Reducción de dimensinalidad - PCA
Juan Agustín Chanqueo Cariqueo
2026-06-30
2. Reducción de Dimensionalidad
2.1. Modelos de Machine Learning No-Supervisados
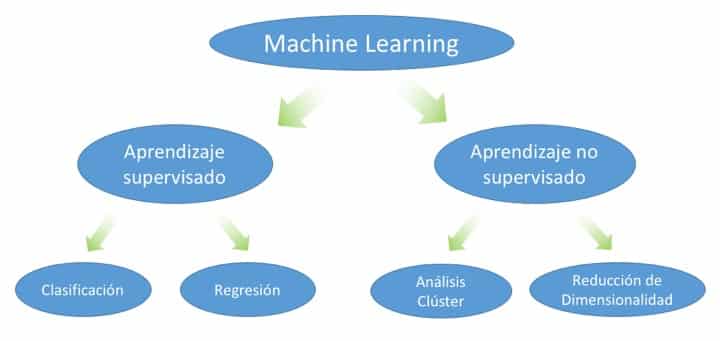
La mayoría de los métodos de aprendizaje automático pertenecen al aprendizaje supervisado, donde el objetivo es predecir una variable de respuesta Y a partir de un conjunto de características (X1,X2,…,Xp) observadas en n instancias. Matemáticamente, se define como:
#𝒀=(𝑿𝟏, 𝑿𝟐,…𝑿𝒑)+𝜺Donde:
f es una función desconocida que relaciona las características Xi con la respuesta Y
ϵ representa el ruido o error aleatorio, es decir, la variabilidad en Y que no puede explicarse por f(X)
Sin embargo, en aprendizaje no supervisado, no disponemos de la variable respuesta Y, por lo que el objetivo cambia. Ahora, buscamos descubrir estructuras o patrones en los datos X1,X2,…,Xp sin un criterio explícito de predicción.
#𝒙∈ℝ^(𝒏×𝒑)Donde:
n es el número de observaciones (filas de la matriz).
p es el número de características (columnas de la matriz).
Preguntas clave en aprendizaje no supervisado:
¿Existe una forma óptima de visualizar los datos en un espacio de menor dimensión?
¿Podemos identificar subgrupos dentro de las observaciones o entre las variables?
¿Podemos reducir la complejidad de los datos preservando su estructura más relevante?
¿Existen puntos de datos que no siguen el comportamiento general del conjunto?
2.2. ¿Qué es la reducción de la dimensionalidad?
La reducción de la dimensionalidad es un método para representar un conjunto de datos utilizando un menor número de características (dimensiones) sin perder las propiedades significativas de los datos originales. Esto equivale a eliminar características irrelevantes o redundantes, o simplemente datos ruidosos, para crear un modelo con un menor número de variables.

Aunque los métodos de reducción de la dimensionalidad difieren en su funcionamiento, todos transforman espacios de alta dimensión en espacios de baja dimensión mediante la extracción o la combinación de variables. Se favorece la compresión, eliminación de redundancia del conjunto de datos y permite mejorar procesos de clasificación y visualización de los datos a un menor costo computacional.
2.3. ¿Por qué utilizar la reducción de la dimensionalidad?
Los conjuntos de datos de alta dimensión plantean una serie de preocupaciones prácticas para los algoritmos de machine learning, como mayor tiempo de cálculo, espacio de almacenamiento para big data, etc. Pero la mayor preocupación es quizá la disminución de la precisión en los modelos predictivos. Los modelos estadísticos y de machine learning entrenados en conjuntos de datos de alta dimensión suelen generalizar mal.


Resulta difícil visualizar un conjunto de datos que contiene un gran número de características.
Un número muy elevado de características para cada instancia de entrenamiento puede hacer que el entrenamiento sea extremadamente lento.
La mayoría de los puntos en un hipercubo de alta dimensión están muy cerca del borde y corren el riesgo de ser muy dispersos, lo que hace que las predicciones sean mucho menos fiables que en dimensiones inferiores.
2.3.1. Ventajas de reducir la dimensionalidad
Reducir las dimensiones de las características implica una reducción del espacio requerido para almacenar el conjunto de datos, porque este también se reduce.
El tiempo de entrenamiento de modelos es menor para dimensiones reducidas.
Se facilita la visualización de datos más rápidamente gracias a la reducción de características del conjunto de datos.
Desaparecen las características redundantes en el ámbito de la multicolinealidad.
2.3.2. Desventajas de reducir la dimensionalidad
Se pueden perder algunos datos debido a la reducción de la dimensionalidad.
En la técnica de reducción de dimensionalidad de PCA, en ocasiones no se conocen los componentes principales que se deben considerar.
No obstante, es una técnica que requiere conocimiento y un equipo adecuado para realizarse, pues pueden eliminarse más datos de los debidos y generar un modelo erróneo.
2.4. Métodos de reducción de la dimensionalidad
Los métodos de reducción de dimensionalidad son algoritmos que mapean el conjunto de los datos a subespacios derivados del espacio original, de menor dimensión, que permiten hacer una descripción de los datos a un menor costo.
Entre los métodos más básicos de reducción de dimensionalidad, el más eficiente consiste en identificar y seleccionar un subconjunto de características que son muy relevantes para la variable objetivo. En la selección de características, principalmente, se realizan dos cosas: mantener las características que está altamente relacionadas con la variable objetivo y contribuir más a la variación del conjunto de datos
Hay muchas maneras de lograr la reducción de dimensionalidad, pero la mayoría de las técnicas se dividen en 3 clases:
Eliminación de características: reducimos el espacio de características eliminando algunas. Las ventajas de este método incluyen la simplicidad y la facilidad de mantenimiento. Además, hemos eliminado cualquier beneficio que pudieran aportar las variables eliminadas. Sin embargo, esto tiene una desventaja, ya que no obtenemos información de las características que se han eliminado.
Selección de características: Aplicamos algunas pruebas estadísticas para clasificarlas según su importancia y luego seleccionamos un subconjunto de características para nuestro trabajo. Esto nuevamente sufre de pérdida de información y es menos estable ya que diferentes pruebas dan diferentes puntuaciones de importancia a las características.
Extracción de características: Combina nuestras variables de entrada de una manera específica, lo que nos permite descartar las variables “menos importantes” y conservar las partes más valiosas de todas las variables. Creamos nuevas características independientes, donde cada nueva característica independiente es una combinación de cada una de las características independientes anteriores. Estas técnicas se pueden dividir en técnicas de reducción de dimensionalidad lineales (PCA, SVD) y no lineales (t-SNE).
2.5. Análisis de componentes principales (PCA)
El Análisis de Componentes Principales (PCA, por sus siglas en inglés) es una técnica de reducción de dimensionalidad que transforma los datos en un nuevo sistema de coordenadas, preservando la mayor cantidad posible de variabilidad en los datos originales. En otras palabras, su objetivo es encontrar una representación de menor dimensión de los datos que capture la máxima varianza posible, mediante combinaciones lineales ortogonales de las variables originales.

Matemáticamente, dados los datos centrados X, buscamos una transformación lineal Z tal que: Z=XW
Donde:
Z representa los datos transformados en el nuevo espacio de componentes principales.
W es la matriz de componentes principales, cuyas columnas son los autovectores de la matriz de covarianza de X
2.5.1. Conceptos clave en PCA:
Reducción de dimensionalidad: El proceso de representar datos en un espacio de menor dimensión mientras se conserva la mayor cantidad posible de información.
Autovectores y autovalores: Los autovectores de la matriz de covarianza indican las direcciones principales de variabilidad en los datos, mientras que los autovalores indican la magnitud de esa variabilidad.
Proporción de varianza explicada: La cantidad de información conservada en cada componente principal.
2.5.2. ¿Qué hace exactamente PCA?
Geométricamente el PCA rota el sistema de coordenadas original para que:
El primer eje (componente) esté alineado con la dirección de mayor dispersión de los datos.
El segundo eje esté en la dirección ortogonal siguiente de mayor dispersión, y así sucesivamente.
Estadísticamente el PCA:
Transforma variables correlacionadas en nuevas variables no correlacionadas.
Cada nueva variable es una combinación lineal de las originales: Z1=a11X1+a12X2+⋯+a1pXp
2.6. Pasos para realizar un PCA
Paso 1: Estandarización
La razón por la que la estandarización es tan necesaria antes de realizar el PCA es que este análisis es muy sensible a las varianzas. Es decir, si existen grandes diferencias entre las escalas (rangos) de las variables originales, aquellas con escalas mayores dominarán sobre aquellas con escalas menores. La estandarización de datos es la transformación de las características mediante la resta de la media y la división por la desviación estándar.

Paso 2: Calcular la matriz de covarianza
Este paso tiene como objetivo comprender cómo varían las variables originales del conjunto de datos de entrada con respecto a la media entre sí, o dicho de otro modo, ver si existe alguna relación entre ellas. Porque a veces, las variables originales están altamente correlacionadas de tal manera que contienen información redundante. Por lo tanto, para identificar estas correlaciones, calculamos la matriz de covarianza.

Matriz de covarianza

El signo de las variables en la matriz nos indica si las combinaciones están correlacionadas:
Positivo (las variables originales están correlacionadas y aumentan o disminuyen simultáneamente)
Negativo (las variables originales no están correlacionadas; es decir, una disminuye mientras la otra aumenta)
Cero (las variables originales no están relacionadas entre sí)
Paso 3: Calculo de los autovalores y autovectores de la matriz de covarianza
Aquí, calculamos los autovectores (componentes principales) y los autovalores de la matriz de covarianza. Como autovectores, los componentes principales representan las direcciones de máxima varianza en los datos. Los autovalores representan la cantidad de varianza en cada componente. La clasificación de los autovectores por autovalor identifica el orden de los componentes principales. El PCA busca preservar las distancias euclidianas entre los puntos tanto como sea posible al reducir la dimensionalidad.
Paso 4: Selección de componentes principales
Aquí decidimos qué componentes conservar y cuáles descartar. Los componentes con valores propios bajos generalmente no serán tan significativos. Los gráficos de sedimentación suelen representar la proporción de la varianza total explicada y la proporción acumulada de la varianza. Estas métricas ayudan a determinar el número óptimo de componentes a conservar. El punto en el que el eje Y de los valores propios o la varianza total explicada crea un “codo” generalmente indicará cuántos componentes de PCA queremos incluir.
Ordenación de pares propios
Para decidir qué vector(es) propio(s) se pueden descartar sin perder demasiada información, es necesario examinar los valores propios correspondientes: los vectores propios con los valores propios más bajos contienen la menor cantidad de información sobre la distribución de los datos; estos son los que se pueden descartar.
El enfoque común consiste en ordenar los valores propios de mayor a menor.
Varianza explicada
Para cuantos componentes principales se van a seleccionar en el nuevo subpespacio de caracteristicas se puede utilizar la denominada varianza explicada. La varianza explicada nos indica cuánta información (varianza) se puede atribuir a cada uno de los componentes principales. Se puede calcular a partir de los valores propios.
Paso 5: Transformar los datos al nuevo sistema de coordenadas
Matriz de proyección
La matriz de proyección se utiliza para transformar los datos de entrada (X) en el nuevo subespacio de características. La matriz de proyección es una matriz de los k autovectores más significativos concatenados.
Ejemplo práctico de PCA
Ejercicio práctico: PCA aplicado a proyectos de construcción 1. Problema de ingeniería en construcción
Supongamos que una empresa constructora quiere comparar distintos proyectos de edificación. Para cada proyecto se registran varios indicadores:
| Variable | Descripción |
|---|---|
costo_m2 |
Costo de construcción por m² |
plazo_dias |
Duración total del proyecto |
residuos_ton |
Residuos generados en toneladas |
co2_ton |
Emisiones de CO₂ asociadas al proyecto |
energia_kwh_m2 |
Consumo energético por m² |
agua_m3 |
Consumo de agua |
accidentes |
Número de accidentes en obra |
retrabajo_pct |
Porcentaje de retrabajo |
productividad_m2_dia |
Productividad de construcción |
material_reciclado_pct |
Porcentaje de material reciclado utilizado |
El problema es que hay muchas variables, algunas relacionadas entre sí. Por ejemplo, proyectos con mayor plazo pueden tener mayor costo, más residuos y más emisiones. Entonces, el PCA permite reducir estas 10 variables a 2 o 3 componentes principales que resumen la mayor parte de la información.
- Código completo en R Paso 1: Crear una base de datos simulada
# Limpiar entorno
rm(list = ls())
# Fijar semilla para que los resultados sean reproducibles
set.seed(123)
# Número de proyectos
n <- 40
# Crear variables latentes para simular relaciones reales
tamano_proyecto <- rnorm(n, mean = 0, sd = 1)
gestion_obra <- rnorm(n, mean = 0, sd = 1)
sustentabilidad <- rnorm(n, mean = 0, sd = 1)
# Crear base de datos simulada
datos <- data.frame(
proyecto = paste0("Obra_", 1:n),
costo_m2 = 650000 + 90000*tamano_proyecto - 40000*gestion_obra + rnorm(n, 0, 30000),
plazo_dias = 180 + 35*tamano_proyecto - 20*gestion_obra + rnorm(n, 0, 15),
residuos_ton = 120 + 45*tamano_proyecto - 25*sustentabilidad + rnorm(n, 0, 12),
co2_ton = 300 + 80*tamano_proyecto - 60*sustentabilidad + rnorm(n, 0, 25),
energia_kwh_m2 = 95 + 18*tamano_proyecto - 15*sustentabilidad + rnorm(n, 0, 6),
agua_m3 = 800 + 150*tamano_proyecto - 80*sustentabilidad + rnorm(n, 0, 60),
accidentes = round(4 + 1.5*tamano_proyecto - 1.2*gestion_obra + rnorm(n, 0, 1)),
retrabajo_pct = 8 + 2*tamano_proyecto - 2.5*gestion_obra + rnorm(n, 0, 1),
productividad_m2_dia = 45 - 6*tamano_proyecto + 8*gestion_obra + rnorm(n, 0, 3),
material_reciclado_pct = 18 + 12*sustentabilidad + rnorm(n, 0, 5)
)
# Evitar valores negativos en accidentes y material reciclado
datos$accidentes[datos$accidentes < 0] <- 0
datos$material_reciclado_pct[datos$material_reciclado_pct < 0] <- 0
# Ver primeras filas
head(datos)## proyecto costo_m2 plazo_dias residuos_ton co2_ton energia_kwh_m2 agua_m3
## 1 Obra_1 630874.9 190.0682 121.0202 235.1005 74.82012 729.7133
## 2 Obra_2 609176.5 160.3645 115.7590 245.9140 89.49657 807.7375
## 3 Obra_3 826182.9 240.9604 196.2266 484.3378 130.93281 983.1326
## 4 Obra_4 561904.8 187.7043 113.5818 238.5455 85.00959 798.6754
## 5 Obra_5 668633.3 154.1130 126.3580 319.0959 101.34334 805.6573
## 6 Obra_6 829721.7 266.9629 183.1684 464.8573 121.69867 1071.7419
## accidentes retrabajo_pct productividad_m2_dia material_reciclado_pct
## 1 4 8.542260 39.08206 18.17142
## 2 5 6.890787 46.08203 24.19365
## 3 8 13.646159 27.50429 20.19315
## 4 3 2.689785 61.32893 26.33911
## 5 4 5.909366 51.95263 18.91837
## 6 8 12.587355 26.22070 25.87568Aquí se creó una base de datos ficticia con 40 proyectos de construcción. Las variables fueron simuladas para que tengan cierta lógica: proyectos más grandes tienden a tener más costo, plazo, residuos, emisiones y consumo de recursos. También se incluyeron variables asociadas a gestión, como accidentes, retrabajo y productividad, además de una variable ambiental, como porcentaje de material reciclado.
- Seleccionar solo variables numéricas
# Seleccionar variables numéricas para el PCA
datos_pca <- datos[, c(
"costo_m2",
"plazo_dias",
"residuos_ton",
"co2_ton",
"energia_kwh_m2",
"agua_m3",
"accidentes",
"retrabajo_pct",
"productividad_m2_dia",
"material_reciclado_pct"
)]
datos_pca$residuos_ton[datos_pca$residuos_ton < 0] <- 0
# Revisar resumen estadístico
summary(datos_pca)## costo_m2 plazo_dias residuos_ton co2_ton
## Min. :470129 Min. :104.1 Min. : 0.0 Min. : 66.48
## 1st Qu.:578197 1st Qu.:154.1 1st Qu.:101.2 1st Qu.:242.76
## Median :653532 Median :188.1 Median :123.2 Median :314.12
## Mean :651160 Mean :182.0 Mean :122.4 Mean :305.47
## 3rd Qu.:717782 3rd Qu.:209.2 3rd Qu.:143.7 3rd Qu.:350.54
## Max. :829722 Max. :267.0 Max. :235.5 Max. :485.79
## energia_kwh_m2 agua_m3 accidentes retrabajo_pct
## Min. : 28.51 Min. : 370.4 Min. :0 Min. : 2.690
## 1st Qu.: 82.62 1st Qu.: 727.7 1st Qu.:3 1st Qu.: 5.866
## Median : 99.73 Median : 804.7 Median :4 Median : 8.364
## Mean : 96.76 Mean : 805.4 Mean :4 Mean : 8.104
## 3rd Qu.:109.48 3rd Qu.: 946.9 3rd Qu.:5 3rd Qu.:10.321
## Max. :136.57 Max. :1071.7 Max. :8 Max. :13.646
## productividad_m2_dia material_reciclado_pct
## Min. :26.22 Min. : 0.00
## 1st Qu.:39.81 1st Qu.:10.07
## Median :45.01 Median :18.49
## Mean :45.07 Mean :18.41
## 3rd Qu.:49.77 3rd Qu.:26.35
## Max. :61.33 Max. :45.16El PCA solo se aplica a variables numéricas. Por eso se elimina la variable proyecto, ya que es solo un identificador. El resumen estadístico permite observar las escalas de cada variable. Por ejemplo, costo_m2 está en cientos de miles, mientras que retrabajo_pct está en porcentajes. Esto es importante porque si no se estandarizan los datos, las variables con valores más grandes dominarían el análisis.
- Estandarizar los datos
# Estandarizar variables
datos_escalados <- scale(datos_pca)
# Revisar que la media sea aproximadamente 0
round(colMeans(datos_escalados), 2)## costo_m2 plazo_dias residuos_ton
## 0 0 0
## co2_ton energia_kwh_m2 agua_m3
## 0 0 0
## accidentes retrabajo_pct productividad_m2_dia
## 0 0 0
## material_reciclado_pct
## 0# Revisar que la desviación estándar sea aproximadamente 1
apply(datos_escalados, 2, sd)## costo_m2 plazo_dias residuos_ton
## 1 1 1
## co2_ton energia_kwh_m2 agua_m3
## 1 1 1
## accidentes retrabajo_pct productividad_m2_dia
## 1 1 1
## material_reciclado_pct
## 1La estandarización transforma todas las variables para que tengan media 0 y desviación estándar 1. Esto es fundamental porque las variables están en distintas unidades: pesos, días, toneladas, porcentajes, metros cúbicos, etc.
Sin estandarizar, el PCA le daría más importancia a variables con números grandes, como costo_m2 o agua_m3, aunque no necesariamente sean más importantes desde el punto de vista técnico.
- Revisar covarianzas entre variables
# Matriz de correlación
covarianzas <- cov(datos_escalados)
# Mostrar matriz redondeada
round(covarianzas, 2)## costo_m2 plazo_dias residuos_ton co2_ton energia_kwh_m2
## costo_m2 1.00 0.87 0.75 0.73 0.71
## plazo_dias 0.87 1.00 0.66 0.65 0.59
## residuos_ton 0.75 0.66 1.00 0.94 0.92
## co2_ton 0.73 0.65 0.94 1.00 0.92
## energia_kwh_m2 0.71 0.59 0.92 0.92 1.00
## agua_m3 0.64 0.64 0.88 0.86 0.85
## accidentes 0.78 0.82 0.58 0.61 0.50
## retrabajo_pct 0.70 0.70 0.32 0.39 0.28
## productividad_m2_dia -0.72 -0.72 -0.43 -0.47 -0.34
## material_reciclado_pct 0.05 0.14 -0.42 -0.49 -0.47
## agua_m3 accidentes retrabajo_pct productividad_m2_dia
## costo_m2 0.64 0.78 0.70 -0.72
## plazo_dias 0.64 0.82 0.70 -0.72
## residuos_ton 0.88 0.58 0.32 -0.43
## co2_ton 0.86 0.61 0.39 -0.47
## energia_kwh_m2 0.85 0.50 0.28 -0.34
## agua_m3 1.00 0.60 0.31 -0.34
## accidentes 0.60 1.00 0.69 -0.70
## retrabajo_pct 0.31 0.69 1.00 -0.87
## productividad_m2_dia -0.34 -0.70 -0.87 1.00
## material_reciclado_pct -0.41 0.18 0.13 -0.10
## material_reciclado_pct
## costo_m2 0.05
## plazo_dias 0.14
## residuos_ton -0.42
## co2_ton -0.49
## energia_kwh_m2 -0.47
## agua_m3 -0.41
## accidentes 0.18
## retrabajo_pct 0.13
## productividad_m2_dia -0.10
## material_reciclado_pct 1.00# Instalar si no tienes el paquete
# install.packages("corrplot")
library(corrplot)## corrplot 0.95 loadedcorrplot(covarianzas, method = "color", type = "upper", tl.cex = 0.8)
El PCA funciona mejor cuando existen variables correlacionadas entre sí. Por ejemplo, es esperable que costo_m2, plazo_dias, residuos_ton, co2_ton, energia_kwh_m2 y agua_m3 estén positivamente relacionadas, porque todas aumentan en proyectos más grandes o menos eficientes.
También es esperable que productividad_m2_dia tenga correlación negativa con variables como plazo_dias, retrabajo_pct o accidentes, ya que una obra más productiva suele tener mejor desempeño operacional.
- Aplicar PCA con prcomp()
# Aplicar PCA
pca_resultado <- prcomp(datos_escalados, center = TRUE, scale. = TRUE)
# Resumen del PCA
summary(pca_resultado)## Importance of components:
## PC1 PC2 PC3 PC4 PC5 PC6 PC7
## Standard deviation 2.5094 1.4758 0.81261 0.52017 0.41189 0.37171 0.33901
## Proportion of Variance 0.6297 0.2178 0.06603 0.02706 0.01697 0.01382 0.01149
## Cumulative Proportion 0.6297 0.8475 0.91352 0.94058 0.95754 0.97136 0.98285
## PC8 PC9 PC10
## Standard deviation 0.27184 0.24606 0.19249
## Proportion of Variance 0.00739 0.00605 0.00371
## Cumulative Proportion 0.99024 0.99629 1.00000La función prcomp() calcula los componentes principales. Cada componente principal es una combinación lineal de las variables originales.
El resultado más importante del summary() es la proporción de varianza explicada por cada componente.
El PC1 explica aproximadamente el 62,97% de la variabilidad total de los datos. El PC2 explica un 21,78% adicional. En conjunto, PC1 y PC2 explican cerca del 84,75% de la información original. Por lo tanto, se puede reducir la base desde 10 variables originales a 2 componentes principales, conservando gran parte de la información.
- Paso 3: Calcular de los autovalores y autovectores de la matriz de covarianza
# Calcular autovalores y autovectores
eigen_pca <- eigen(covarianzas)
# Autovalores
autovalores <- eigen_pca$values
autovalores## [1] 6.29689054 2.17795255 0.66033587 0.27057306 0.16965061 0.13816874
## [7] 0.11493088 0.07389729 0.06054765 0.03705283- Selección de componentes principales
Ver la varianza explicada y elegir cuántos PC conservar
En este paso se evalúa cuánta información conserva cada componente principal. Esto permite decidir cuántas componentes usar para reducir la dimensionalidad de la base de datos.
# Varianza de cada componente principal
varianza <- pca_resultado$sdev^2
# Proporción de varianza explicada por cada componente
prop_varianza <- varianza / sum(varianza)
# Varianza acumulada
varianza_acumulada <- cumsum(prop_varianza)
# Crear tabla resumen
tabla_varianza <- data.frame(
Componente = paste0("PC", 1:length(varianza)),
Autovalor = round(varianza, 3),
Varianza_Explicada = round(prop_varianza, 3),
Varianza_Explicada_Porcentaje = round(prop_varianza * 100, 2),
Varianza_Acumulada = round(varianza_acumulada, 3)
)
tabla_varianza## Componente Autovalor Varianza_Explicada Varianza_Explicada_Porcentaje
## 1 PC1 6.297 0.630 62.97
## 2 PC2 2.178 0.218 21.78
## 3 PC3 0.660 0.066 6.60
## 4 PC4 0.271 0.027 2.71
## 5 PC5 0.170 0.017 1.70
## 6 PC6 0.138 0.014 1.38
## 7 PC7 0.115 0.011 1.15
## 8 PC8 0.074 0.007 0.74
## 9 PC9 0.061 0.006 0.61
## 10 PC10 0.037 0.004 0.37
## Varianza_Acumulada
## 1 0.630
## 2 0.847
## 3 0.914
## 4 0.941
## 5 0.958
## 6 0.971
## 7 0.983
## 8 0.990
## 9 0.996
## 10 1.000el autovalor indica cuánta varianza explica cada componente principal. Entonces, PC1 explica el 63% de la variabilidad, PC2 explica el 21,8% adicional, y juntos explican el 84.80% de la información original
Método 1: elección por varianza acumulada
Este método consiste en conservar el menor número de componentes que alcance un umbral mínimo de varianza acumulada. Habitualmente se usa un valor entre 70% y 80%.
# Definir umbral de varianza acumulada
umbral <- 0.80
# Número mínimo de componentes que alcanza el umbral
n_pc_acumulada <- which(varianza_acumulada >= umbral)[1]
n_pc_acumulada## [1] 2plot(
varianza_acumulada,
type = "b",
pch = 19,
xlab = "Número de componentes principales",
ylab = "Varianza acumulada",
main = "Elección de componentes por varianza acumulada",
ylim = c(0, 1)
)
abline(h = 0.80, lty = 2)
text(
x = n_pc_acumulada,
y = varianza_acumulada[n_pc_acumulada],
labels = paste0("PC", n_pc_acumulada),
pos = 4
)
Método 2: criterio de Kaiser El criterio de Kaiser conserva solo los componentes cuyo autovalor sea mayor que 1.
Esto se usa principalmente cuando el PCA se hace con variables estandarizadas. Como cada variable original estandarizada tiene varianza igual a 1, un componente con autovalor mayor que 1 explica más información que una variable original individual.
# Componentes seleccionadas por criterio de Kaiser
n_pc_kaiser <- sum(varianza > 1)
n_pc_kaiser## [1] 2cat("Según el criterio de Kaiser, se deben conservar",
n_pc_kaiser,
"componentes principales, porque tienen autovalores mayores que 1.")## Según el criterio de Kaiser, se deben conservar 2 componentes principales, porque tienen autovalores mayores que 1.plot(
varianza,
type = "b",
pch = 19,
xlab = "Componente principal",
ylab = "Autovalor",
main = "Criterio de Kaiser"
)
abline(h = 1, lty = 2)
La elección del número de componentes puede variar según el criterio utilizado. El método de varianza acumulada busca conservar una proporción mínima de información, por ejemplo 80%. En cambio, el criterio de Kaiser conserva solamente las componentes con autovalores mayores que 1.
Para este ejercicio, si ambos métodos entregan resultados similares, la decisión es más clara. Por ejemplo, si ambos sugieren conservar 2 o 3 componentes, se puede justificar que el PCA reduce la base desde 10 variables originales a 2 o 3 dimensiones principales.
Si los criterios no coinciden, para un análisis aplicado en ingeniería suele ser recomendable priorizar la varianza acumulada, porque permite asegurar explícitamente cuánta información se está conservando.
- Extraer los scores de los proyectos
# Scores de cada proyecto en las componentes principales
scores <- as.data.frame(pca_resultado$x)
# Agregar identificador del proyecto
scores$proyecto <- datos$proyecto
# Ver primeras filas
head(scores)## PC1 PC2 PC3 PC4 PC5 PC6
## 1 -0.5768733 0.9367197 -0.5484190 0.18455225 -0.04379766 0.7386222
## 2 -0.7795994 0.3403220 0.4868743 0.62774936 -0.45769931 -0.1414707
## 3 5.2253275 0.9666130 -0.1481392 -0.01193941 -0.53438714 -0.3561000
## 4 -2.0639167 -0.7476366 1.8831987 0.24116099 0.35871677 0.6479269
## 5 -0.4571368 -0.7898255 0.6269686 -0.13110781 -0.41393326 -0.5630905
## 6 5.2528629 1.4482534 0.4670769 0.24293147 -0.12641849 0.3645589
## PC7 PC8 PC9 PC10 proyecto
## 1 -0.09211908 -0.53904294 -1.692156e-02 0.3134980 Obra_1
## 2 0.38953485 -0.21190725 2.041398e-01 0.3042555 Obra_2
## 3 -0.03501410 0.28263972 -2.083613e-01 0.0434923 Obra_3
## 4 -0.30672568 0.02691849 -9.933932e-02 0.1668566 Obra_4
## 5 0.05153673 -0.24951720 1.060695e-05 -0.1640554 Obra_5
## 6 0.03678524 0.21058605 4.436915e-02 -0.3332583 Obra_6Los scores indican la posición de cada proyecto en las nuevas componentes principales. En vez de describir cada obra con 10 variables originales, ahora cada obra puede describirse con 2 componentes.
- Crear biplot del PCA
# Biplot base R
biplot(pca_resultado, scale = 0)
# Instalar si no tienes el paquete
# install.packages("factoextra")
library(factoextra)## Cargando paquete requerido: ggplot2## Welcome to factoextra!## Want to learn more? See two factoextra-related books at https://www.datanovia.com/en/product/practical-guide-to-principal-component-methods-in-r/fviz_pca_var(
pca_resultado,
repel = TRUE,
col.var = "contrib",
title = "Variables en el PCA"
)
fviz_pca_biplot(
pca_resultado,
repel = TRUE,
col.var = "black",
col.ind = "gray40",
title = "Biplot PCA - Proyectos de construcción"
)
El biplot del PCA permite visualizar simultáneamente las observaciones y las variables originales en el espacio formado por las dos primeras componentes principales. Dado que PC1 y PC2 explican conjuntamente el 84,75% de la varianza total, la representación bidimensional conserva una proporción importante de la información original.
- Cómo se leen los ejes
- El eje horizontal es Dim1 o PC1: separa proyectos de alto impacto/costo/plazo/consumo frente a proyectos más productivos.
- El eje vertical es Dim2: representa una dimensión secundaria asociada al contraste entre el uso de material reciclado y ciertos indicadores operacionales, frente a variables de consumo de recursos e impacto ambiental.
- Cómo se interpreta la dirección de las flechas: Las flechas que apuntan en una dirección similar indican variables positivamente correlacionadas.
Interpretación del bixplot
En el eje PC1 se observa que variables como costo por metro cuadrado, plazo de ejecución, residuos generados, emisiones de CO₂, consumo energético, consumo de agua, accidentabilidad y retrabajo se orientan en una dirección similar, lo que confirma la correlación positiva entre estos indicadores. En sentido contrario se ubica la productividad, indicando que los proyectos más productivos tienden a presentar menores costos, menores plazos, menor retrabajo y menor accidentabilidad. Por ello, PC1 puede interpretarse como una dimensión asociada a la intensidad, impacto y desempeño global del proyecto.
Por otra parte, PC2 está influenciado principalmente por el porcentaje de material reciclado, el cual se separa parcialmente del grupo de variables asociadas al impacto ambiental y operativo. Esta componente permite diferenciar proyectos según patrones secundarios de sustentabilidad y desempeño operacional.
En conjunto, el biplot evidencia que el PCA permite reducir las diez variables originales a dos componentes principales, facilitando la comparación visual entre proyectos y la identificación de obras con comportamientos similares o atípicos.
Ejemplo: El proyecto 20 se ubica en el cuadrante inferior izquierdo del biplot, con valores negativos tanto en Dim1 como en Dim2. Su posición se encuentra próxima a la dirección de la variable productividad_m2_dia y en sentido opuesto a variables como costo_m2, plazo_dias, accidentabilidad, retrabajo, residuos, emisiones de CO₂, consumo energético y consumo de agua. Esto sugiere que el proyecto 20 presenta un perfil asociado a mayor productividad y menor intensidad de recursos e impactos en comparación con los proyectos ubicados hacia el sector positivo de Dim1. Por lo tanto, dentro del conjunto analizado, puede interpretarse como un proyecto relativamente más eficiente desde el punto de vista operativo.
- Graficar proyectos usando solo PC1 y PC2
plot(
scores$PC1,
scores$PC2,
pch = 19,
xlab = "PC1",
ylab = "PC2",
main = "Proyectos representados con dos componentes principales"
)
text(
scores$PC1,
scores$PC2,
labels = scores$proyecto,
pos = 3,
cex = 0.7
)
abline(h = 0, v = 0, lty = 2)
Este gráfico permite visualizar los proyectos en solo dos dimensiones. Aunque originalmente había 10 variables, ahora se puede observar la estructura general de los datos usando PC1 y PC2.
Por ejemplo:
Proyectos hacia la derecha: mayor magnitud, costo, plazo e impacto. Proyectos hacia la izquierda: menor magnitud e impacto. Proyectos hacia arriba: mejor desempeño en gestión o sustentabilidad, según las cargas del PC2. Proyectos hacia abajo: menor desempeño relativo.
Esto permite comparar obras, detectar grupos similares y reconocer proyectos atípicos.
- Crear una base de datos reducida
# Crear base reducida con las dos primeras componentes
datos_reducidos <- data.frame(
proyecto = datos$proyecto,
PC1 = scores$PC1,
PC2 = scores$PC2
)
head(datos_reducidos)## proyecto PC1 PC2
## 1 Obra_1 -0.5768733 0.9367197
## 2 Obra_2 -0.7795994 0.3403220
## 3 Obra_3 5.2253275 0.9666130
## 4 Obra_4 -2.0639167 -0.7476366
## 5 Obra_5 -0.4571368 -0.7898255
## 6 Obra_6 5.2528629 1.4482534Esta nueva base de datos tiene solo tres columnas: el nombre del proyecto, PC1 y PC2. Es decir, se redujo la dimensionalidad desde 10 variables originales a 2 componentes principales.
Esto es útil porque simplifica el análisis sin perder demasiada información. Por ejemplo, esta base reducida podría usarse luego para clustering, análisis comparativo, detección de proyectos atípicos o visualización.
- Comparar dimensionalidad original vs reducida
# Dimensión original
dim(datos_pca)## [1] 40 10# Dimensión reducida
dim(datos_reducidos)## [1] 40 3La base original tenía 40 filas y 10 variables numéricas. Luego del PCA, se obtuvo una base con 40 filas y 2 componentes principales.
Si esas dos componentes explican, por ejemplo, entre 70% y 80% de la varianza total, entonces se logró una reducción importante de dimensionalidad manteniendo gran parte de la información.
- Interpretación final del ejercicio
El PCA permitió transformar una base de datos con múltiples indicadores de proyectos de construcción en un número menor de componentes principales. En vez de analizar por separado costo, plazo, residuos, emisiones, energía, agua, accidentes, retrabajo, productividad y uso de material reciclado, se puede resumir la información en dos dimensiones principales.
En este caso, el PC1 probablemente representa una dimensión asociada a la magnitud e impacto del proyecto, ya que agrupa variables como costo, plazo, residuos, emisiones, consumo energético y consumo de agua. Un proyecto con PC1 alto sería una obra más intensiva en recursos, más costosa y con mayor impacto ambiental.
El PC2 puede representar una dimensión asociada a la gestión, eficiencia y sustentabilidad, dependiendo de las cargas obtenidas. Si productividad y material reciclado se relacionan positivamente con PC2, mientras que accidentes y retrabajo se relacionan negativamente, entonces valores altos de PC2 representarían proyectos con mejor desempeño operativo y ambiental.
La reducción de dimensionalidad se logra porque las 10 variables originales se reemplazan por 2 componentes principales. Si estas dos componentes explican una proporción alta de la varianza acumulada, por ejemplo sobre 70%, entonces el PCA es útil para simplificar el análisis sin perder demasiada información.
En términos prácticos, esta técnica puede servir para comparar proyectos de construcción, identificar obras atípicas, construir índices sintéticos de desempeño, visualizar patrones generales y preparar los datos para otros métodos como clustering o modelos predictivos.