Reducción de dimensinalidad - PCA
Juan Agustín Chanqueo Cariqueo
2026-06-22
2. Reducción de Dimensionalidad
2.1. Modelos de Machine Learning No-Supervisados
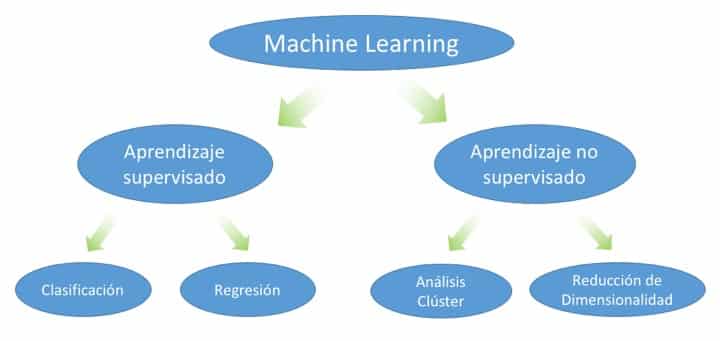
La mayoría de los métodos de aprendizaje automático pertenecen al aprendizaje supervisado, donde el objetivo es predecir una variable de respuesta Y a partir de un conjunto de características (X1,X2,…,Xp) observadas en n instancias. Matemáticamente, se define como:
#𝒀=(𝑿𝟏, 𝑿𝟐,…𝑿𝒑)+𝜺Donde:
f es una función desconocida que relaciona las características Xi con la respuesta Y
ϵ representa el ruido o error aleatorio, es decir, la variabilidad en Y que no puede explicarse por f(X)
Sin embargo, en aprendizaje no supervisado, no disponemos de la variable respuesta Y, por lo que el objetivo cambia. Ahora, buscamos descubrir estructuras o patrones en los datos X1,X2,…,Xp sin un criterio explícito de predicción.
#𝒙∈ℝ^(𝒏×𝒑)Donde:
n es el número de observaciones (filas de la matriz).
p es el número de características (columnas de la matriz).
Preguntas clave en aprendizaje no supervisado:
¿Existe una forma óptima de visualizar los datos en un espacio de menor dimensión?
¿Podemos identificar subgrupos dentro de las observaciones o entre las variables?
¿Podemos reducir la complejidad de los datos preservando su estructura más relevante?
¿Existen puntos de datos que no siguen el comportamiento general del conjunto?
2.2. ¿Qué es la reducción de la dimensionalidad?
La reducción de la dimensionalidad es un método para representar un conjunto de datos utilizando un menor número de características (dimensiones) sin perder las propiedades significativas de los datos originales. Esto equivale a eliminar características irrelevantes o redundantes, o simplemente datos ruidosos, para crear un modelo con un menor número de variables.

Aunque los métodos de reducción de la dimensionalidad difieren en su funcionamiento, todos transforman espacios de alta dimensión en espacios de baja dimensión mediante la extracción o la combinación de variables. Se favorece la compresión, eliminación de redundancia del conjunto de datos y permite mejorar procesos de clasificación y visualización de los datos a un menor costo computacional.
2.3. ¿Por qué utilizar la reducción de la dimensionalidad?
Los conjuntos de datos de alta dimensión plantean una serie de preocupaciones prácticas para los algoritmos de machine learning, como mayor tiempo de cálculo, espacio de almacenamiento para big data, etc. Pero la mayor preocupación es quizá la disminución de la precisión en los modelos predictivos. Los modelos estadísticos y de machine learning entrenados en conjuntos de datos de alta dimensión suelen generalizar mal.


Resulta difícil visualizar un conjunto de datos que contiene un gran número de características.
Un número muy elevado de características para cada instancia de entrenamiento puede hacer que el entrenamiento sea extremadamente lento.
La mayoría de los puntos en un hipercubo de alta dimensión están muy cerca del borde y corren el riesgo de ser muy dispersos, lo que hace que las predicciones sean mucho menos fiables que en dimensiones inferiores.
2.3.1. Ventajas de reducir la dimensionalidad
Reducir las dimensiones de las características implica una reducción del espacio requerido para almacenar el conjunto de datos, porque este también se reduce.
El tiempo de entrenamiento de modelos es menor para dimensiones reducidas.
Se facilita la visualización de datos más rápidamente gracias a la reducción de características del conjunto de datos.
Desaparecen las características redundantes en el ámbito de la multicolinealidad.
2.3.2. Desventajas de reducir la dimensionalidad
Se pueden perder algunos datos debido a la reducción de la dimensionalidad.
En la técnica de reducción de dimensionalidad de PCA, en ocasiones no se conocen los componentes principales que se deben considerar.
No obstante, es una técnica que requiere conocimiento y un equipo adecuado para realizarse, pues pueden eliminarse más datos de los debidos y generar un modelo erróneo.
2.4. Métodos de reducción de la dimensionalidad
Los métodos de reducción de dimensionalidad son algoritmos que mapean el conjunto de los datos a subespacios derivados del espacio original, de menor dimensión, que permiten hacer una descripción de los datos a un menor costo.
Entre los métodos más básicos de reducción de dimensionalidad, el más eficiente consiste en identificar y seleccionar un subconjunto de características que son muy relevantes para la variable objetivo. En la selección de características, principalmente, se realizan dos cosas: mantener las características que está altamente relacionadas con la variable objetivo y contribuir más a la variación del conjunto de datos
Hay muchas maneras de lograr la reducción de dimensionalidad, pero la mayoría de las técnicas se dividen en 3 clases:
Eliminación de características: reducimos el espacio de características eliminando algunas. Las ventajas de este método incluyen la simplicidad y la facilidad de mantenimiento. Además, hemos eliminado cualquier beneficio que pudieran aportar las variables eliminadas. Sin embargo, esto tiene una desventaja, ya que no obtenemos información de las características que se han eliminado.
Selección de características: Aplicamos algunas pruebas estadísticas para clasificarlas según su importancia y luego seleccionamos un subconjunto de características para nuestro trabajo. Esto nuevamente sufre de pérdida de información y es menos estable ya que diferentes pruebas dan diferentes puntuaciones de importancia a las características.
Extracción de características: Combina nuestras variables de entrada de una manera específica, lo que nos permite descartar las variables “menos importantes” y conservar las partes más valiosas de todas las variables. Creamos nuevas características independientes, donde cada nueva característica independiente es una combinación de cada una de las características independientes anteriores. Estas técnicas se pueden dividir en técnicas de reducción de dimensionalidad lineales (PCA, SVD) y no lineales (t-SNE).
2.5. Análisis de componentes principales (PCA)
El Análisis de Componentes Principales (PCA, por sus siglas en inglés) es una técnica de reducción de dimensionalidad que transforma los datos en un nuevo sistema de coordenadas, preservando la mayor cantidad posible de variabilidad en los datos originales. En otras palabras, su objetivo es encontrar una representación de menor dimensión de los datos que capture la máxima varianza posible, mediante combinaciones lineales ortogonales de las variables originales.

Matemáticamente, dados los datos centrados X, buscamos una transformación lineal Z tal que: Z=XW
Donde:
Z representa los datos transformados en el nuevo espacio de componentes principales.
W es la matriz de componentes principales, cuyas columnas son los autovectores de la matriz de covarianza de X
2.5.1. Conceptos clave en PCA:
Reducción de dimensionalidad: El proceso de representar datos en un espacio de menor dimensión mientras se conserva la mayor cantidad posible de información.
Autovectores y autovalores: Los autovectores de la matriz de covarianza indican las direcciones principales de variabilidad en los datos, mientras que los autovalores indican la magnitud de esa variabilidad.
Proporción de varianza explicada: La cantidad de información conservada en cada componente principal.
2.5.2. ¿Qué hace exactamente PCA?
Geométricamente el PCA rota el sistema de coordenadas original para que:
El primer eje (componente) esté alineado con la dirección de mayor dispersión de los datos.
El segundo eje esté en la dirección ortogonal siguiente de mayor dispersión, y así sucesivamente.
Estadísticamente el PCA:
Transforma variables correlacionadas en nuevas variables no correlacionadas.
Cada nueva variable es una combinación lineal de las originales: Z1=a11X1+a12X2+⋯+a1pXp
2.6. Pasos para realizar un PCA
Paso 1: Estandarización
La razón por la que la estandarización es tan necesaria antes de realizar el PCA es que este análisis es muy sensible a las varianzas. Es decir, si existen grandes diferencias entre las escalas (rangos) de las variables originales, aquellas con escalas mayores dominarán sobre aquellas con escalas menores. La estandarización de datos es la transformación de las características mediante la resta de la media y la división por la desviación estándar.

Paso 2: Calcular la matriz de covarianza
Este paso tiene como objetivo comprender cómo varían las variables originales del conjunto de datos de entrada con respecto a la media entre sí, o dicho de otro modo, ver si existe alguna relación entre ellas. Porque a veces, las variables originales están altamente correlacionadas de tal manera que contienen información redundante. Por lo tanto, para identificar estas correlaciones, calculamos la matriz de covarianza.

Matriz de covarianza

El signo de las variables en la matriz nos indica si las combinaciones están correlacionadas:
Positivo (las variables originales están correlacionadas y aumentan o disminuyen simultáneamente)
Negativo (las variables originales no están correlacionadas; es decir, una disminuye mientras la otra aumenta)
Cero (las variables originales no están relacionadas entre sí)
Paso 3: Calculo de los autovalores y autovectores de la matriz de covarianza
Aquí, calculamos los autovectores (componentes principales) y los autovalores de la matriz de covarianza. Como autovectores, los componentes principales representan las direcciones de máxima varianza en los datos. Los autovalores representan la cantidad de varianza en cada componente. La clasificación de los autovectores por autovalor identifica el orden de los componentes principales. El PCA busca preservar las distancias euclidianas entre los puntos tanto como sea posible al reducir la dimensionalidad.
Paso 4: Selección de componentes principales
Aquí decidimos qué componentes conservar y cuáles descartar. Los componentes con valores propios bajos generalmente no serán tan significativos. Los gráficos de sedimentación suelen representar la proporción de la varianza total explicada y la proporción acumulada de la varianza. Estas métricas ayudan a determinar el número óptimo de componentes a conservar. El punto en el que el eje Y de los valores propios o la varianza total explicada crea un “codo” generalmente indicará cuántos componentes de PCA queremos incluir.
Ordenación de pares propios
Para decidir qué vector(es) propio(s) se pueden descartar sin perder demasiada información, es necesario examinar los valores propios correspondientes: los vectores propios con los valores propios más bajos contienen la menor cantidad de información sobre la distribución de los datos; estos son los que se pueden descartar.
El enfoque común consiste en ordenar los valores propios de mayor a menor.
Varianza explicada
Para cuantos componentes principales se van a seleccionar en el nuevo subpespacio de caracteristicas se puede utilizar la denominada varianza explicada. La varianza explicada nos indica cuánta información (varianza) se puede atribuir a cada uno de los componentes principales. Se puede calcular a partir de los valores propios.
Paso 5: Transformar los datos al nuevo sistema de coordenadas
Matriz de proyección
La matriz de proyección se utiliza para transformar los datos de entrada (X) en el nuevo subespacio de características. La matriz de proyección es una matriz de los k autovectores más significativos concatenados.
2.7. Ejemplo práctico de PCA
Problema de ingeniería
Supongamos que una empresa constructora ha evaluado 30 mezclas de hormigón para determinar cuáles tienen mejor desempeño global.
Para cada mezcla se midieron:
Resistencia a compresión (MPa) Resistencia a tracción (MPa) Módulo de elasticidad (GPa) Densidad (kg/m³) Absorción de agua (%) Permeabilidad (10⁻¹² m/s)
La empresa quiere:
Reducir la cantidad de variables. Identificar qué propiedades explican la mayor parte de la variabilidad. Agrupar mezclas similares.
Paso 1: Crear una base de datos simulada
# Fijar semilla para reproducibilidad
set.seed(123)
# Número de mezclas
n <- 30
# Simulación de variables
resistencia_comp <- rnorm(n, mean = 40, sd = 8)
resistencia_trac <- resistencia_comp*0.08 +
rnorm(n, mean = 0, sd = 0.3)
modulo_elast <- resistencia_comp*0.7 +
rnorm(n, mean = 0, sd = 2)
densidad <- rnorm(n, mean = 2400, sd = 50)
absorcion <- 12 - resistencia_comp*0.15 +
rnorm(n, mean = 0, sd = 0.5)
permeabilidad <- 20 - resistencia_comp*0.4 +
rnorm(n, mean = 0, sd = 1)
# Construir dataframe
hormigon <- data.frame(
resistencia_comp,
resistencia_trac,
modulo_elast,
densidad,
absorcion,
permeabilidad
)
head(hormigon)## resistencia_comp resistencia_trac modulo_elast densidad absorcion
## 1 35.51619 2.969235 25.62062 2449.675 6.731394
## 2 38.15858 2.964165 25.70636 2427.420 5.802476
## 3 52.46967 4.466111 36.06235 2411.937 3.884271
## 4 40.56407 3.508565 26.35770 2368.605 5.787344
## 5 41.03430 3.529218 26.58043 2468.033 6.766786
## 6 53.72052 4.504234 38.21142 2369.987 3.615947
## permeabilidad
## 1 6.581261
## 2 5.505610
## 3 -0.655664
## 4 2.765997
## 5 3.466827
## 6 -1.768603Paso 2: Explorar correlaciones
cor(hormigon)## resistencia_comp resistencia_trac modulo_elast densidad
## resistencia_comp 1.0000000 0.92182527 0.95865561 0.042341504
## resistencia_trac 0.9218253 1.00000000 0.85744569 0.070890619
## modulo_elast 0.9586556 0.85744569 1.00000000 0.038241572
## densidad 0.0423415 0.07089062 0.03824157 1.000000000
## absorcion -0.8922410 -0.82930533 -0.87773833 -0.009951228
## permeabilidad -0.9557220 -0.84019735 -0.91326467 -0.024328590
## absorcion permeabilidad
## resistencia_comp -0.892241020 -0.95572203
## resistencia_trac -0.829305334 -0.84019735
## modulo_elast -0.877738330 -0.91326467
## densidad -0.009951228 -0.02432859
## absorcion 1.000000000 0.84964580
## permeabilidad 0.849645801 1.00000000Las mezclas con mayor resistencia a compresión también presentan:
- Mayor resistencia a tracción, mayor módulo de elasticidad.
Por lo tanto, estas variables contienen información similar y son candidatas ideales para reducción de dimensionalidad mediante PCA.
Los hormigones más absorbentes también son más permeables, lo cual es coherente desde el punto de vista físico porque una estructura de poros más abierta favorece ambos fenómenos.
A medida que aumenta la resistencia:
- Disminuye la absorción, disminuye la permeabilidad.
Esto sugiere que las mezclas más resistentes poseen una microestructura más densa.
La densidad no está aportando la misma información que las otras variables y podría constituir una dimensión independiente dentro del PCA.
¿Por qué tiene sentido aplicar PCA?
El PCA es útil cuando existen variables altamente correlacionadas.Todas son correlaciones muy altas. Por tanto, existe redundancia de información. podríamos resumirlas en uno o dos componentes principales.
Hipótesis previas al PCA
PC1 Represente algo como: “Calidad estructural y durabilidad del hormigón”
PC2 Probablemente esté asociado principalmente a: densidad porque esta variable aparece casi independiente del resto.
Paso 3: Estandarizar las variables y Ejecución PCA
datos_std <- scale(hormigon)
pca <- prcomp(datos_std)
summary(pca)## Importance of components:
## PC1 PC2 PC3 PC4 PC5 PC6
## Standard deviation 2.1361 1.0003 0.41825 0.40494 0.28713 0.12353
## Proportion of Variance 0.7605 0.1668 0.02916 0.02733 0.01374 0.00254
## Cumulative Proportion 0.7605 0.9272 0.95639 0.98372 0.99746 1.00000PC1: Explica el 76.05 % de toda la información de la base de datos. PC2: Explica un 16.68 % adicional.
¿Cuántos componentes conservar?
Regla 1: Varianza acumulada > 80 % -> PC1 + PC2 = 92.72 %
El criterio de la Varianza Acumulada es uno de los métodos estándar y más prácticos en minería de datos e ingeniería para decidir con cuántos componentes principales quedarte. Se establece un umbral u objetivo de información (generalmente entre el 80% y el 90% de la varianza total). Te quedas con el número mínimo de componentes necesarios para superar ese porcentaje.
Con solo PC1: Retiene el 76.05% de la información original. Con PC1 + PC2: Al sumar el 16.68% del segundo componente, se alcanza un 92.72% de varianza acumulada.
Regla 2: Criterio de Kaiser Autovalor > 1 λ=SD2
El Criterio de Kaiser (o regla del autovalor mayor a 1) es una de las reglas más utilizadas en el Análisis de Componentes Principales (PCA) para decidir con cuántos componentes quedarte y cuáles descartar. Regla: Solo debes conservar aquellos Componentes Principales cuyo Autovalor (Eigenvalue) sea ma
Bajo este criterio, se debe conservar únicamente PC1 y PC2. Juntos logran retener el 92.72% de toda la variabilidad de tus mezclas de hormigón, pasando de 6 dimensiones a solo 2.
El análisis de componentes principales permitió reducir las seis variables originales a dos componentes principales. El primer componente (PC1) explicó el 76.05 % de la variabilidad total de los datos, mientras que el segundo componente (PC2) explicó un 16.68 % adicional. En conjunto, ambos componentes representaron el 92.72 % de la variabilidad total, indicando que la mayor parte de la información contenida en las variables mecánicas y de durabilidad puede describirse mediante dos dimensiones latentes.
Paso 4: Scree Plot
plot(pca,
type = "l",
main = "Scree Plot")
Scree Plot confirma perfectamente lo que ya mostraba el summary(pca).
En el eje Y aparecen los autovalores (eigenvalues) o varianza explicada por cada componente. PC1 y PC2 contienen casi toda la información. Los componentes PC3, PC4, PC5 y PC6 aportan muy poco.
El gráfico Scree Plot evidenció una disminución abrupta de la varianza explicada entre los dos primeros componentes y el resto de los componentes principales. El punto de inflexión se observó después del segundo componente, indicando que los componentes PC1 y PC2 concentran la mayor parte de la información del conjunto de datos. Además, de acuerdo con el criterio de Kaiser (autovalores ≥ 1), sólo los dos primeros componentes fueron retenidos para el análisis posterior. En conjunto, estos componentes explicaron el 92,72 % de la varianza total.
Paso 5: Cargas (Loadings)
pca$rotation## PC1 PC2 PC3 PC4 PC5
## resistencia_comp 0.46381190 -0.006140254 -0.05862094 0.198170938 0.02261692
## resistencia_trac 0.43612539 0.031954061 -0.84153668 -0.191936362 -0.05546323
## modulo_elast 0.45198414 -0.010801454 0.22155052 0.208351809 0.78416201
## densidad 0.02331178 0.998221956 0.05272789 -0.009408906 -0.01184634
## absorcion -0.43572811 0.041681285 -0.41942642 0.775916835 0.17289882
## permeabilidad -0.44719244 0.025301404 -0.24616298 -0.527582007 0.59284730
## PC6
## resistencia_comp 0.8611742925
## resistencia_trac -0.2463206326
## modulo_elast -0.2969654917
## densidad 0.0006276442
## absorcion 0.0233286537
## permeabilidad 0.3301088617round(pca$rotation,3)## PC1 PC2 PC3 PC4 PC5 PC6
## resistencia_comp 0.464 -0.006 -0.059 0.198 0.023 0.861
## resistencia_trac 0.436 0.032 -0.842 -0.192 -0.055 -0.246
## modulo_elast 0.452 -0.011 0.222 0.208 0.784 -0.297
## densidad 0.023 0.998 0.053 -0.009 -0.012 0.001
## absorcion -0.436 0.042 -0.419 0.776 0.173 0.023
## permeabilidad -0.447 0.025 -0.246 -0.528 0.593 0.330pca_2 <- prcomp(datos_std)
round(pca_2$rotation[,1:2],3)## PC1 PC2
## resistencia_comp 0.464 -0.006
## resistencia_trac 0.436 0.032
## modulo_elast 0.452 -0.011
## densidad 0.023 0.998
## absorcion -0.436 0.042
## permeabilidad -0.447 0.025La Interpretación de las Cargas (Loadings) es el paso más importante del PCA desde el punto de vista de la ingeniería. Es aquí donde transformamos la matemática pura en conceptos físicos y prácticos, permitiéndote entender qué significan realmente tus nuevos componentes.
Una regla práctica en estadística es considerar que una variable aporta de forma significativa a un componente si su carga (en valor absoluto) es mayor a 0.40
|loading| > 0.4. Valores cercanos a ±1 → gran influencia en el componente.
Valores cercanos a 0 → poca influencia.
Componente Principal 1 (PC1):
PC1 aumenta cuado aumenta la resistencia a compresión aumenta la resistencia a tracción aumenta el módulo elástico y disminuye cuando aumenta la absorción aumenta la permeabilidad
PC1 representa claramente: Calidad mecánica y durabilidad del hormigón
Componente Principal 2 (PC2):
PC2 representa casi exclusivamente: Variación en la densidad. Esto coincide exactamente con lo que habíamos predicho al observar la matriz de correlaciones. La densidad estaba prácticamente desacoplada del resto de variables.
Paso 6: Obtener las coordenadas PCA
scores <- pca$x
head(scores)## PC1 PC2 PC3 PC4 PC5 PC6
## [1,] -1.13411226 1.2346072 -0.08039905 -0.02150246 0.2432603 0.005043533
## [2,] -0.51596198 0.7030920 0.27439641 -0.33598800 -0.0588048 0.163742953
## [3,] 3.64948761 0.2956127 -0.33881626 -0.21800678 -0.2066024 -0.030173739
## [4,] 0.40690788 -0.5897746 -0.28884274 0.04066673 -0.5115139 -0.099731386
## [5,] 0.08145294 1.6371385 -0.57408287 0.51677132 -0.2448084 0.025024307
## [6,] 4.13761240 -0.6484822 -0.19336228 -0.09467284 -0.1597827 -0.134436651los Scores (o puntuaciones) son los nuevos valores que toman tus mezclas de hormigón en el nuevo espacio generado por el PCA.
Físicamente, representan la “posición” o las “coordenadas” de cada una de tus muestras dentro del nuevo sistema de ejes (PC1, PC2, etc.).
Paso 7: Graficar las mezclas en dos dimensiones
plot(scores[,1],
scores[,2],
xlab = "PC1",
ylab = "PC2",
main = "PCA de mezclas de hormigón")
text(scores[,1],
scores[,2],
labels = 1:n)
symbols(
x = 3.7,
y = -0.4,
circles = 1.0,
inches = FALSE,
add = TRUE
)
Hacia la derecha → hormigones de mejor desempeño global. Hacia la izquierda → hormigones de menor desempeño global. Hacia arriba → mayor densidad. Hacia abajo → menor densidad.
La representación de las observaciones en el plano definido por los dos primeros componentes principales permitió visualizar las similitudes y diferencias entre las mezclas de hormigón. El primer componente principal (PC1), asociado al desempeño mecánico y la durabilidad, separó claramente las mezclas con altas resistencias y baja permeabilidad de aquellas con propiedades menos favorables. El segundo componente principal (PC2), relacionado principalmente con la densidad, explicó una fracción menor de la variabilidad total. La proyección de las mezclas en el espacio PC1-PC2 conservó el 92,72 % de la variabilidad total del conjunto de datos, evidenciando una reducción efectiva de la dimensionalidad desde seis variables originales a dos componentes interpretables físicamente.
Paso 8: Biplot
biplot(pca,
cex = 0.8)
El gráfico corresponde a un biplot de PCA (Análisis de Componentes Principales), donde se representan simultáneamente las observaciones (números negros) y las variables originales (flechas rojas) proyectadas en los dos primeros componentes principales (PC1 y PC2).
El Biplot es la herramienta gráfica más potente del Análisis de Componentes Principales (PCA). Se llama “bi-” porque representa dos cosas al mismo tiempo en un solo plano bidimensional (generalmente combinando el PC1 en el eje horizontal y el PC2 en el eje vertical)
En primer lugar, el PC1 (eje horizontal) es el componente que explica la mayor parte de la variabilidad del conjunto de datos. Se observa que este eje separa principalmente a las muestras en dos grupos: aquellas ubicadas hacia la derecha presentan valores altos en PC1, mientras que las ubicadas hacia la izquierda presentan valores bajos. La flecha asociada a una de las variables (horizontal) indica que esta variable está fuertemente correlacionada con PC1, es decir, es la principal responsable de esa diferenciación.
Por otro lado, el PC2 (eje vertical) explica una variabilidad secundaria. En este eje destaca la variable representada por la flecha vertical, etiquetada como “densidad”, la cual tiene una fuerte carga positiva sobre PC2. Esto indica que las muestras ubicadas en la parte superior del gráfico están asociadas a mayores valores de densidad, mientras que las ubicadas en la parte inferior presentan menores valores de esta variable.
Las flechas rojas también permiten interpretar relaciones entre variables: el ángulo entre ellas sugiere su correlación. En este caso, las variables no parecen estar completamente alineadas, lo que sugiere que PC1 y PC2 capturan información parcialmente independiente.
En términos de agrupamiento, se observa que varias observaciones se concentran cerca del origen, lo que indica comportamientos intermedios o mixtos, mientras que algunas muestras más extremas (por ejemplo, en los cuadrantes superiores o inferiores) representan casos con características más diferenciadas.
En resumen, el PCA muestra que la variabilidad del sistema está dominada por una variable asociada a PC1 (horizontal) y por la densidad en PC2, permitiendo distinguir patrones claros entre los grupos de observaciones en función de estas dos dimensiones principales.