Relatório de Ciência de Dados
Cauã
2026-05-13
Relatório de Atividade
1) Manipulação de Dados
Nesta seção, carregamos o conjunto de dados mtcars, que contém informações sobre o desempenho de automóveis.
Código e Explicações
# 1. Carregar os dados
data(mtcars)
# 2. Filtrar, criar variável e ordenar
dados_processados <- mtcars %>%
filter(hp > 100) %>%
mutate(km_por_litro = round(mpg * 0.425, 2)) %>%
mutate(model = row.names(.)) %>%
select(model, hp, cyl, km_por_litro) %>%
arrange(desc(km_por_litro))
# 3. Mostrar o resultado
head(dados_processados)## model hp cyl km_por_litro
## Lotus Europa Lotus Europa 113 4 12.92
## Hornet 4 Drive Hornet 4 Drive 110 6 9.09
## Volvo 142E Volvo 142E 109 4 9.09
## Mazda RX4 Mazda RX4 110 6 8.92
## Mazda RX4 Wag Mazda RX4 Wag 110 6 8.92
## Ferrari Dino Ferrari Dino 175 6 8.372) Tabela Interativa
Abaixo, apresentamos os dados processados utilizando o pacote DT.
datatable(dados_processados,
options = list(pageLength = 5, searchHighlight = TRUE),
caption = "Tabela 1: Dados de veículos processados (HP > 100).",
colnames = c("Modelo", "Cavalos (HP)", "Cilindros", "Consumo (Km/L)"))3) Equações Complexas (LaTeX)
Abaixo estão cinco equações fundamentais na ciência de dados e estatística:
Distribuição Normal \[f(x | \mu, \sigma^2) = \frac{1}{\sqrt{2\pi\sigma^2}} e^{-\frac{(x-\mu)^2}{2\sigma^2}}\] Significado: Descreve a densidade de probabilidade de uma variável aleatória contínua.
Teorema de Bayes \[P(A|B) = \frac{P(B|A)P(A)}{P(B)}\] Significado: Permite atualizar a probabilidade de uma hipótese com novas evidências.
Função Sigmoide \[\sigma(z) = \frac{1}{1 + e^{-z}}\] Significado: Usada em Regressão Logística para converter valores em probabilidades.
Entropia de Shannon \[H(X) = -\sum_{i=1}^{n} P(x_i) \log_2 P(x_i)\] Significado: Mede a incerteza ou impureza em um conjunto de dados.
Erro Quadrático Médio (MSE) \[MSE = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2\] Significado: Avalia a qualidade de um modelo de regressão calculando a média dos erros ao quadrado.
4 ) Figuras de Ciência de Dados
Abaixo, incluímos duas imagens que representam o fluxo de trabalho e a visualização de dados na área.
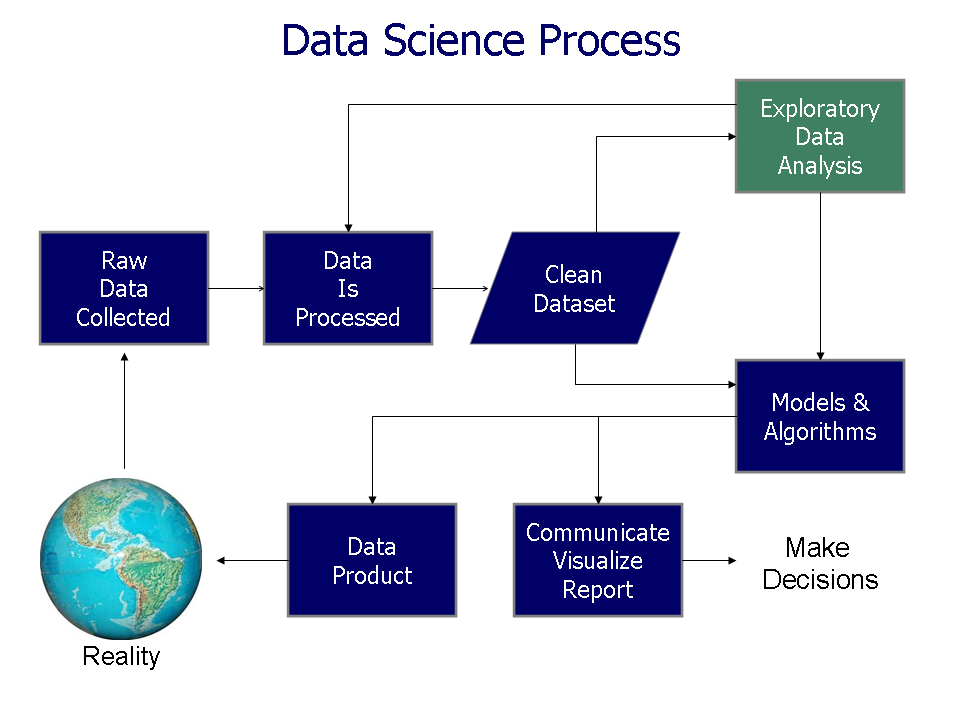

5) Referências Bibliográficas
Abaixo estão as referências bibliográficas utilizadas como base para os conceitos e recursos apresentados neste relatório:
- James, G., Witten, D., Hastie, T., & Tibshirani, R. (2013). An Introduction to Statistical Learning: with Applications in R. Springer.
- Wickham, H., & Grolemund, G. (2016). R for Data Science: Import, Tidy, Transform, Visualize, and Model Data. O’Reilly Media.
- Provost, F., & Fawcett, T. (2013). Data Science for Business: What You Need to Know about Data Mining and Data-Analytic Thinking. O’Reilly Media.
- Silver, N. (2012). The Signal and the Noise: Why So Many Predictions Fail-but Some Don’t. Penguin Books.
- O’Neil, C. (2016). Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy. Crown.
- UTFPR. Especialização em Ciência de Dados - UTFPR - 100% EaD. Disponível em: https://coens.dv.utfpr.edu.br/pos/ciencia-dados/. Acesso em: 13 mai. 2026.