Reducción de dimensinalidad - PCA
Juan Agustín Chanqueo Cariqueo
2026-06-24
2. Reducción de Dimensionalidad
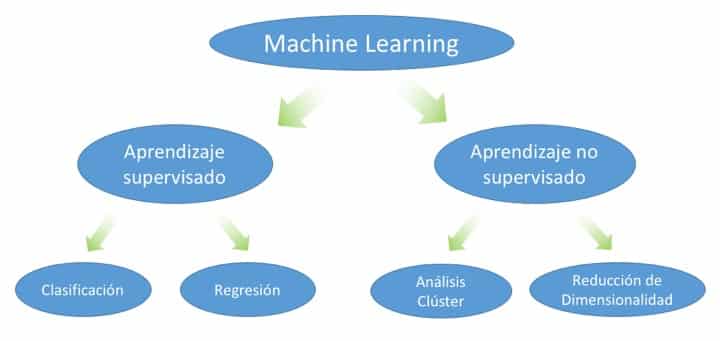
2.1. Modelos de Machine Learning No-Supervisados
La mayoría de los métodos de aprendizaje automático pertenecen al aprendizaje supervisado, donde el objetivo es predecir una variable de respuesta Y a partir de un conjunto de características (X1,X2,…,Xp) observadas en n instancias. Matemáticamente, se define como:
#𝒀=(𝑿𝟏, 𝑿𝟐,…𝑿𝒑)+𝜺Donde:
f es una función desconocida que relaciona las características Xi con la respuesta Y
ϵ representa el ruido o error aleatorio, es decir, la variabilidad en Y que no puede explicarse por f(X)
Sin embargo, en aprendizaje no supervisado, no disponemos de la variable respuesta Y, por lo que el objetivo cambia. Ahora, buscamos descubrir estructuras o patrones en los datos X1,X2,…,Xp sin un criterio explícito de predicción.
#𝒙∈ℝ^(𝒏×𝒑)Donde:
n es el número de observaciones (filas de la matriz).
p es el número de características (columnas de la matriz).
Preguntas clave en aprendizaje no supervisado:
¿Existe una forma óptima de visualizar los datos en un espacio de menor dimensión?
¿Podemos identificar subgrupos dentro de las observaciones o entre las variables?
¿Podemos reducir la complejidad de los datos preservando su estructura más relevante?
¿Existen puntos de datos que no siguen el comportamiento general del conjunto?
2.2. ¿Qué es la reducción de la dimensionalidad?
La reducción de la dimensionalidad es un método para representar un conjunto de datos utilizando un menor número de características (dimensiones) sin perder las propiedades significativas de los datos originales. Esto equivale a eliminar características irrelevantes o redundantes, o simplemente datos ruidosos, para crear un modelo con un menor número de variables.

Aunque los métodos de reducción de la dimensionalidad difieren en su funcionamiento, todos transforman espacios de alta dimensión en espacios de baja dimensión mediante la extracción o la combinación de variables. Se favorece la compresión, eliminación de redundancia del conjunto de datos y permite mejorar procesos de clasificación y visualización de los datos a un menor costo computacional.
2.3. ¿Por qué utilizar la reducción de la dimensionalidad?
Los conjuntos de datos de alta dimensión plantean una serie de preocupaciones prácticas para los algoritmos de machine learning, como mayor tiempo de cálculo, espacio de almacenamiento para big data, etc. Pero la mayor preocupación es quizá la disminución de la precisión en los modelos predictivos. Los modelos estadísticos y de machine learning entrenados en conjuntos de datos de alta dimensión suelen generalizar mal.


Resulta difícil visualizar un conjunto de datos que contiene un gran número de características.
Un número muy elevado de características para cada instancia de entrenamiento puede hacer que el entrenamiento sea extremadamente lento.
La mayoría de los puntos en un hipercubo de alta dimensión están muy cerca del borde y corren el riesgo de ser muy dispersos, lo que hace que las predicciones sean mucho menos fiables que en dimensiones inferiores.
2.3.1. Ventajas de reducir la dimensionalidad
Reducir las dimensiones de las características implica una reducción del espacio requerido para almacenar el conjunto de datos, porque este también se reduce.
El tiempo de entrenamiento de modelos es menor para dimensiones reducidas.
Se facilita la visualización de datos más rápidamente gracias a la reducción de características del conjunto de datos.
Desaparecen las características redundantes en el ámbito de la multicolinealidad.
2.3.2. Desventajas de reducir la dimensionalidad
Se pueden perder algunos datos debido a la reducción de la dimensionalidad.
En la técnica de reducción de dimensionalidad de PCA, en ocasiones no se conocen los componentes principales que se deben considerar.
No obstante, es una técnica que requiere conocimiento y un equipo adecuado para realizarse, pues pueden eliminarse más datos de los debidos y generar un modelo erróneo.
2.4. Métodos de reducción de la dimensionalidad
Los métodos de reducción de dimensionalidad son algoritmos que mapean el conjunto de los datos a subespacios derivados del espacio original, de menor dimensión, que permiten hacer una descripción de los datos a un menor costo.
Entre los métodos más básicos de reducción de dimensionalidad, el más eficiente consiste en identificar y seleccionar un subconjunto de características que son muy relevantes para la variable objetivo. En la selección de características, principalmente, se realizan dos cosas: mantener las características que está altamente relacionadas con la variable objetivo y contribuir más a la variación del conjunto de datos
Hay muchas maneras de lograr la reducción de dimensionalidad, pero la mayoría de las técnicas se dividen en 3 clases:
Eliminación de características: reducimos el espacio de características eliminando algunas. Las ventajas de este método incluyen la simplicidad y la facilidad de mantenimiento. Además, hemos eliminado cualquier beneficio que pudieran aportar las variables eliminadas. Sin embargo, esto tiene una desventaja, ya que no obtenemos información de las características que se han eliminado.
Selección de características: Aplicamos algunas pruebas estadísticas para clasificarlas según su importancia y luego seleccionamos un subconjunto de características para nuestro trabajo. Esto nuevamente sufre de pérdida de información y es menos estable ya que diferentes pruebas dan diferentes puntuaciones de importancia a las características.
Extracción de características: Combina nuestras variables de entrada de una manera específica, lo que nos permite descartar las variables “menos importantes” y conservar las partes más valiosas de todas las variables. Creamos nuevas características independientes, donde cada nueva característica independiente es una combinación de cada una de las características independientes anteriores. Estas técnicas se pueden dividir en técnicas de reducción de dimensionalidad lineales (PCA, SVD) y no lineales (t-SNE).
2.5. Análisis de componentes principales (PCA)
El Análisis de Componentes Principales (PCA, por sus siglas en inglés) es una técnica de reducción de dimensionalidad que transforma los datos en un nuevo sistema de coordenadas, preservando la mayor cantidad posible de variabilidad en los datos originales. En otras palabras, su objetivo es encontrar una representación de menor dimensión de los datos que capture la máxima varianza posible, mediante combinaciones lineales ortogonales de las variables originales.

Matemáticamente, dados los datos centrados X, buscamos una transformación lineal Z tal que: Z=XW
Donde:
Z representa los datos transformados en el nuevo espacio de componentes principales.
W es la matriz de componentes principales, cuyas columnas son los autovectores de la matriz de covarianza de X
2.5.1. Conceptos clave en PCA:
Reducción de dimensionalidad: El proceso de representar datos en un espacio de menor dimensión mientras se conserva la mayor cantidad posible de información.
Autovectores y autovalores: Los autovectores de la matriz de covarianza indican las direcciones principales de variabilidad en los datos, mientras que los autovalores indican la magnitud de esa variabilidad.
Proporción de varianza explicada: La cantidad de información conservada en cada componente principal.
2.5.2. ¿Qué hace exactamente PCA?
Geométricamente el PCA rota el sistema de coordenadas original para que:
El primer eje (componente) esté alineado con la dirección de mayor dispersión de los datos.
El segundo eje esté en la dirección ortogonal siguiente de mayor dispersión, y así sucesivamente.
Estadísticamente el PCA:
Transforma variables correlacionadas en nuevas variables no correlacionadas.
Cada nueva variable es una combinación lineal de las originales: Z1=a11X1+a12X2+⋯+a1pXp
2.6. Pasos para realizar un PCA
Paso 1: Estandarización
La razón por la que la estandarización es tan necesaria antes de realizar el PCA es que este análisis es muy sensible a las varianzas. Es decir, si existen grandes diferencias entre las escalas (rangos) de las variables originales, aquellas con escalas mayores dominarán sobre aquellas con escalas menores. La estandarización de datos es la transformación de las características mediante la resta de la media y la división por la desviación estándar.

Paso 2: Calcular la matriz de covarianza
Este paso tiene como objetivo comprender cómo varían las variables originales del conjunto de datos de entrada con respecto a la media entre sí, o dicho de otro modo, ver si existe alguna relación entre ellas. Porque a veces, las variables originales están altamente correlacionadas de tal manera que contienen información redundante. Por lo tanto, para identificar estas correlaciones, calculamos la matriz de covarianza.

Matriz de covarianza

El signo de las variables en la matriz nos indica si las combinaciones están correlacionadas:
Positivo (las variables originales están correlacionadas y aumentan o disminuyen simultáneamente)
Negativo (las variables originales no están correlacionadas; es decir, una disminuye mientras la otra aumenta)
Cero (las variables originales no están relacionadas entre sí)
Paso 3: Calculo de los autovalores y autovectores de la matriz de covarianza
Aquí, calculamos los autovectores (componentes principales) y los autovalores de la matriz de covarianza. Como autovectores, los componentes principales representan las direcciones de máxima varianza en los datos. Los autovalores representan la cantidad de varianza en cada componente. La clasificación de los autovectores por autovalor identifica el orden de los componentes principales. El PCA busca preservar las distancias euclidianas entre los puntos tanto como sea posible al reducir la dimensionalidad.
Paso 4: Selección de componentes principales
Aquí decidimos qué componentes conservar y cuáles descartar. Los componentes con valores propios bajos generalmente no serán tan significativos. Los gráficos de sedimentación suelen representar la proporción de la varianza total explicada y la proporción acumulada de la varianza. Estas métricas ayudan a determinar el número óptimo de componentes a conservar. El punto en el que el eje Y de los valores propios o la varianza total explicada crea un “codo” generalmente indicará cuántos componentes de PCA queremos incluir.
Ordenación de pares propios
Para decidir qué vector(es) propio(s) se pueden descartar sin perder demasiada información, es necesario examinar los valores propios correspondientes: los vectores propios con los valores propios más bajos contienen la menor cantidad de información sobre la distribución de los datos; estos son los que se pueden descartar.
El enfoque común consiste en ordenar los valores propios de mayor a menor.
Varianza explicada
Para cuantos componentes principales se van a seleccionar en el nuevo subpespacio de caracteristicas se puede utilizar la denominada varianza explicada. La varianza explicada nos indica cuánta información (varianza) se puede atribuir a cada uno de los componentes principales. Se puede calcular a partir de los valores propios.
Paso 5: Transformar los datos al nuevo sistema de coordenadas
Matriz de proyección
La matriz de proyección se utiliza para transformar los datos de entrada (X) en el nuevo subespacio de características. La matriz de proyección es una matriz de los k autovectores más significativos concatenados.
Ejemplo práctico de PCA
Problema de ingeniería
Una empresa constructora, a través de su laboratorio de control de calidad, ha evaluado 50 mezclas de hormigón desarrolladas para distintos proyectos de infraestructura. El objetivo es comprender cuáles son las propiedades que más influyen en el comportamiento global del material y simplificar el análisis de los resultados obtenidos.
Para cada mezcla se realizaron ensayos de laboratorio y se registraron las siguientes propiedades físicas y mecánicas:
- Resistencia a compresión (MPa): capacidad del hormigón para soportar cargas de compresión.
- Resistencia a tracción (MPa): capacidad del material para resistir esfuerzos de tracción antes de fisurarse.
- Módulo de elasticidad (GPa): indicador de la rigidez del hormigón.
- Densidad (kg/m³): masa por unidad de volumen del material endurecido.
- Absorción de agua (%): porcentaje de agua absorbida por el hormigón, asociado a su porosidad.
- Permeabilidad (10⁻¹² m/s): capacidad del agua para atravesar la estructura interna del material, relacionada con su durabilidad.
Los ingenieros sospechan que varias de estas propiedades están relacionadas entre sí. Por ejemplo, mezclas con alta resistencia mecánica podrían presentar también una mayor rigidez y menores valores de absorción y permeabilidad. En consecuencia, algunas variables podrían estar aportando información similar, dificultando la interpretación de los resultados cuando se analizan todas simultáneamente.
Con el fin de simplificar el estudio y obtener una visión más clara de los factores que caracterizan el desempeño de las mezclas, la empresa decide aplicar un Análisis de Componentes Principales (ACP).
Objetivos del análisis - Reducir la cantidad de variables originales mediante la construcción de un conjunto más pequeño de componentes principales. - Determinar qué propiedades explican la mayor parte de la variabilidad observada entre las mezclas de hormigón. - Identificar relaciones y correlaciones entre las variables medidas. - Interpretar el significado físico de los componentes principales obtenidos. - Representar las mezclas en un espacio de menor dimensión, conservando la mayor cantidad posible de información contenida en los datos originales.
Para ello, se dispone de una base de datos con 50 observaciones (mezclas de hormigón) y 6 variables cuantitativas, sobre la cual se realizará un Análisis de Componentes Principales utilizando la matriz de correlaciones estandarizada.
Este planteamiento justifica naturalmente preguntas típicas de un ejercicio de PCA, como:
¿Cuántos componentes deben retenerse? ¿Qué porcentaje de la variabilidad explican los primeros componentes? ¿Qué variables tienen mayor peso en cada componente? ¿Cómo se interpretan los componentes obtenidos desde el punto de vista ingenieril?
Paso 1: Crear una base de datos simulada
#====================================================
# BASE DE DATOS SIMULADA PARA PCA
# 50 mezclas de hormigón
#====================================================
set.seed(123)
n <- 50
# Factor latente de calidad del hormigón
calidad <- rnorm(n, mean = 0, sd = 1)
# Variables mecánicas (correlacionadas positivamente)
res_comp <- 40 + 8*calidad + rnorm(n, 0, 2) # MPa
res_trac <- 4.5 + 0.7*calidad + rnorm(n, 0, 0.2) # MPa
mod_elas <- 32 + 5*calidad + rnorm(n, 0, 1.5) # GPa
# Densidad (moderadamente correlacionada)
densidad <- 2350 + 40*calidad + rnorm(n, 0, 20) # kg/m3
# Variables de durabilidad (relación inversa con calidad)
absorcion <- 6 - 1.2*calidad + rnorm(n, 0, 0.4) # %
permeabilidad <- 3 - 0.8*calidad + rnorm(n, 0, 0.3) # 10^-12 m/s
# Base de datos
hormigon <- data.frame(
Resistencia_Compresion = round(res_comp, 2),
Resistencia_Traccion = round(res_trac, 2),
Modulo_Elasticidad = round(mod_elas, 2),
Densidad = round(densidad, 0),
Absorcion_Agua = round(absorcion, 2),
Permeabilidad = round(permeabilidad, 2)
)Paso 2: Análisis descriptivo de los datos
summary(hormigon)## Resistencia_Compresion Resistencia_Traccion Modulo_Elasticidad Densidad
## Min. :24.37 Min. :3.000 Min. :21.44 Min. :2257
## 1st Qu.:35.07 1st Qu.:3.962 1st Qu.:29.36 1st Qu.:2331
## Median :39.88 Median :4.445 Median :31.91 Median :2353
## Mean :40.57 Mean :4.473 Mean :32.23 Mean :2351
## 3rd Qu.:46.13 3rd Qu.:4.990 3rd Qu.:35.67 3rd Qu.:2370
## Max. :56.75 Max. :5.810 Max. :41.50 Max. :2455
## Absorcion_Agua Permeabilidad
## Min. :3.170 Min. :1.280
## 1st Qu.:5.117 1st Qu.:2.335
## Median :6.165 Median :2.975
## Mean :6.058 Mean :2.973
## 3rd Qu.:6.768 3rd Qu.:3.487
## Max. :7.980 Max. :4.550# Boxplots en una sola figura
boxplot(hormigon,
main = "Boxplots de las propiedades del hormigón",
xlab = "Variables",
ylab = "Valores",
las = 2)
La representación de los boxplots de las variables del conjunto de datos de hormigón muestra un comportamiento gráfico fuertemente condicionado por las diferencias de escala entre las variables medidas. En particular, se observa que la variable densidad presenta valores numéricos considerablemente más altos (del orden de miles de kg/m³) en comparación con el resto de variables, cuyas magnitudes se encuentran en rangos mucho más reducidos, como las resistencias mecánicas (decenas de MPa), el módulo de elasticidad (decenas de GPa) y las variables de durabilidad (valores entre 1 y 8).
Esta diferencia de órdenes de magnitud provoca que el eje vertical del gráfico quede dominado por la variable densidad, comprimiendo visualmente la variabilidad del resto de variables hacia la parte inferior del gráfico. Como consecuencia, aunque todas las variables presentan dispersión interna, esta no es fácilmente apreciable en la escala original cuando se representan conjuntamente.
Este fenómeno no implica un error en los datos ni en la representación, sino que refleja una característica inherente al conjunto de variables: cada una está expresada en unidades diferentes y con escalas propias. Sin embargo, esta situación limita la comparación directa de la variabilidad entre variables, ya que la escala absoluta distorsiona la percepción visual de su dispersión relativa.
Por este motivo, este comportamiento justifica la necesidad de estandarizar las variables antes de realizar análisis multivariantes como el Análisis de Componentes Principales (PCA), de forma que todas contribuyan en igualdad de condiciones al análisis y puedan ser comparadas en términos de variabilidad relativa.
Paso 3: Explorar correlaciones
cor(hormigon)## Resistencia_Compresion Resistencia_Traccion
## Resistencia_Compresion 1.0000000 0.9186025
## Resistencia_Traccion 0.9186025 1.0000000
## Modulo_Elasticidad 0.9156702 0.9139751
## Densidad 0.8292378 0.8295366
## Absorcion_Agua -0.9237671 -0.9236953
## Permeabilidad -0.8897616 -0.8888953
## Modulo_Elasticidad Densidad Absorcion_Agua
## Resistencia_Compresion 0.9156702 0.8292378 -0.9237671
## Resistencia_Traccion 0.9139751 0.8295366 -0.9236953
## Modulo_Elasticidad 1.0000000 0.8573631 -0.8975401
## Densidad 0.8573631 1.0000000 -0.8320846
## Absorcion_Agua -0.8975401 -0.8320846 1.0000000
## Permeabilidad -0.8895435 -0.7989631 0.8600974
## Permeabilidad
## Resistencia_Compresion -0.8897616
## Resistencia_Traccion -0.8888953
## Modulo_Elasticidad -0.8895435
## Densidad -0.7989631
## Absorcion_Agua 0.8600974
## Permeabilidad 1.0000000La matriz de correlación del hormigón muestra una estructura muy consistente entre propiedades mecánicas y de durabilidad. La resistencia a compresión, tracción y el módulo de elasticidad están fuertemente correlacionados entre sí (r ≈ 0.91–0.92), lo que indica un comportamiento mecánico altamente redundante y gobernado por un mismo mecanismo resistente. La densidad también se asocia positivamente con estas variables (r ≈ 0.83–0.86), reflejando el efecto de la compacidad del material.
En contraste, la absorción de agua y la permeabilidad presentan correlaciones negativas fuertes con las propiedades mecánicas (r ≈ -0.89 a -0.92), lo que confirma que una mayor resistencia implica una menor conectividad porosa y, por tanto, mejor durabilidad. Entre ambas variables de durabilidad existe además una relación positiva alta (r = 0.86), indicando un mecanismo físico común.
En conjunto, se distinguen dos dominios principales: uno mecánico y otro de durabilidad, fuertemente acoplados de forma inversa, lo que refleja la relación clásica entre densificación del material y mejora simultánea de resistencia y desempeño frente al ingreso de agentes externos.
#Grupo 1: Propiedades mecánicas
#| Relación | Correlación |
#| ---------------------------------------- | ----------: |
#| Resistencia compresión – Tracción | 0.918 |
#| Resistencia compresión – Módulo elástico | 0.916 |
#| Tracción – Módulo elástico | 0.914 |Las variables mecánicas presentan correlaciones muy elevadas entre sí, lo que indica que responden a un mismo factor estructural del material.
En términos prácticos, las mezclas con mayor resistencia a compresión tienden también a presentar mayor resistencia a tracción y mayor rigidez (módulo de elasticidad).
Esto sugiere una alta redundancia de información y hace que este conjunto sea un candidato natural para reducción de dimensionalidad mediante PCA.
#Grupo 2: Indicadores de durabilidad
#| Relación | Correlación |
#| ------------------------- | ----------: |
#| Absorción – Permeabilidad | 0.860 |Existe una relación positiva fuerte entre absorción y permeabilidad, lo que es consistente con la física del material: una mayor conectividad del sistema poroso incrementa simultáneamente ambas propiedades.
Ambas variables pueden interpretarse como manifestaciones del mismo fenómeno subyacente: la porosidad efectiva.
#Relación entre resistencia y durabilidad
#| Relación | Correlación |
#| -------------------------------------- | ----------: |
#| Resistencia compresión – Absorción | -0.924 |
#| Resistencia compresión – Permeabilidad | -0.890 |
#| Módulo elástico – Absorción | -0.898 |Se observa una relación inversa fuerte entre propiedades mecánicas y variables de durabilidad.
A medida que aumenta la resistencia del hormigón:
- Disminuye la absorción de agua
- Disminuye la permeabilidad
Esto es consistente con una microestructura más densa y menos conectada, con menor porosidad efectiva.
¿Por qué tiene sentido aplicar PCA?
El PCA es útil cuando existen variables altamente correlacionadas.Todas son correlaciones muy altas. Por tanto, existe redundancia de información. podríamos resumirlas en uno o dos componentes principales.
Hipótesis previas al PCA
PC1: Representaría un eje de “calidad estructural global del hormigón”, combinando resistencia, rigidez y durabilidad (efecto inverso de la porosidad).
PC2: Podría estar asociado principalmente a la densidad, actuando como una dimensión parcialmente independiente dentro del sistema.
Paso 4: Estandarización de variables y ejecución del PCA
hormigon_scaled <- scale(hormigon)
#la función scale sirve para estandarizar las observaciones de la base de datos (paso 1 de la presentación)
pca_hormigon <- prcomp(hormigon_scaled, center = TRUE, scale. = TRUE)
#la funcion pca_hormigón crea el pca para ser analizado en base a los datos previamente estandarizados
summary(pca_hormigon)## Importance of components:
## PC1 PC2 PC3 PC4 PC5 PC6
## Standard deviation 2.3221 0.47322 0.38347 0.30083 0.28519 0.2546
## Proportion of Variance 0.8987 0.03732 0.02451 0.01508 0.01356 0.0108
## Cumulative Proportion 0.8987 0.93605 0.96056 0.97564 0.98920 1.0000El análisis de componentes principales muestra una fuerte capacidad de reducción dimensional en el conjunto de variables del hormigón.
El PC1 presenta una desviación estándar de 2.3221 y explica el 89.87 % de la varianza total, lo que indica que concentra la mayor parte de la información del sistema. El PC2 aporta un 3.73 % adicional, alcanzando una varianza acumulada de 93.61 %. A partir de este punto, los componentes restantes contribuyen marginalmente (menos del 2 % individualmente), lo que evidencia una estructura altamente concentrada en los dos primeros ejes.
Desde el punto de vista de los criterios de selección:
- Varianza explicada y acumulada
# Varianza explicada
eigenvalues <- pca_hormigon$sdev^2
var_exp <- eigenvalues / sum(eigenvalues)
# Varianza acumulada
var_cum <- cumsum(var_exp)
# Plot varianza explicada
plot(var_exp, type = "b",
pch = 19,
ylim = c(0, 1),
xlab = "Componentes principales",
ylab = "Proporción de varianza",
main = "Varianza explicada por componente")
# Plot varianza acumulada
plot(var_cum, type = "b",
pch = 19,
ylim = c(0, 1),
xlab = "Componentes principales",
ylab = "Varianza acumulada",
main = "Varianza acumulada")
# Línea de referencia 80% y 90%
abline(h = 0.80, col = "blue", lty = 2)
abline(h = 0.90, col = "red", lty = 2)
Según el Criterio de varianza acumulada: con PC1 + PC2 se supera ampliamente el umbral del 80–90 %, alcanzando más del 93 % de la información total.
- Criterio de Kaiser
# PCA ya calculado
pca_hormigon <- prcomp(hormigon_scaled, center = TRUE, scale. = TRUE)
# Autovalores
eigenvalues <- pca_hormigon$sdev^2
# Scree plot
plot(eigenvalues, type = "b",
pch = 19,
xlab = "Componentes principales",
ylab = "Autovalores",
main = "Scree Plot (Criterio de Kaiser)")
# Línea de referencia (λ = 1)
abline(h = 1, col = "red", lty = 2)
# Etiquetas de componentes
text(1:length(eigenvalues), eigenvalues,
labels = round(eigenvalues, 2),
pos = 3, cex = 0.8)
Según el Criterio de Kaiser (λ > 1): solo el primer componente cumple claramente este criterio (PC1), mientras que los restantes presentan contribuciones mucho menores, confirmando su baja relevancia explicativa.
En consecuencia, la estructura de los datos puede reducirse de forma eficiente de 6 variables originales a 2 componentes principales, sin pérdida significativa de información.
El PC1 puede interpretarse como un eje global de comportamiento del hormigón, que integra simultáneamente la variabilidad asociada a propiedades mecánicas y de durabilidad. El PC2, en cambio, actúa como una dimensión secundaria, capturando variaciones residuales no explicadas por el primer componente.
En síntesis, el PCA confirma una fuerte redundancia en los datos y valida la reducción a dos dimensiones latentes que conservan la práctica totalidad de la información estructural del sistema.
Paso 5: Cargas (Loadings)
pca_hormigon$rotation## PC1 PC2 PC3 PC4
## Resistencia_Compresion 0.4149933 -0.204668889 -0.19269051 -0.06833974
## Resistencia_Traccion 0.4148115 -0.200880123 -0.20430596 0.06003387
## Modulo_Elasticidad 0.4146411 0.007254515 0.09664826 -0.84596710
## Densidad 0.3890399 0.893933155 0.10329016 0.17811000
## Absorcion_Agua -0.4119339 0.131319269 0.55157965 -0.36048832
## Permeabilidad -0.4034143 0.318345659 -0.77257983 -0.33821633
## PC5 PC6
## Resistencia_Compresion -0.68883189 0.51923199
## Resistencia_Traccion 0.71879351 0.47494155
## Modulo_Elasticidad 0.06811362 -0.31365493
## Densidad -0.01513130 0.08312943
## Absorcion_Agua 0.05630707 0.61294640
## Permeabilidad 0.02841849 0.15438734round(pca_hormigon$rotation,3)## PC1 PC2 PC3 PC4 PC5 PC6
## Resistencia_Compresion 0.415 -0.205 -0.193 -0.068 -0.689 0.519
## Resistencia_Traccion 0.415 -0.201 -0.204 0.060 0.719 0.475
## Modulo_Elasticidad 0.415 0.007 0.097 -0.846 0.068 -0.314
## Densidad 0.389 0.894 0.103 0.178 -0.015 0.083
## Absorcion_Agua -0.412 0.131 0.552 -0.360 0.056 0.613
## Permeabilidad -0.403 0.318 -0.773 -0.338 0.028 0.154pca_2 <- prcomp(hormigon_scaled)
round(pca_2$rotation[,1:2],3)## PC1 PC2
## Resistencia_Compresion 0.415 -0.205
## Resistencia_Traccion 0.415 -0.201
## Modulo_Elasticidad 0.415 0.007
## Densidad 0.389 0.894
## Absorcion_Agua -0.412 0.131
## Permeabilidad -0.403 0.318La interpretación de las cargas (loadings) en este PCA es el paso clave para traducir los resultados estadísticos en significado ingenieril, ya que permite identificar qué variables construyen cada componente principal.
Una regla práctica en este contexto es considerar relevantes las cargas con valor absoluto mayor a 0.40, ya que indican una contribución importante al componente. Valores cercanos a ±1 implican alta influencia, mientras que valores cercanos a 0 indican poca o nula aportación.
Componente Principal 1 (PC1)
El PC1 presenta cargas muy similares en las variables mecánicas (resistencia a compresión, tracción y módulo de elasticidad ≈ 0.415), y cargas de signo opuesto en las variables relacionadas con la porosidad (absorción ≈ -0.412 y permeabilidad ≈ -0.403). Esto indica que PC1 representa un gradiente global de calidad del hormigón, donde valores altos corresponden a mayor resistencia y menor capacidad de ingreso de agua, es decir, una microestructura más densa y menos porosa.
Componente Principal 2 (PC2)
El PC2, en cambio, está dominado principalmente por la densidad (0.894), mientras que el resto de variables presentan contribuciones bajas. Esto sugiere que este componente captura una dimensión específica asociada a la variabilidad de la densidad del material, relativamente independiente del comportamiento mecánico y de la durabilidad.
En conjunto, PC1 resume el eje principal de desempeño estructural del hormigón, mientras que PC2 está dominado casi exclusivamente por la densidad, lo que indica que este componente representa una dimensión independiente del sistema
Paso 6: Obtener las coordenadas PCA
scores <- pca_2$x
head(scores)## PC1 PC2 PC3 PC4 PC5 PC6
## [1,] -0.79596653 0.91364517 0.2579978 0.18027015 -0.11914365 -0.2005113
## [2,] -0.03419425 0.45922075 0.1343231 0.13896367 0.12690979 -0.1836301
## [3,] 4.06398865 -0.12286487 0.1532219 0.05462463 -0.01024046 -0.2375767
## [4,] 0.37133096 0.07847481 0.2097345 0.46442271 -0.28416726 0.1920388
## [5,] -0.11341489 -0.10943984 0.4073276 -0.11556833 -0.05952865 0.1076443
## [6,] 4.30199601 -0.14512673 -0.2858685 -0.02059201 -0.24804922 0.1880857los Scores (o puntuaciones) son los nuevos valores que toman tus mezclas de hormigón en el nuevo espacio generado por el PCA.
Físicamente, representan la “posición” o las “coordenadas” de cada una de tus muestras dentro del nuevo sistema de ejes (PC1, PC2, etc.).
Paso 7: Graficar las mezclas en dos dimensiones
plot(scores[,1],
scores[,2],
xlab = "PC1",
ylab = "PC2",
main = "PCA de mezclas de hormigón")
text(scores[,1],
scores[,2],
labels = 1:n)
symbols(
x = 4.5,
y = -0.2,
circles = 0.8,
inches = FALSE,
add = TRUE
)
El gráfico de la PCA de las mezclas de hormigón representa la proyección de las observaciones en los dos primeros componentes principales, que concentran la mayor parte de la variabilidad del sistema. En el eje horizontal (PC1) se observa el gradiente principal del comportamiento del hormigón, asociado a su calidad estructural global, mientras que el eje vertical (PC2) recoge variaciones secundarias vinculadas principalmente a la densidad del material.
La distribución de los puntos muestra una clara dispersión a lo largo de PC1, lo que confirma que este componente es el que mejor discrimina entre mezclas. Las observaciones situadas hacia la derecha del gráfico corresponden a valores altos de PC1, es decir, mezclas con mayor resistencia y menor porosidad, mientras que las ubicadas hacia la izquierda reflejan un comportamiento mecánico más débil y mayor permeabilidad.
En particular, se identifica un grupo de observaciones en la zona derecha inferior del gráfico (resaltadas en el círculo), caracterizadas por valores elevados de PC1 y valores negativos o bajos de PC2. Este patrón sugiere mezclas con buen desempeño estructural pero con menor influencia de la densidad relativa en comparación con otras muestras. En contraste, las observaciones más centrales representan comportamientos intermedios y mayor heterogeneidad en las propiedades.
Paso 8: Biplot
biplot(pca_2,
cex = 0.8)
Es un biplot de PCA (Componentes Principales PC1 vs PC2) que combina dos cosas: la proyección de las observaciones (números 1–50) y la dirección de las variables (flechas rojas).
El gráfico corresponde a un análisis de componentes principales (PCA) representado como biplot, en el que se proyectan simultáneamente las observaciones y las variables originales sobre los dos primeros componentes (PC1 y PC2). En este caso, el primer componente principal (PC1) concentra el gradiente más importante de variabilidad del sistema y separa principalmente a las muestras en función de propiedades físicas y mecánicas, observándose que hacia el lado positivo del eje se agrupan las variables asociadas a mayor densidad, mayor rigidez o comportamiento elástico y mayor resistencia a compresión, mientras que en el lado negativo se ubican variables relacionadas con un comportamiento más permeable o menos resistente, lo que sugiere una relación inversa clara entre ambos conjuntos de propiedades. El segundo componente (PC2), en cambio, aporta una variación secundaria y menos dominante, asociada a diferencias más finas entre las muestras que no quedan completamente explicadas por el gradiente principal.
En cuanto a la distribución de las observaciones, estas aparecen relativamente concentradas alrededor del origen, lo que indica que no existen agrupaciones fuertemente separadas en el espacio definido por los dos primeros componentes, sino más bien un continuo de variación entre las muestras. Aun así, es posible distinguir que aquellas ubicadas hacia la derecha del gráfico tienden a asociarse con mayores valores de densidad, rigidez y resistencia, mientras que las situadas hacia la izquierda presentan el comportamiento contrario, más cercano a condiciones de mayor permeabilidad o menor compacidad. En conjunto, el biplot sugiere que el sistema está dominado por un eje principal que contrapone propiedades mecánicas y de compacidad frente a propiedades hidráulicas, mientras que el segundo eje solo introduce variaciones complementarias de menor peso interpretativo.