Étude du lien entre le nombre de foyers bénéficiaires du RSA et le nombre d’inscrits en catégorie A chez France Travail dans la Loire de juin 2016 à novembre 2024
Auteur·rice
Frédéric Cuissinat
Date de publication
5 août 2025
Astuce
Pour visualiser le script R, cliquez sur le bouton </>Code en haut à droite de cette page ou sur les boutons triangulaires noirs placés tout au long de ce document.
Introduction.
Quelques chiffres.
Le RSA dans la Loire en novembre 2024 d’après les données de la Caisse nationale des allocations familiales :
17.858 foyers bénéficiaires.
39.863 allocatiares et ayants droit.
9.959.228 euros de budget.
Le chômage dans la Loire en novembre 2024 d’après les données de France Travail :
69.180 inscrits toutes catégories confondues.
32.800 inscrits en catégorie A.
Étude antérieure de la Cnaf.
La Caisse nationale des allocations familiales (Cnaf) avait modélisé mathématiquement au cours des années 2000 la relation au niveau national entre le nombre de personnes inscrites à l’ANPE en catégorie 1 et 6 et le nombre d’allocataires du RMI (L’équation est visible page 91 de ce document (Donné & Cazain, 2008).
L’objectif était d’investiguer l’éventuelle existence d’un lien, ainsi que sa nature et son intensite, entre chômage et RMI.
La Cnaf avait conclu que “seule une baisse suffisamment importante [du chômage] sur une longue période pouvait entraîner une diminution du nombre d’allocataires du RMI” (Donné & Cazain, 2008).
Depuis, le RSA a remplacé le RMI et de multiples politiques publiques nationales comme locales liées à l’emploi et l’insertion ont été mises en place, modifiées ou abandonnées.
Qu’en est-il aujourd’hui de la relation entre le nombre d’allocataires du RSA dans la Loire et le nombre de personnes inscrites à France Travail en catégorie A ?
Ce document se propose d’apporter quelques éléments de réponse à cette question.
Catégorisation des demandeurs d’emploi par l’ANPE devenue France Travail.
Ne sachant pas à quelles catégories de France Travail correspondent aujourd’hui les anciennes catégories 1 et 6 de l’ANPE, seule l’actuelle catégorie A (inscrits tenus de faire des actes positifs de recherche d’emploi, sans emploi) a été retenue.
Phase préparatoire à l’analyse.
Stack technique :
Langages : R - Markdown.
IDE : RStudio.
Notebook : Quarto.
Plateforme de publication : rpubs.com.
Chargement des librairies.
Les librairies logicielles suivantes nécessaires à l’analyse ont été sélectionnées et chargées : e1071, janitor, pracma, strucchange, tseries, forecast.
Show the code
# lister les librairies nécessaires à l'analyselibrairies_necessaires <-c("e1071", "janitor", "forecast", "pracma", "strucchange", "tseries")# créer une fonction qui installe et/ou charge les librairiespreparer_librairies <-function(librairie) {if (!(librairie %in%installed.packages())) {install.packages(librairie, dependencies =TRUE, clean =TRUE) }library(package = librairie,character.only =TRUE)}# préparer les librairiessapply(X = librairies_necessaires,FUN = preparer_librairies)
Acquisition et stokage des données.
Deux jeux de données ont été utilisés.
Le premier jeu concerne le nombre de foyers bénéficiares du RSA dans la Loire :
Ce jeu intitulé “Toutes prestations - Répartition des allocataires selon la prestation [Départemental]” a été obtenu au format CSV sur cette page du site open data de la Caisse nationale des allocations familiales (Cnaf).
Le second jeu concerne le nombre d’inscrits en catégorie A chez France Travail.
Ce jeu intitulé “Demandeurs d’emploi inscrits en fin de mois à France Travail, Catégorie : A par Catégorie - Département : Loire 42 - Janvier 1996 à Avril 2025 - Données brutes” a été obtenu au format CSV sur cette page du site de France Travail.
Show the code
################################################################################ ----------------------------- bénéficiaires rsa ----------------------------# ################################################################################ définir le chemin d'accès jusqu'au fichier CSV de la CNAF.chemin_benef_rsa <-"//home/frederic/Bureau/projets/RDV_CD42_Lionel_Payre/caf_benef_rsa_loire.csv"# charger le jeu de données de la CNAF dans un data frame.benef_rsa <-read.csv(file = chemin_benef_rsa,header =TRUE,sep =";",na.strings ="NA")################################################################################ ----------------- Inscrits à France Travail en catégorie A -----------------# ################################################################################ définir le chemin d'accès jusqu'au fichier CSV de l'INSEEchemin_csv_FT <-"/home/frederic/Bureau/projets/RDV_CD42_Lionel_Payre/France_Travail.csv"# charger le jeu de données de l'INSEE dans un data frame.DE_cat_A <-read.csv(chemin_csv_FT,header =TRUE,sep =";",na.strings ="NA")
Mise en forme des données.
Les données brutes ont été traitées pour permettre leur analyse.
Show the code
# supprimer la notation scientifique des valeurs pour l'ensemble du documentoptions(scipen=999)################################################################################ ----------------------------- bénéficiaires rsa ----------------------------# ################################################################################ formater les noms de variablesbenef_rsa <-clean_names(benef_rsa)# extraire les données RSA dans la Loirebenef_rsa_42 <- benef_rsa[benef_rsa$nom_departement =="LOIRE", c("date_reference", "nombre_foyers_rsa", "nombre_personnes_rsa", "montant_total_rsa")]# passer la variable date_reference au format de type "date"benef_rsa_42$date_reference <-as.Date(paste(benef_rsa_42$date_reference,"-25",sep =""))# ordonner les observations par ordre chronologiquebenef_rsa_42 <- benef_rsa_42[order(benef_rsa_42$date_reference), ]# transformer les données en un objet de type série temporellebenef_rsa_42_st <-ts(benef_rsa_42[, "nombre_foyers_rsa"],frequency=12,start=c(2016,6))################################################################################ ----------------- Inscrits à France Travail en catégorie A -----------------# ################################################################################ supprimer les espaces blancs dans les valeurs de la variable ADE_cat_A$A <-gsub(DE_cat_A$A,pattern =" ",replacement ="")# passer la variable A en type "numeric"DE_cat_A$A <-as.numeric(DE_cat_A$A)# transformer les données en un objet de type série temporelleDE_cat_A_st <-ts(DE_cat_A$A,frequency=12,start=c(2016,6))
Les repères verticaux marquent les dates de début et de fin des 3 confinements.
Show the code
# afficher la courbe du nombre de bénéficiaires du RSAplot(x = benef_rsa_42$date_reference,y = benef_rsa_42$nombre_foyers_rsa,type ="l",main ="Nombre de foyers bénéficiaires du RSA dans la Loire\nde juin 2016 à novembre 2024",xlab ="",ylab ="",col =4,lwd =2,las =2,ylim =c(15000, 19000))# ajouter des repères verticaux aux dates des 3 confinementsabline(v =as.Date(c("2020-03-17", "2020-05-11","2020-10-30", "2020-12-15","2021-04-03", "2021-05-03")))# découper les données en periodes temporellesperiode2018_2020 <- benef_rsa_42[benef_rsa_42$date_reference >="2018-01-25"& benef_rsa_42$date_reference <="2020-01-25", ]periode2024 <- benef_rsa_42[benef_rsa_42$date_reference >="2024-01-25", ]# afficher la droite de régression pour chaque périodeabline(reg =lm(periode2018_2020$nombre_foyers_rsa ~ periode2018_2020$date_reference),col =3,lwd =2)abline(reg =lm(periode2024$nombre_foyers_rsa ~ periode2024$date_reference),col =2,lwd =2)
Indicateurs de tendance, dispersion, position et forme.
Show the code
moyenne <-round(mean(benef_rsa_42_st), digits =0)
En moyenne 16958 bénéficiaires par mois sur la période juin 2016 à novembre 2024.
Show the code
# afficher le résumé en 5 valeurs de Tukeysummary(benef_rsa_42_st)
Min. 1st Qu. Median Mean 3rd Qu. Max.
16386 16600 16843 16958 17156 18252
Show the code
# afficher l'histogramme de la distributionhist(benef_rsa_42_st,breaks ="Sturges",main ="Distibution du nombre de foyers bénéficiaires du RSA dans la Loire\njuin 2016 à novembre 2024",xlab ="",ylab ="Fréquence relative en %",col =4,ylim =c(0, 30),xlim =c(16000, 18500))# ajouter un repère vertical au niveau de la moyenneabline(v =mean(benef_rsa_42_st),col =2)# ajouter un repère vertical au niveau de la médianneabline(v =median(benef_rsa_42_st),col =2)
Show the code
round(kurtosis(benef_rsa_42_st), digits =2)
[1] 0.71
Show the code
round(skewness(benef_rsa_42_st), digits =2)
[1] 1.13
Show the code
# effectuer une test de normalitéshapiro.test(x = benef_rsa_42$nombre_foyers_rsa)
Shapiro-Wilk normality test
data: benef_rsa_42$nombre_foyers_rsa
W = 0.8928, p-value = 0.0000005324
Taux d’évolution.
Show the code
# calculer le taux d'évolution entre janvier 2018 et le maximum atteint pendant le COVIDval_min_covid <-min(benef_rsa_42$nombre_foyers_rsa[benef_rsa_42$date_reference >=as.Date("2020-01-25")])val_max_covid <-max(benef_rsa_42$nombre_foyers_rsa[benef_rsa_42$date_reference <="2022-09-25"])taux_evo_covid <-round(((val_max_covid - val_min_covid) / val_min_covid) *100, digits =1)
Taux d’évolution entre janvier 2020 et le maximum atteint pendant le COVID : 9.2%.
Show the code
# calculer le taux d'évolution entre janvier 2018 et le maximum atteint pendant le COVIDmin_max_2024 <-range(benef_rsa_42$nombre_foyers_rsa[benef_rsa_42$date_reference >=as.Date("2024-01-25")])taux_evo_2024 <-round(((min_max_2024[2] - min_max_2024[1]) / min_max_2024[1]) *100, digits =1)
Taux d’évolution entre janvier 2024 et novembre 2024 : 4.5%.
Autocorrélation.
Show the code
Acf(benef_rsa_42_st,main ="",lag.max =60)
Show the code
Pacf(benef_rsa_42_st,main ="",lag.max =5)
Décomposition.
Show the code
# décomposer la série temporelle selon un modèle multiplicatifdecompo_multi <-decompose(benef_rsa_42_st,type ="multiplicative")plot(decompo_multi,xlab ="",ylab ="",col =4)
Changements structurels
Show the code
# calculer les points d'inflexionpts_inflex <-breakpoints(benef_rsa_42_st ~1)# afficher la courbe du RSAplot(benef_rsa_42_st,xlab ="",ylab ="")# ajouter les points d'inflexion ...lines(fitted(pts_inflex),col =2,lwd =3)# ... et leurs intervales de confiancelines(confint(pts_inflex),col =3,lwd =3)
Changements de tendance :
Show the code
# créer un vecteur numérotant les mois de 1 à 102t <-1:length(benef_rsa_42_st)# calculer les changements structurauxpts_inflex <-breakpoints(benef_rsa_42_st ~ t)# afficher la série temporelle...plot(benef_rsa_42_st,xlab ="",ylab ="")# ...puis ajouterles changements structuraux...lines(fitted(pts_inflex),col =2,lwd =3)# ...et enfin ajouter leurs intervales de confiancelines(confint(pts_inflex),col =3,lwd =3)
Stationarité.
Show the code
boxplot(benef_rsa_42_st ~cycle(benef_rsa_42_st),col =4,main ="Nombre de bénéficiaires du RSA dans la Loire\njuin 2016 à octobre 2024",xlab ="Mois",ylab ="",outline =FALSE)
Show the code
# effectuer un test augmenté de Dickey-Fuller adf.test(benef_rsa_42_st)
Augmented Dickey-Fuller Test
data: benef_rsa_42_st
Dickey-Fuller = -2.4416, Lag order = 4, p-value = 0.3936
alternative hypothesis: stationary
Show the code
# stoker la valeur p dans une variableval_pp_DF <-adf.test(benef_rsa_42_st)$p.value
Décomposition en fréquences.
Show the code
## appliqyuer la transformation de Fourier rapide ts_vers_freq <-fft(benef_rsa_42$nombre_foyers_rsa)# obtenir la valeur absolue des valeurs de la décomposition fréquentielleval_abs_fft <-abs(ts_vers_freq)# extraire le coté droit de la symétriets_vers_freq_abs_droit <- val_abs_fft[1:(length(val_abs_fft)/2+1)]# afficher les valeurs des picspics <-findpeaks(ts_vers_freq_abs_droit) # afficher les fréquences de basesfreq_base <- pics -1colnames(freq_base) <-c("amplitude", "pic en Hz", "début du pic en Hz", "fin du pic en Hz")freq_base
# afficher la décomposition fréquentielleplot(abs(ts_vers_freq),type="l",xlab="Fréquence", ylab="Amplitude",xlim =c(0, 50))
Valeurs corrigées des variations saisonnières.
Show the code
# corriger les valeurs des variations saisonnièresbenef_rsa_42_st_cvs <- decompo_multi$x / decompo_multi$seasonal# afficher les valeurs corrigées des variations saisonnièresplot(x = benef_rsa_42$date_reference,y = benef_rsa_42_st_cvs |>as.vector(),type ="l",main ="Nombre de bénéficiaires du RSA dans la Loire\njuin 2016 à octobre 2024\nvaleurs corrigées des variations saisonnières",xlab ="",ylab ="Nombre de beneficiaires",col =4,lwd =2,las =2)
Prédictions à 3 mois.
Show the code
# modèliser les valeurs par lissage exponentiel de Holt-Wintersmodele_previsio_42 <-HoltWinters(benef_rsa_42_st,seasonal ="multiplicative")# calculer les prédictions à 3 mois à partir du modèlepredictions_3_mois_42 <-predict(modele_previsio_42,3,prediction.interval =TRUE,level =0.95)# afficher les prédictions à 3 moispredictions_3_mois_42 |>round()
fit upr lwr
Dec 2024 17837 18025 17648
Jan 2025 17825 18156 17494
Feb 2025 17844 18333 17354
# déterminer le modèle ARIMA pour la prédictionaa <-auto.arima(DE_cat_A$A)# pre-whitening x (inscrits en catégorie A)pwx <- aa$residuals#pre-whitening y (foyers bénéficiaires du RSA)newpwy =filter(benef_rsa_42$nombre_foyers_rsa, filter =c(1,-(1+coef(aa)[1]),coef(aa)[1]), sides =1)# afficher la corrélation croisée bénéficiaires du RSA vs. inscrits en catégorie ACcf(pwx, newpwy,na.action=na.omit,main ="Corrélation croisée\ninscrits en catégorie A vs. bénéficiaires du RSA",lag.max =20)
Conclusions chômage vs. RSA.
Corrélation n’est pas nécessairement causalité !
Ce n’est pas parce que 2 variables sont liées que l’une influence nécessairement l’autre.
Ces 2 variables peuvent être toutes les 2 les conséquences d’un 3ème élément.
Data science.
La réalisation d’une étude comme celle ci nécessite des compétences en data science.
Qu’est-ce que la data science ?
Des techniques …
La data science ce sont des techniques issues de plusieurs domaines :
… des compétences …
Le recours à ces techniques nécessite des compétences techniques diverses :
… des résultats.
La data science est un outil d’aide à la prise de décision grâce à des analyses à forte valeur ajoutée :
Code source
---title: "Trame pour entretien au Conseil Départemental de la Loire"subtitle: "Étude du lien entre le nombre de foyers bénéficiaires du RSA et le nombre d'inscrits en catégorie A chez France Travail dans la Loire de juin 2016 à novembre 2024"author: "Frédéric Cuissinat"format: htmllink-external-newwindow: trueeditor: visualtoc: truetoc-depth: 3toc-title: "Table des matières"toc-location: leftdate: last-modifiedlang: frcode-fold: truecode-summary: "Show the code"code-overflow: wrapcode-tools: truebibliography: references.bib---::: callout-tipPour visualiser le script R, cliquez sur le bouton \</\>Code en haut à droite de cette page ou sur les boutons triangulaires noirs placés tout au long de ce document.:::## Introduction.### Quelques chiffres.Le RSA dans la Loire en novembre 2024 d'après les données de la Caisse nationale des allocations familiales :- 17.858 foyers bénéficiaires.- 39.863 allocatiares et ayants droit.- 9.959.228 euros de budget.Le chômage dans la Loire en novembre 2024 d'après les données de France Travail :- 69.180 inscrits toutes catégories confondues.- 32.800 inscrits en catégorie A.### Étude antérieure de la Cnaf.La Caisse nationale des allocations familiales (Cnaf) avait modélisé mathématiquement au cours des années 2000 la relation au niveau national entre le nombre de personnes inscrites à l'ANPE en catégorie 1 et 6 et le nombre d'allocataires du RMI (L'équation est visible page 91 de ce document [(Donné & Cazain, 2008)](https://www.persee.fr/doc/caf_1149-1590_2008_num_91_1_2347).L'objectif était d'investiguer l'éventuelle existence d'un lien, ainsi que sa nature et son intensite, entre chômage et RMI.La Cnaf avait conclu que "seule une baisse suffisamment importante \[du chômage\] sur une longue période pouvait entraîner une diminution du nombre d’allocataires du RMI" (Donné & Cazain, 2008).Depuis, le RSA a remplacé le RMI et de multiples politiques publiques nationales comme locales liées à l'emploi et l'insertion ont été mises en place, modifiées ou abandonnées.Qu'en est-il aujourd'hui de la relation entre le nombre d'allocataires du RSA dans la Loire et le nombre de personnes inscrites à France Travail en catégorie A ?Ce document se propose d'apporter quelques éléments de réponse à cette question.::: callout-note### Catégorisation des demandeurs d'emploi par l'ANPE devenue France Travail.Ne sachant pas à quelles catégories de France Travail correspondent aujourd'hui les anciennes catégories 1 et 6 de l'ANPE, seule l'actuelle catégorie A (inscrits tenus de faire des actes positifs de recherche d'emploi, sans emploi) a été retenue.:::## Phase préparatoire à l'analyse.Stack technique :- Langages : R - Markdown.- IDE : RStudio.- Notebook : Quarto.- Plateforme de publication : rpubs.com.### Chargement des librairies.Les librairies logicielles suivantes nécessaires à l'analyse ont été sélectionnées et chargées : e1071, janitor, pracma, strucchange, tseries, forecast.```{r, output=FALSE}# lister les librairies nécessaires à l'analyselibrairies_necessaires <- c("e1071", "janitor", "forecast", "pracma", "strucchange", "tseries")# créer une fonction qui installe et/ou charge les librairiespreparer_librairies <- function(librairie) { if (!(librairie %in% installed.packages())) { install.packages(librairie, dependencies = TRUE, clean = TRUE) } library(package = librairie, character.only = TRUE)}# préparer les librairiessapply(X = librairies_necessaires, FUN = preparer_librairies)```### Acquisition et stokage des données.Deux jeux de données ont été utilisés.Le premier jeu concerne le nombre de foyers bénéficiares du RSA dans la Loire :- Ce jeu intitulé "Toutes prestations - Répartition des allocataires selon la prestation \[Départemental\]" a été obtenu au format CSV sur [cette page](https://data.caf.fr/explore/dataset/s_ben_dep/export/?disjunctive.lieures&refine.lieures=AUVERGNE+RHONE+ALPES%2FLOIRE&sort=dtreffre) du site open data de la Caisse nationale des allocations familiales (Cnaf).Le second jeu concerne le nombre d'inscrits en catégorie A chez France Travail.- Ce jeu intitulé "Demandeurs d’emploi inscrits en fin de mois à France Travail, Catégorie : A par Catégorie - Département : Loire 42 - Janvier 1996 à Avril 2025 - Données brutes" a été obtenu au format CSV sur [cette page](https://statistiques.francetravail.org/stmt/defm?ff=A&fh=1&fj=42&lf=0&ss=1) du site de France Travail.```{r}################################################################################ ----------------------------- bénéficiaires rsa ----------------------------# ################################################################################ définir le chemin d'accès jusqu'au fichier CSV de la CNAF.chemin_benef_rsa <-"//home/frederic/Bureau/projets/RDV_CD42_Lionel_Payre/caf_benef_rsa_loire.csv"# charger le jeu de données de la CNAF dans un data frame.benef_rsa <-read.csv(file = chemin_benef_rsa,header =TRUE,sep =";",na.strings ="NA")################################################################################ ----------------- Inscrits à France Travail en catégorie A -----------------# ################################################################################ définir le chemin d'accès jusqu'au fichier CSV de l'INSEEchemin_csv_FT <-"/home/frederic/Bureau/projets/RDV_CD42_Lionel_Payre/France_Travail.csv"# charger le jeu de données de l'INSEE dans un data frame.DE_cat_A <-read.csv(chemin_csv_FT,header =TRUE,sep =";",na.strings ="NA")```### Mise en forme des données.Les données brutes ont été traitées pour permettre leur analyse.```{r}# supprimer la notation scientifique des valeurs pour l'ensemble du documentoptions(scipen=999)################################################################################ ----------------------------- bénéficiaires rsa ----------------------------# ################################################################################ formater les noms de variablesbenef_rsa <-clean_names(benef_rsa)# extraire les données RSA dans la Loirebenef_rsa_42 <- benef_rsa[benef_rsa$nom_departement =="LOIRE", c("date_reference", "nombre_foyers_rsa", "nombre_personnes_rsa", "montant_total_rsa")]# passer la variable date_reference au format de type "date"benef_rsa_42$date_reference <-as.Date(paste(benef_rsa_42$date_reference,"-25",sep =""))# ordonner les observations par ordre chronologiquebenef_rsa_42 <- benef_rsa_42[order(benef_rsa_42$date_reference), ]# transformer les données en un objet de type série temporellebenef_rsa_42_st <-ts(benef_rsa_42[, "nombre_foyers_rsa"],frequency=12,start=c(2016,6))################################################################################ ----------------- Inscrits à France Travail en catégorie A -----------------# ################################################################################ supprimer les espaces blancs dans les valeurs de la variable ADE_cat_A$A <-gsub(DE_cat_A$A,pattern =" ",replacement ="")# passer la variable A en type "numeric"DE_cat_A$A <-as.numeric(DE_cat_A$A)# transformer les données en un objet de type série temporelleDE_cat_A_st <-ts(DE_cat_A$A,frequency=12,start=c(2016,6))```## Foyers bénéficiaires du RSA.Nombre de foyers bénéficiaires du RSA par mois :```{r}benef_rsa_42_st```Les **repères verticaux** marquent les dates de début et de fin des **3 confinements**.```{r}# afficher la courbe du nombre de bénéficiaires du RSAplot(x = benef_rsa_42$date_reference,y = benef_rsa_42$nombre_foyers_rsa,type ="l",main ="Nombre de foyers bénéficiaires du RSA dans la Loire\nde juin 2016 à novembre 2024",xlab ="",ylab ="",col =4,lwd =2,las =2,ylim =c(15000, 19000))# ajouter des repères verticaux aux dates des 3 confinementsabline(v =as.Date(c("2020-03-17", "2020-05-11","2020-10-30", "2020-12-15","2021-04-03", "2021-05-03")))# découper les données en periodes temporellesperiode2018_2020 <- benef_rsa_42[benef_rsa_42$date_reference >="2018-01-25"& benef_rsa_42$date_reference <="2020-01-25", ]periode2024 <- benef_rsa_42[benef_rsa_42$date_reference >="2024-01-25", ]# afficher la droite de régression pour chaque périodeabline(reg =lm(periode2018_2020$nombre_foyers_rsa ~ periode2018_2020$date_reference),col =3,lwd =2)abline(reg =lm(periode2024$nombre_foyers_rsa ~ periode2024$date_reference),col =2,lwd =2)```### Indicateurs de tendance, dispersion, position et forme.```{r}moyenne <-round(mean(benef_rsa_42_st), digits =0)```En moyenne `{r} moyenne` bénéficiaires par mois sur la période juin 2016 à novembre 2024.```{r}# afficher le résumé en 5 valeurs de Tukeysummary(benef_rsa_42_st)``````{r}# afficher l'histogramme de la distributionhist(benef_rsa_42_st,breaks ="Sturges",main ="Distibution du nombre de foyers bénéficiaires du RSA dans la Loire\njuin 2016 à novembre 2024",xlab ="",ylab ="Fréquence relative en %",col =4,ylim =c(0, 30),xlim =c(16000, 18500))# ajouter un repère vertical au niveau de la moyenneabline(v =mean(benef_rsa_42_st),col =2)# ajouter un repère vertical au niveau de la médianneabline(v =median(benef_rsa_42_st),col =2)``````{r}round(kurtosis(benef_rsa_42_st), digits =2)``````{r}round(skewness(benef_rsa_42_st), digits =2)```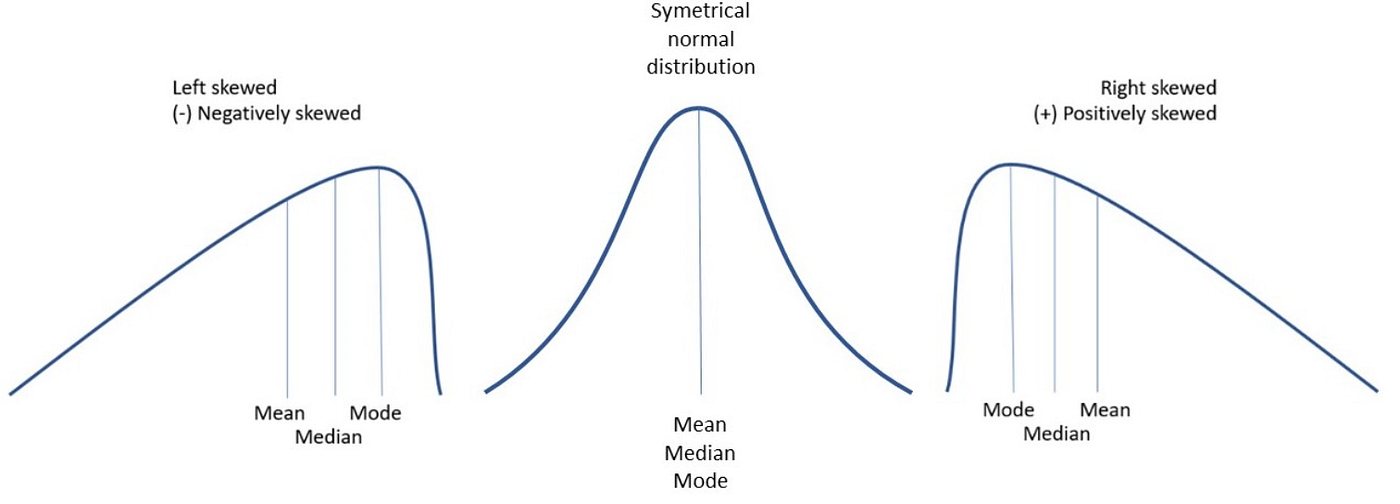```{r}# effectuer une test de normalitéshapiro.test(x = benef_rsa_42$nombre_foyers_rsa)```### Taux d'évolution.```{r}# calculer le taux d'évolution entre janvier 2018 et le maximum atteint pendant le COVIDval_min_covid <-min(benef_rsa_42$nombre_foyers_rsa[benef_rsa_42$date_reference >=as.Date("2020-01-25")])val_max_covid <-max(benef_rsa_42$nombre_foyers_rsa[benef_rsa_42$date_reference <="2022-09-25"])taux_evo_covid <-round(((val_max_covid - val_min_covid) / val_min_covid) *100, digits =1)```Taux d'évolution entre janvier 2020 et le maximum atteint pendant le COVID : `{r} taux_evo_covid`%.```{r}# calculer le taux d'évolution entre janvier 2018 et le maximum atteint pendant le COVIDmin_max_2024 <-range(benef_rsa_42$nombre_foyers_rsa[benef_rsa_42$date_reference >=as.Date("2024-01-25")])taux_evo_2024 <-round(((min_max_2024[2] - min_max_2024[1]) / min_max_2024[1]) *100, digits =1)```Taux d'évolution entre janvier 2024 et novembre 2024 : `{r} taux_evo_2024`%.### Autocorrélation.```{r}Acf(benef_rsa_42_st,main ="",lag.max =60)``````{r}Pacf(benef_rsa_42_st,main ="",lag.max =5)```### Décomposition.```{r}# décomposer la série temporelle selon un modèle multiplicatifdecompo_multi <-decompose(benef_rsa_42_st,type ="multiplicative")plot(decompo_multi,xlab ="",ylab ="",col =4)```### Changements structurels```{r}# calculer les points d'inflexionpts_inflex <-breakpoints(benef_rsa_42_st ~1)# afficher la courbe du RSAplot(benef_rsa_42_st,xlab ="",ylab ="")# ajouter les points d'inflexion ...lines(fitted(pts_inflex),col =2,lwd =3)# ... et leurs intervales de confiancelines(confint(pts_inflex),col =3,lwd =3)```Changements de tendance :```{r}# créer un vecteur numérotant les mois de 1 à 102t <-1:length(benef_rsa_42_st)# calculer les changements structurauxpts_inflex <-breakpoints(benef_rsa_42_st ~ t)# afficher la série temporelle...plot(benef_rsa_42_st,xlab ="",ylab ="")# ...puis ajouterles changements structuraux...lines(fitted(pts_inflex),col =2,lwd =3)# ...et enfin ajouter leurs intervales de confiancelines(confint(pts_inflex),col =3,lwd =3)```### Stationarité.```{r}boxplot(benef_rsa_42_st ~cycle(benef_rsa_42_st),col =4,main ="Nombre de bénéficiaires du RSA dans la Loire\njuin 2016 à octobre 2024",xlab ="Mois",ylab ="",outline =FALSE)``````{r}# effectuer un test augmenté de Dickey-Fuller adf.test(benef_rsa_42_st)# stoker la valeur p dans une variableval_pp_DF <-adf.test(benef_rsa_42_st)$p.value```### Décomposition en fréquences.```{r}## appliqyuer la transformation de Fourier rapide ts_vers_freq <-fft(benef_rsa_42$nombre_foyers_rsa)# obtenir la valeur absolue des valeurs de la décomposition fréquentielleval_abs_fft <-abs(ts_vers_freq)# extraire le coté droit de la symétriets_vers_freq_abs_droit <- val_abs_fft[1:(length(val_abs_fft)/2+1)]# afficher les valeurs des picspics <-findpeaks(ts_vers_freq_abs_droit) # afficher les fréquences de basesfreq_base <- pics -1colnames(freq_base) <-c("amplitude", "pic en Hz", "début du pic en Hz", "fin du pic en Hz")freq_base``````{r}# afficher la décomposition fréquentielleplot(abs(ts_vers_freq),type="l",xlab="Fréquence", ylab="Amplitude",xlim =c(0, 50))```### Valeurs corrigées des variations saisonnières.```{r}# corriger les valeurs des variations saisonnièresbenef_rsa_42_st_cvs <- decompo_multi$x / decompo_multi$seasonal# afficher les valeurs corrigées des variations saisonnièresplot(x = benef_rsa_42$date_reference,y = benef_rsa_42_st_cvs |>as.vector(),type ="l",main ="Nombre de bénéficiaires du RSA dans la Loire\njuin 2016 à octobre 2024\nvaleurs corrigées des variations saisonnières",xlab ="",ylab ="Nombre de beneficiaires",col =4,lwd =2,las =2)```### Prédictions à 3 mois.```{r}# modèliser les valeurs par lissage exponentiel de Holt-Wintersmodele_previsio_42 <-HoltWinters(benef_rsa_42_st,seasonal ="multiplicative")# calculer les prédictions à 3 mois à partir du modèlepredictions_3_mois_42 <-predict(modele_previsio_42,3,prediction.interval =TRUE,level =0.95)# afficher les prédictions à 3 moispredictions_3_mois_42 |>round()```## Lien entre chômage et RSA.### Visualisation graphique.```{r}matrice <-matrix(data =c(DE_cat_A$A, benef_rsa_42$nombre_foyers_rsa), ncol =2, byrow =FALSE)matrice_st <-ts(matrice,frequency=12,start=c(2016,6))colnames(matrice_st) <-c("Catégorie A", "RSA")plot(matrice_st,yax.flip =TRUE,main ="")```### Corrélation croisée.```{r}# déterminer le modèle ARIMA pour la prédictionaa <-auto.arima(DE_cat_A$A)# pre-whitening x (inscrits en catégorie A)pwx <- aa$residuals#pre-whitening y (foyers bénéficiaires du RSA)newpwy =filter(benef_rsa_42$nombre_foyers_rsa, filter =c(1,-(1+coef(aa)[1]),coef(aa)[1]), sides =1)# afficher la corrélation croisée bénéficiaires du RSA vs. inscrits en catégorie ACcf(pwx, newpwy,na.action=na.omit,main ="Corrélation croisée\ninscrits en catégorie A vs. bénéficiaires du RSA",lag.max =20)```## Conclusions chômage vs. RSA.::: callout-important### Corrélation n'est pas nécessairement causalité !Ce n'est pas parce que 2 variables sont liées que l'une influence nécessairement l'autre.Ces 2 variables peuvent être toutes les 2 les conséquences d'un 3ème élément.:::## Data science.La réalisation d'une étude comme celle ci nécessite des compétences en data science.Qu'est-ce que la data science ?### Des techniques ...La data science ce sont des techniques issues de plusieurs domaines :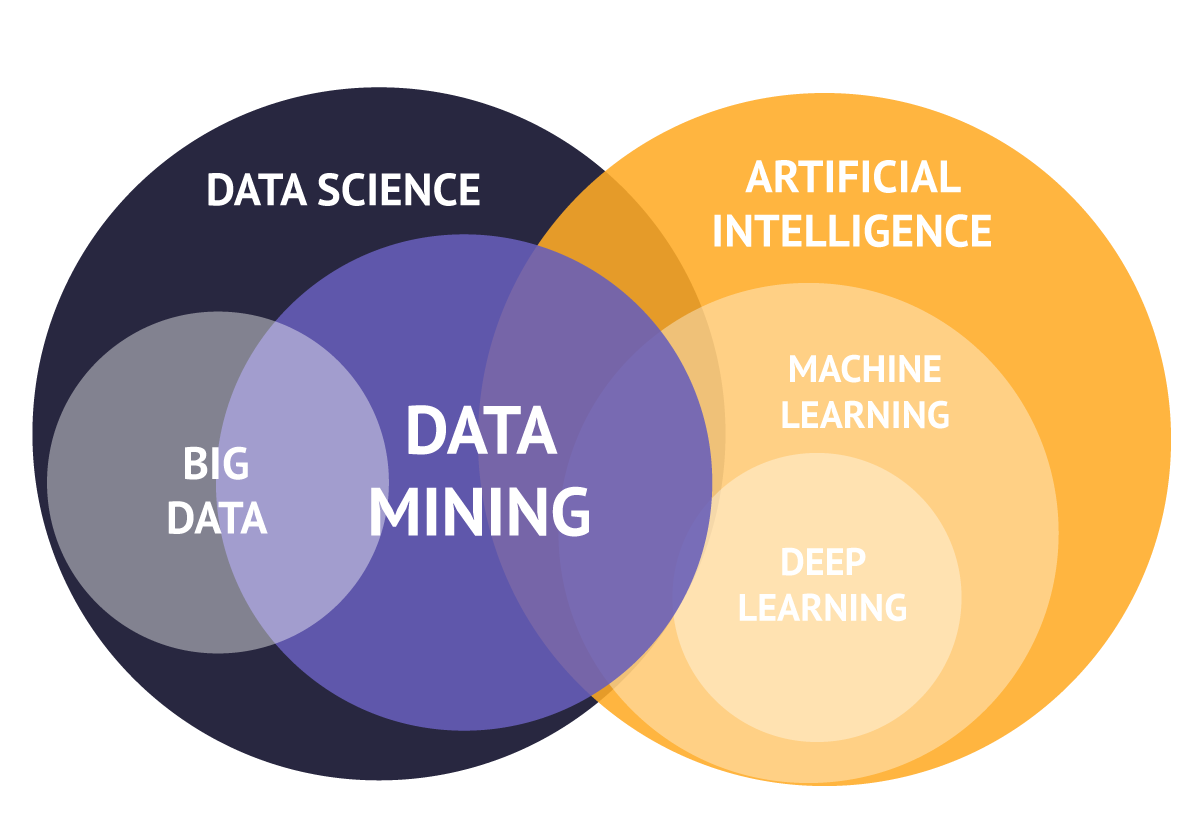### ... des compétences ...Le recours à ces techniques nécessite des compétences techniques diverses :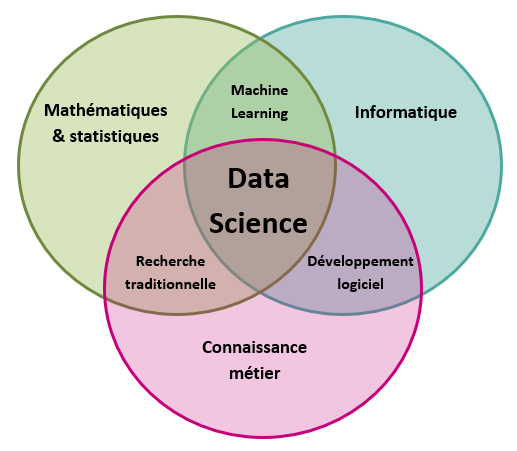### ... des résultats.La data science est un outil d'aide à la prise de décision grâce à des analyses à forte valeur ajoutée :