
MLB Pitch Prediction Analysis
Garett Prestholdt
Project Motivation
Every time a pitch is thrown in an MLB stadium, the scoreboard flashes a classification (Sinker, Slider, 4-Seam) within seconds. As a fan, I wanted to look under the hood of that process.
- My Goal: Reverse-engineer the “black box” of Statcast to see if I can get close to the MLB model.
- Understand which variables of ball flight have the most impact in prediction.

Pitch Tracking Coordinate System
x -> the horizontal distance, from the center of homeplate
y -> the baseball’s distance from home-plate
z-> vertical distance, from middle of strikezone
- Ex: (x, z) = (0,0) would be the exact middle of the front of the strikezone

Predictor Variables (1)
ax/y/z -> acceleration of the pitch in that respective direction
release_pos_x/z -> x, z coordinates of were the ball leaves the pitchers hand
release_pos_y -> how far away from the plate the pitcher relases the ball
Predictor Variables (2)
plate_x,z -> where the pitch crosses home-plate in the x, z coordinates
api_break_x/z -> Total Horizontal/Vertical Movement
- how far the pitch moves from x, z release point to x, z plate coords, after accounting for gravity and spin
Predictor Variables (3)
pfx_x/z -> Induced Horizontal/Vertical Break
The horizontal/vertical break between release point and home plate, compared to a pitch thrown at the same speed, just with no spin.
Shows how the spin is manipulating the shape of the pitch.
release_extension -> Distance from rubber to where the pitcher releases the ball.
Spin Axis vs Spin Rate (rpm)
Release Speed -> Velocity the moment it leaves pitchers hand.

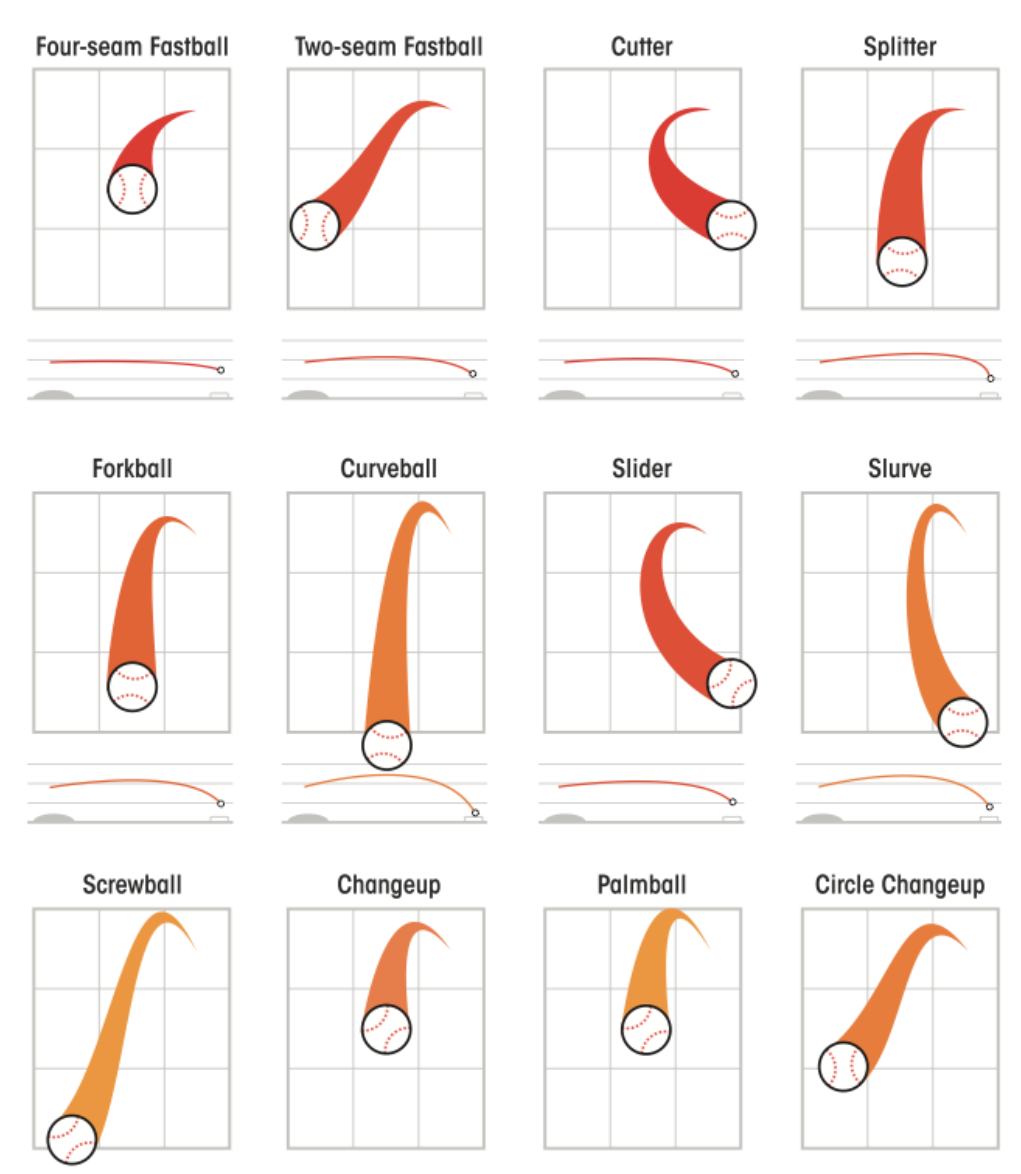
Brief Overview of Common Pitches

- Changeup: Slower, tails /down

- Fastball: Very Straight

- Curveball: Slow, lots of vertical movement

- Slider: Moderate Speed, more horizontal movement
What is PCA?
- 23D to 2D: Allows us to visualize 23 variables in 2D
- Natural Clustering: Reveals how pitches naturally group based on their physical traits.
- “Principal Components”: 23 total components combine to explain 100% of the data’s variance.
- We only plot PC1 and PC2 because they capture the vast majority of that variance.

PCA - Biplot
- Until otherwise noted, will be using data from Tarik Skubal, ~13k pitches, LHP
- Seems to be some clustering of points

PCA - Biplot
- Adding color, we see the each pitch seems to be clustering by type

PCA - Biplot
- Direction: If an arrow points toward a cluster, those pitches have higher-than-average values for that metric (e.g., higher Velocity or Spin).

CART - Decision Tree

XGBoost Decision Tree - Example

XGBoost is a collection of “smart” decision trees
“Smart” in the way that each tree tries to “learn” from the mistakes of the tree before it.
XGBoost - Variable Importance

- Variables with high importance have a high impact on seperating pitches from one another.
Generalization - Patrick Sandoval

Model Accuracy = 94.0%
Sinker(SI) did alright, misclassified often as a fastball (FF) or changeup (CH).
Sweeper (ST) not in original model
- Misclassified as Slider (SL) or Curveball (CU)
Generalization - Jake Arrieta

Model Accuracy: 19.4%, very poor
RHP and LHP throw from opposite sides
So when a RHP throws a slider it breaks left, while for a LHP it breaks right.
This will cause classification issues when trying to split on x-axis based variables.
How Large of a Sample of Pitches?


RHP using Sample of 25,000
- Model Accuracy: 86.9%

LHP using Sample of 25,000
- Model Accuracy: 90.6%

RHP vs LHP Variable Importance


- Top 5 most important variables are in different order but same in both RHP and LHP
{kind=link}
{kind=link}