Introduction to machine learning in the social sciences
ML in data analysis

What is my task informs
The ML approach to take which I
Evaluate accordingly
Supervised ML

Labelled data required in training an algorithm.
The algorithm is trained on data to predict which cases from unseen data belong to given labels.
Human evaluation is needed to ensure accurate and meaningful prediction.
Example of applications: Regression

Say, you research political themes covered in the written media in the past decades. Your sample then would be thousands of written texts.
Supervised machine learning can help with an automatic text classification.
Un-supervised ML

No labelled data available.
An algorithm is calibrated to organize data in systematic patterns.
Human evaluation is needed to ensure meaningful data organization.
Example of application: Cluster analysis

Say, you want to have the data ‘self-organize’ itself. Data from large bodies of text, big data, etc.
Unsupervised machine learning can detect clusters of meaning from large volume of data.
Data may be numeric following experimental or survey research or data may be corpi of text.
ML is a powerful approach to data analysis that involves so-called big data, often comprising millions of data points and variables.
ML may likewise be used on more ‘restrictive’ datasets with thousands of observations on tens to hundreds of variables.
ML may be an ‘overkill’ if used to analyze smaller scale data such as from individual experiments that usually involve sample sizes of hundreds of participants and has on average 10 variables.
A researcher may apply ML to predict outcomes, generate data-driven insights for theory development, or study causality.



For a comprehensive guide for applications in r see Kassambara (2017) (also the source for these images)
Discovery–Applications
Factor models
Search for a low dimensional representation of complex dimensionality in the data.
Seeks to reduce large and complex data structure to interpretable dimensions of meaning.

Measurement–Applications
Hand coding
Manual classification of observations into a set of categories that are determined before the analysis begins.
Typically, multiple coders are trained to reach a pre-determined level of agreement. But, full agreement cannot be reached and thus when interpreting results there will always be a degree of bias.
Methods have been developed to improve the results of hand coding, but clear solutions remain an ongoing task (see for a debate Chen et al., 2020).

Measurement–Applications
LASSO regression
LASSO stands for Least Absolute Schrinkage and Selection Operator and it helps with model fit improvement.
Lasso regression is a machine learning method that performs both variable selection and regularization to improve accuracy and interpretability of models.
It tends to outperform standard regression such as OLS and stepwise regression in specific situations (see Zhou et al., 2024).

Lasso seeks to balance variance reduction with model simplicity. Can be a useful tool especially in complex models with multiple variables.
More on this in the practical sessions.
Prediction–Applications
Missing values imputation
Objective latent indicators are not always available, or they are incomplete, for instance—when people cannot or are unwilling to give sensitive data.
When subjective latent indicators are available, ML can be used to predict who is not willing or cannot give data or provide distorted data.
One application would be to supplement missing values using ML.
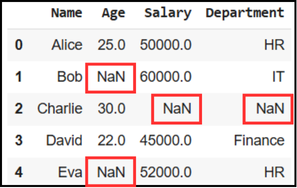
Common techniques implemented in r are:
Prediction–Applications
Generate theoretical hypotheses
Traditionally, in quantitative research, new explanatory variables are looked at to test new theoretical hypotheses.
Theoretical intuition is thus critical whereas statistical indicators such as least squares or AIC and BIC model comparisons give an indication of model adequacy.
ML can help identify adequate new explanatory variables, dimensions, while testing new theoretical hypotheses.
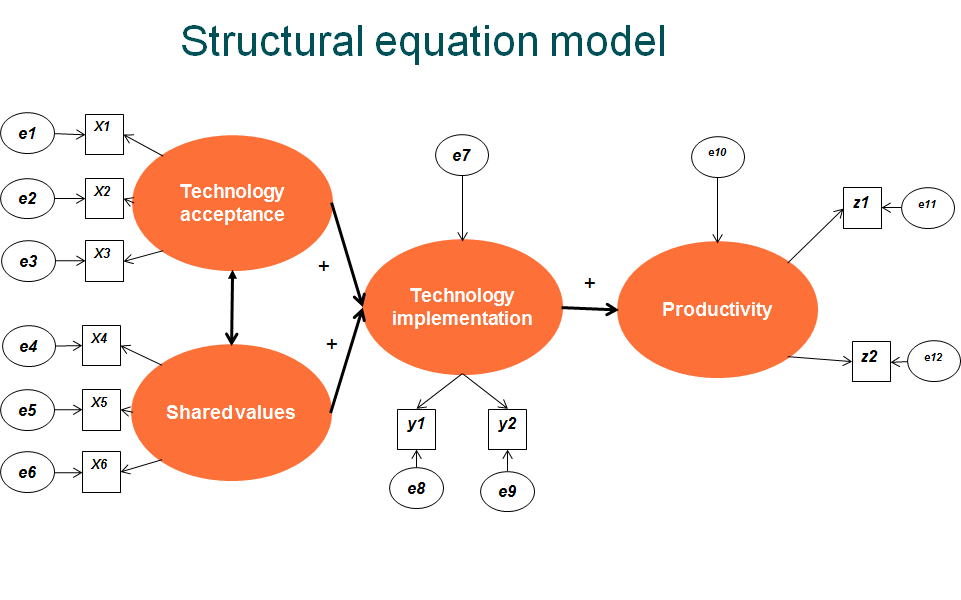
Example of application: machine learning approach to detecting model misfit in SEM, Partsch & Goretzko (2026)
Prediction–Note of caution
(David) Hume induction problem: The fact that the experience thus far has been X, it would be an assumption that the same applies hereafter. Past experience alone is insufficient to generate precise predictions – there will always be a degree of randomness.
Model overfitting: Overfit model fits itself to noise and therefore random fluctuations in the training data, misinterpreting it for signals.
Overfitting is a precision problem – too much precision of a model in explaining the outcome may be an artefact of the data looked at. Which is why sometimes, some noise is indeed a better thing to have when the goal is to have a model that holds in across datasets.

Causal–Applications
Heterogeneous treatment effects
An effect may be different across individuals or groups and thus ML may help the researcher gain insights into adaptive (individual or group specific) causal effects.
Example: “Do your civic duty – Vote!”


Sending such a mail may have greater impact in the group who voted 3 times as no backlash was observed (no red bars in the upper part of the right figure) and it is the biggest group (see box-plot in the lower part of the right figure).
Causal–Note of caution
Choices in algorithm coding may carry over implicit biases, for instance, the choice of categorizing a continuous variable such as age into age groups of young, adults, and older people will have consequences for the research field as well as policy.
Researched and discussed in the literature under the term algorithmic bias. See Kordzadeh & Ghasemaghaei (2021).
Algorithm optimization must be informed by existent literature, theory, as well as larger ethical discourses.

Note on genAI
Of course, you may use genAI to help with the code. It is inevitable at this stage.
Your decisions and interpretations are however essential. Do not accept the suggestions offered without scrutiny!
Use this prompt in genAI tools such as Microsoft Copilot.
give me a simple example of machine learning code written in r for conducting a k-means cluster analysis with the iris dataset and show me a ggplot graph at the end
Check the suggested code. Copy-paste if you wish to your r. Alternatively, use this other prompt to ask Copilot for a rendered figure.
render the ggplot for me and give me a downloadable png picture format

