592 Mean :32.25 Mean :12.7
3rd Qu.:1.0000 3rd Qu.: 29722 3rd Qu.:37.00 3rd Qu.:21.0
Max. :1.0000 Max. :9989611 Max. :80.00 Max. :85.0
NA's :1204
FIRST_GRADE SECOND_GRADE
Length:8751 Length:8751
Class :character Class :character
Mode :character Mode :character
Data overview
str(dt) # data structure
'data.frame': 8751 obs. of 9 variables:
$ REGISTRATION_DATE : Date, format: "2015-11-11" "2015-11-19" ...
$ STATE : chr "MO" "IL" "AL" "NC" ...
$ IS_ALUMNI_FLAG : int 0 0 0 0 0 0 0 0 0 0 ...
$ IS_US_CITIZEN_FLAG: int 1 1 1 1 1 1 1 1 1 1 ...
$ AGI : num 10120 NA 0 100516 40994 ...
$ AGE : num 22 38 28 45 24 39 25 23 41 28 ...
$ TRANSFER_CREDITS : num 0 67 0 16 0 ...
$ FIRST_GRADE : chr "A" "A" "A" "A" ...
$ SECOND_GRADE : chr "B" "A" "A" NA ...
table(sapply(dt, class)) # all possible data types
character Date integer numeric
3 1 2 3
Data type conversion
Conver “flag” to character variable
x.flag <- grep('FLAG', colnames(dt), value = T, ignore.case = T)
x.flag
[1] "IS_ALUMNI_FLAG" "IS_US_CITIZEN_FLAG"
str(dt[x.flag])
'data.frame': 8751 obs. of 2 variables:
$ IS_ALUMNI_FLAG : int 0 0 0 0 0 0 0 0 0 0 ...
$ IS_US_CITIZEN_FLAG: int 1 1 1 1 1 1 1 1 1 1 ...
dt[x.flag] <- lapply(dt[x.flag], as.character) # change the x.flag columns to character
str(dt[x.flag])
'data.frame': 8751 obs. of 2 variables:
$ IS_ALUMNI_FLAG : chr "0" "0" "0" "0" ...
$ IS_US_CITIZEN_FLAG: chr "1" "1" "1" "1" ...
Data type conversion
Convert NA to 'Missing' for the categorical variables
library(dplyr)
x.cat <- sapply(dt, is.character) # check whether a varaible is character
x.cat
REGISTRATION_DATE STATE IS_ALUMNI_FLAG
FALSE TRUE TRUE
IS_US_CITIZEN_FLAG AGI AGE
TRUE FALSE FALSE
TRANSFER_CREDITS FIRST_GRADE SECOND_GRADE
FALSE TRUE TRUE
tail(dt[x.cat])
STATE IS_ALUMNI_FLAG IS_US_CITIZEN_FLAG FIRST_GRADE SECOND_GRADE
8746 GA 0 1 <NA> <NA>
8747 CA 0 1 <NA> <NA>
8748 IA 0 1 <NA> <NA>
8749 MI 0 1 <NA> <NA>
8750 SC 0 1 <NA> <NA>
8751 MO 0 1 <NA> <NA>
Data type conversion
Convert NA to 'Missing' for the categorical variables
na.idx <- is.na(dt[x.cat]) # logical output (T/F) indicating whether a record is NA
dt[x.cat][na.idx] <- 'Missing' # replace NA with 'Missing'
tail(dt[x.cat])
STATE IS_ALUMNI_FLAG IS_US_CITIZEN_FLAG FIRST_GRADE SECOND_GRADE
8746 GA 0 1 Missing Missing
8747 CA 0 1 Missing Missing
8748 IA 0 1 Missing Missing
8749 MI 0 1 Missing Missing
8750 SC 0 1 Missing Missing
8751 MO 0 1 Missing Missing
Join tables and add new variables
Add the REGION column to the dataset by STATE
# prepare the state_region table using the embedded dataset in R
state_region <- data.frame(state.abb, REGION = state.region)
state_region <- rbind(state_region, data.frame(state.abb = 'DC', REGION = 'South'))
state_region
state.abb REGION
1 AL South
2 AK West
3 AZ West
4 AR South
5 CA West
6 CO West
7 CT Northeast
8 DE South
9 FL South
10 GA South
11 HI West
12 ID West
13 IL North Central
14 IN North Central
15 IA North Central
16 KS North Central
17 KY South
18 LA South
19 ME Northeast
20 MD South
21 MA Northeast
22 MI North Central
23 MN North Central
24 MS South
25 MO North Central
26 MT West
27 NE North Central
28 NV West
29 NH Northeast
30 NJ Northeast
31 NM West
32 NY Northeast
33 NC South
34 ND North Central
35 OH North Central
36 OK South
37 OR West
38 PA Northeast
39 RI Northeast
40 SC South
41 SD North Central
42 TN South
43 TX South
44 UT West
45 VT Northeast
46 VA South
47 WA West
48 WV South
49 WI North Central
50 WY West
51 DC South
Join tables and add new variables
Add the REGION column to the dataset by STATE
dt <- left_join(dt, state_region, by = c('STATE' = 'state.abb')) # join region to dt
head(dt)
REGISTRATION_DATE STATE IS_ALUMNI_FLAG IS_US_CITIZEN_FLAG AGI AGE
1 2015-11-11 MO 0 1 10120 22
2 2015-11-19 IL 0 1 NA 38
3 2015-10-23 AL 0 1 0 28
4 2015-11-02 NC 0 1 100516 45
5 2015-11-23 LA 0 1 40994 24
6 2015-11-17 GA 0 1 33423 39
TRANSFER_CREDITS FIRST_GRADE SECOND_GRADE REGION
1 0.00 A B North Central
2 67.00 A A North Central
3 0.00 A A South
4 16.00 A Missing South
5 0.00 A A South
6 33.67 C F South
Join tables and add new variables
Add PROGRESSION_FLAG dependent on course grades
dt$PROGRESSION_FLAG <- ifelse(
dt$FIRST_GRADE %in% c('A', 'B', 'C', 'D') & dt$SECOND_GRADE %in% c('A', 'B', 'C', 'D'),
'Y', 'N') # if both courses are above D, then PROGRESSION_FLAG is Y, otherwise N.
head(dt)
REGISTRATION_DATE STATE IS_ALUMNI_FLAG IS_US_CITIZEN_FLAG AGI AGE
1 2015-11-11 MO 0 1 10120 22
2 2015-11-19 IL 0 1 NA 38
3 2015-10-23 AL 0 1 0 28
4 2015-11-02 NC 0 1 100516 45
5 2015-11-23 LA 0 1 40994 24
6 2015-11-17 GA 0 1 33423 39
TRANSFER_CREDITS FIRST_GRADE SECOND_GRADE REGION PROGRESSION_FLAG
1 0.00 A B North Central Y
2 67.00 A A North Central Y
3 0.00 A A South Y
4 16.00 A Missing South N
5 0.00 A A South Y
6 33.67 C F South N
Exclude the anomolous data
Rows containing NA in the REGION column
dt[is.na(dt$REGION), ] # show the rows with NA in the REGION column
REGISTRATION_DATE STATE IS_ALUMNI_FLAG IS_US_CITIZEN_FLAG AGI AGE
106 2015-11-18 FM 0 0 38385 27
401 2016-01-04 AE 0 1 NA 29
1301 2016-01-08 VI 0 1 NA 31
2343 2015-11-09 Missing 0 1 NA 35
2475 2016-01-07 MP 0 1 18548 49
4550 2015-10-26 MP 0 1 34256 29
4814 2015-12-03 PR 0 1 16553 27
5220 2015-11-12 Missing 0 1 NA 45
6072 2015-10-22 Missing 0 1 NA 35
6155 2016-01-13 VI 0 1 0 19
6648 2016-01-21 GU 0 1 61832 30
7370 2015-11-04 GU 0 1 26486 30
7895 2016-01-12 VI 0 1 34155 37
8005 2016-01-06 VI 0 1 700 26
TRANSFER_CREDITS FIRST_GRADE SECOND_GRADE REGION PROGRESSION_FLAG
106 0.00 A A <NA> Y
401 0.00 Missing Missing <NA> N
1301 3.00 Missing Missing <NA> N
2343 54.00 A A <NA> Y
2475 0.00 Missing Missing <NA> N
4550 30.00 C Missing <NA> N
4814 0.00 Missing Missing <NA> N
5220 69.00 A A <NA> Y
6072 32.67 C B <NA> Y
6155 0.00 Missing Missing <NA> N
6648 6.00 Missing Missing <NA> N
7370 72.00 A A <NA> Y
7895 0.00 A A <NA> Y
8005 0.00 Missing Missing <NA> N
Exclude the anomolous data
Remove the rows containing NA in the REGION column
dt <- dt[!is.na(dt$REGION), ] # use ! to exclude NA
dt[is.na(dt$REGION), ]
[1] REGISTRATION_DATE STATE IS_ALUMNI_FLAG
[4] IS_US_CITIZEN_FLAG AGI AGE
[7] TRANSFER_CREDITS FIRST_GRADE SECOND_GRADE
[10] REGION PROGRESSION_FLAG
<0 rows> (or 0-length row.names)
Select the records (rows)
Select the non-alumni student (IS_ALUMNI_FLAG == 0) with AGE less than 60
dim(dt) # dimension (number of rows and columns) of dt
[1] 8737 11
dt <- filter(dt, IS_ALUMNI_FLAG == 0 & AGE < 60)
dim(dt)
[1] 8623 11
any(dt$IS_ALUMNI_FLAG == 1) # check whether there is any unexpected value
[1] FALSE
any(dt$AGE >= 60)
[1] FALSE
Select variables (columns)
Variable with only one unique value
library(caret)
nzv(dt, saveMetrics = T) # nero-zero variation columns
freqRatio percentUnique zeroVar nzv
REGISTRATION_DATE 1.050251 1.57717732 FALSE FALSE
STATE 1.017815 0.59144149 FALSE FALSE
IS_ALUMNI_FLAG 0.000000 0.01159689 TRUE TRUE
IS_US_CITIZEN_FLAG 102.891566 0.02319378 FALSE TRUE
AGI 131.437500 56.83636785 FALSE FALSE
AGE 1.122581 0.48706947 FALSE FALSE
TRANSFER_CREDITS 33.433333 5.14902006 FALSE TRUE
FIRST_GRADE 1.560342 0.06958135 FALSE FALSE
SECOND_GRADE 2.525237 0.08117824 FALSE FALSE
REGION 2.279564 0.04638757 FALSE FALSE
PROGRESSION_FLAG 1.747929 0.02319378 FALSE FALSE
Select variables (columns)
Exclude (the first) three columns: REGISTRATION_DATE, STATE, IS_ALUMNI_FLAG
dt <- select(dt, -REGISTRATION_DATE, -STATE, -IS_ALUMNI_FLAG) # exclude columns with -
# dt <- select(dt, IS_US_CITIZEN_FLAG, AGI, AGE, TRANSFER_CREDITS, FIRST_GRADE,
# SECOND_GRADE, PROGRESSION_FLAG)
# dt <- select(dt, IS_US_CITIZEN_FLAG:PROGRESSION_FLAG)
# dt <- select(dt, 4:10)
head(dt)
IS_US_CITIZEN_FLAG AGI AGE TRANSFER_CREDITS FIRST_GRADE SECOND_GRADE
1 1 10120 22 0.00 A B
2 1 NA 38 67.00 A A
3 1 0 28 0.00 A A
4 1 100516 45 16.00 A Missing
5 1 40994 24 0.00 A A
6 1 33423 39 33.67 C F
REGION PROGRESSION_FLAG
1 North Central Y
2 North Central Y
3 South Y
4 South N
5 South Y
6 South N
Data Correlation
Continuous variable: correlation plot
library(corrplot)
x.num <- sapply(dt, is.numeric)
cor.mat <- round(cor(na.omit(dt[x.num])), 2) # calculate correlation matrix
# visualize correlation matrix
corrplot(cor.mat, type = 'lower', addCoef.col = 'black', , cl.cex = 1.5, tl.cex = 1.5)

Data Correlation
Continuous variable: matrix plot
library(car)
scatterplot.matrix(~AGI + AGE + TRANSFER_CREDITS|PROGRESSION_FLAG, data = dt,
cex.lab = 3, cex.axis=3)

Data Correlation
Categorical variable: pivot table
table(dt[, c('FIRST_GRADE', 'SECOND_GRADE')]) # pivot table
SECOND_GRADE
FIRST_GRADE A B C D F IX Missing
A 1652 434 151 49 51 2 354
B 190 199 97 41 64 0 235
C 60 85 57 34 39 0 203
D 16 33 26 14 19 0 136
F 9 13 16 9 22 0 111
Missing 74 40 17 20 37 0 4014
Data Correlation
Categorical variable: visualizing pivot table
library(ggplot2)
ggplot(dt, aes(x = FIRST_GRADE, y = SECOND_GRADE)) + # visualizing pivot table
geom_count() +
theme_bw() +
theme(text = element_text(size = 20))

Data Correlation
Generalized pairs plot
library(GGally)
ggpairs(dt, columns=c("AGE", "TRANSFER_CREDITS", "FIRST_GRADE"),
diag=list(continuous="density", discrete="bar"), axisLabels="show")

Data transformation and aggregation
Bin numerical variable
dt$AGI <- cut_number(dt$AGI, 5) # equal frequency binning into 5 groups
dt$AGE <- cut_number(dt$AGE, 5)
dt$TRANSFER_CREDITS <- cut_interval(dt$TRANSFER_CREDITS, 5) # equal width binning
head(dt)
IS_US_CITIZEN_FLAG AGI AGE TRANSFER_CREDITS
1 1 (9.08e+03,1.86e+04] [18,24] [0,17]
2 1 <NA> (33,39] (51,68]
3 1 [-1.95e+05,0] (24,28] [0,17]
4 1 (3.42e+04,9.99e+06] (39,59] [0,17]
5 1 (3.42e+04,9.99e+06] [18,24] [0,17]
6 1 (1.86e+04,3.42e+04] (33,39] (17,34]
FIRST_GRADE SECOND_GRADE REGION PROGRESSION_FLAG
1 A B North Central Y
2 A A North Central Y
3 A A South Y
4 A Missing South N
5 A A South Y
6 C F South N
Data transformation and aggregation
Wide format to long format
library(reshape2)
dt.l <- melt(dt, id.vars = 'PROGRESSION_FLAG') # wide to long format
dt.l <- select(dt.l, Variable = variable, Group = value, PROGRESSION_FLAG) # select and rename variables
head(dt.l)
Variable Group PROGRESSION_FLAG
1 IS_US_CITIZEN_FLAG 1 Y
2 IS_US_CITIZEN_FLAG 1 Y
3 IS_US_CITIZEN_FLAG 1 Y
4 IS_US_CITIZEN_FLAG 1 N
5 IS_US_CITIZEN_FLAG 1 Y
6 IS_US_CITIZEN_FLAG 1 N
tail(dt.l)
Variable Group PROGRESSION_FLAG
60356 REGION South N
60357 REGION West N
60358 REGION North Central N
60359 REGION North Central N
60360 REGION South N
60361 REGION North Central N
Data transformation and aggregation
Calculate progresssion rate
dt.group <- group_by(dt.l, Variable, Group) # group dt.l
dt.summary <- summarise(dt.group, Population = n(),
Progression_Y = sum(PROGRESSION_FLAG == 'Y'),
Progression_N = sum(PROGRESSION_FLAG == 'N'),
Progression_Rate = Progression_Y / Population)
kable(head(data.frame(dt.summary), 10))
| Variable | Group | Population | Progression_Y | Progression_N | Progression_Rate |
|---|---|---|---|---|---|
| IS_US_CITIZEN_FLAG | 0 | 83 | 44 | 39 | 0.5301205 |
| IS_US_CITIZEN_FLAG | 1 | 8540 | 3094 | 5446 | 0.3622951 |
| AGI | (0,9.08e+03] | 857 | 269 | 588 | 0.3138856 |
| AGI | (1.86e+04,3.42e+04] | 1489 | 676 | 813 | 0.4539960 |
| AGI | (3.42e+04,9.99e+06] | 1490 | 818 | 672 | 0.5489933 |
| AGI | (9.08e+03,1.86e+04] | 1490 | 495 | 995 | 0.3322148 |
| AGI | [-1.95e+05,0] | 2122 | 454 | 1668 | 0.2139491 |
| AGI | NA | 1175 | 426 | 749 | 0.3625532 |
| AGE | (24,28] | 1886 | 659 | 1227 | 0.3494168 |
| AGE | (28,33] | 1790 | 704 | 1086 | 0.3932961 |
Combining steps using pipe operation (%>%)
dt.summary.2 <- left_join(dt.org, state_region,
by = c('STATE' = 'state.abb')) %>% # join region to dt
mutate(PROGRESSION_FLAG = ifelse(
FIRST_GRADE %in% c('A', 'B', 'C', 'D') & # add PROGRESSION_FLAG
SECOND_GRADE %in% c('A', 'B', 'C', 'D'), 'Y', 'N')) %>%
filter(!is.na(REGION) & IS_ALUMNI_FLAG == 0 & AGE < 60) %>% # select rows
select(-REGISTRATION_DATE, -STATE, -IS_ALUMNI_FLAG) %>% # select columns
mutate(AGI = cut_number(AGI, 5), AGE = cut_number(AGE, 5),
TRANSFER_CREDITS = cut_interval(TRANSFER_CREDITS, 5)) %>% # bin numerical value
melt(id.vars = 'PROGRESSION_FLAG') %>% # wide to long format
select(Variable = variable, Group = value, PROGRESSION_FLAG) %>% # Rename variables
group_by(Variable, Group) %>% # group variables
summarise(Population = n(), # aggregate & summarise
Progression_Y = sum(PROGRESSION_FLAG == 'Y'),
Progression_N = sum(PROGRESSION_FLAG == 'N'),
Progression_Rate = Progression_Y / Population)
Visualization
Progression rate by variable and group
ggplot(dt.summary, aes(x = Group, y = Progression_Rate)) +
facet_wrap(~Variable, scales = 'free') +
geom_bar(stat = 'identity')

Visualization
Progression rate by variable and group
plt <- ggplot(dt.summary, aes(x = Group, y = Progression_Rate)) +
facet_wrap(~Variable, scales = 'free', nrow = 2) +
geom_bar(stat = 'identity', alpha = .5, fill = 'cornflowerblue',
aes(width = Population / nrow(dt) + .1)) +
geom_text(aes(label = paste0(round(Progression_Rate * 100), '%')),
color = 'red', size = 6) +
theme_classic() +
theme(axis.text.x = element_text(angle=25, hjust=1),
text = element_text(size = 20), axis.line.x = element_line(),
axis.line.y = element_line(), strip.text = element_text(face = 'bold'),
strip.background = element_blank())
Visualization
Progression rate by variable and group
plt

Interative visualization
library(googleVis)
Motion=gvisMotionChart(Fruits, idvar="Fruit", timevar="Year")
print(Motion, 'chart')
References
- R Presentations Instruction: https://support.rstudio.com/hc/en-us/sections/200130218-R-Presentations
- Rstudio Presentation: https://www.coursera.org/learn/data-products/lecture/9xFVF/rstudio-presenter-1-introduction-and-getting-started
- Exploratory Data Analysis: https://www.coursera.org/learn/exploratory-data-analysis/lecture/ilRAK/exploratory-graphs-part-1
- Data Structure: http://adv-r.had.co.nz/Data-structures.html
- Databases and R: http://www.unomaha.edu/mahbubulmajumder/data-science/fall-2014/lectures/20-database-mysql/20-database-mysql.html#/
- MySQL, R and Dplyr: http://www.unomaha.edu/mahbubulmajumder/data-science/fall-2014/lectures/20-database-mysql/20-database-mysql.html#/
- Shiny User Showcase: https://www.rstudio.com/products/shiny/shiny-user-showcase/
- Shiny Gallery: http://shiny.rstudio.com/gallery/
- R for Data Science: http://r4ds.had.co.nz/
- Quick list of useful R packages: https://support.rstudio.com/hc/en-us/articles/201057987-Quick-list-of-useful-R-packages
- googleVis Examples: https://cran.r-project.org/web/packages/googleVis/vignettes/googleVis_examples.html