Sannolikhetsmodeller och Distributioner
Rasmus Bååth
09/04/2014
Generativa modeller

Generativa modeller
De grundläggande processerna
Binomialmodellen


Binomialmodellen



Binomialmodellen i R
Binomialmodellen i R
Vad är parametriska sannolikhetsfördelningar bra till?
Uniform-modellen

Uniform-modellen

Uniform-modellen i R
Uniform-modellen i R
Exponential-modellen


Exponential-modellen

Exponential-modellen i R

Poisson-modellen

Poisson-modellen

Poisson-modellen i R

Normalmodellen

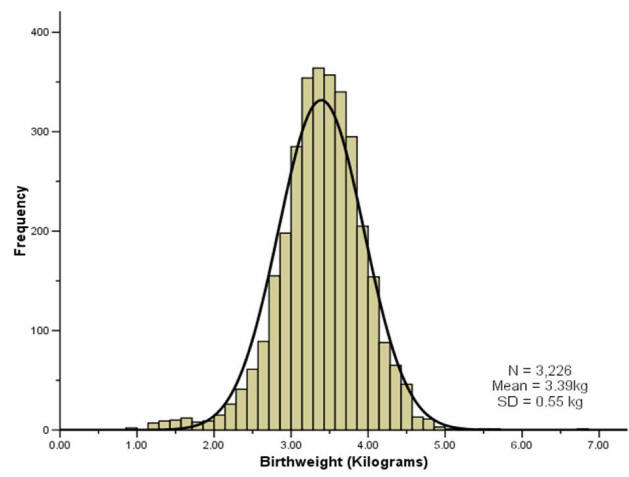

Vad leder till normalfördelningen?
Normalmodellen

Normalmodellen i R

Inget är normalfördelat
Parametriska fördelningar är toppen för att generera låtsasdata.
Exempel på datasimulering

I R
Använd do för att upprepa "experimentet"
Ett CI för vårt "experiment"
Exempel på ännu en datasimulering

Två nya kommandon
I R
