Manejo de datos en el tidyverse
José Antonio Ortega
jueves, 19 de septiembre de 2024
Manejo de datos con R
En esta presentación vamos a ver casos prácticos de manejo de datos
en R utilizando las bibliotecas que constituyen el
tidyverse. No importa en qué formato estén los datos
originales, el objetivo es llevarlos a un objeto de datos,
data.frame o, preferiblemente tibble, que esté
en forma ordenada (tidy).
Las herramientas básicas para trabajar con los datos están incluidas en los paquetes incluidos en el tidyverse:
- tibble para trabajar con datos de esa clase genérica,
- tidyr para llevar los datos a una forma ordenada -que dependerá de cada aplicación-,
- dplyr para cambiar los objetos de datos y para obtener resúmenes de los objetos de datos.
Lectura de datos
En general queremos importar datos en R en un formato
data.frame o asociados (tibble), que permiten
luego trabajar de forma fácil con ellos. Básicamente tenemos las
siguientes alternativas:
| Procedencia | ¿Cómo leerlos? | Ejemplo |
|---|---|---|
| Un paquete de R | library(lib);data(df) |
data(cars) |
| Un fichero: | Paquetes: | |
| csv,fwf,txt | readr |
read_table("data.txt") |
| SPSS,SAS,… | haven |
read_sav("data.sav") |
| xls, xlsx | readxl |
read_excel("data.xls",skip=10) |
| Cualquiera | rio |
import("data.csv") |
| pcAxis (INE) | pxR |
read.px("data.px") |
| Una página web: | Paquetes: | |
| html | rvest |
read_html(url) |
| JSON | jsonlite |
fromJSON(url) |
De ellas, readr forma parte del tidyverse. Además son
útiles, para descargar desde una página web un fichero,
download.file y para descomprimirlo unzip. Si
trabajamos en RStudio, para la mayor parte de los objetos de datos, si
hacemos click en el nombre fichero en la pestaña [Files] nos proporciona
la opción de importarlo [Import Dataset]. Esto nos abre un menú de
contexto en el que previsualiza los datos, podemos configurar las
opciones, nos muestra el código de R para cargarlo, y nos permite
importarlos. Vamos a ver dos ejemplos característicos, un fichero
csv y un fichero pcAxis.
Ejemplo 1: csv: Carga de la base de datos del Human Development Index
Los Informes de desarrollo humano presentan cada año una evaluación del desempeño de todos los países del mundo en base al Índice de Desarrollo Humano y otros indicadores. Los datos correspondiente al último año son accesibles en formato excel en el centro de datos asociado. Es posible importar la base de datos completa en formato csv (valores separados por comas) en este enlace.
 Fuente: https://www.youtube.com/watch?v=SaHIUR9jIPY
Fuente: https://www.youtube.com/watch?v=SaHIUR9jIPY
Para cargar los datos en R, podemos guardar el fichero en nuestro
ordenador (a mano o utilizando R), e importarlo desde R. Para descargar
el fichero podemos utilizar la función download.file, que
tiene como primer argumento la url, y como segundo el nombre del fichero
de destino.
library(tidyverse)
download.file("https://hdr.undp.org/sites/default/files/2021-22_HDR/HDR21-22_Composite_indices_complete_time_series.csv", "HDI.csv")
hdi <- read_csv("HDI.csv")## ── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
## ✔ dplyr 1.1.4 ✔ readr 2.1.5
## ✔ forcats 1.0.0 ✔ stringr 1.5.1
## ✔ ggplot2 3.5.1 ✔ tibble 3.2.1
## ✔ lubridate 1.9.3 ✔ tidyr 1.3.1
## ✔ purrr 1.0.2
## ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::lag() masks stats::lag()
## ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
## Rows: 206 Columns: 1008
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## chr (4): iso3, country, hdicode, region
## dbl (1004): hdi_rank_2021, hdi_1990, hdi_1991, hdi_1992, hdi_1993, hdi_1994,...
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.En la función read_csv solo hemos tenido que identificar
el fichero. Los valores por defecto funcionan bien. Entre los argumentos
que se pueden cambiar, con datos españoles es muy frecuente que el
separador sea el punto y coma (;) en vez de la coma, para permitir ésta
en números decimales con la coma como separador. En este caso tendríamos
que cambiar el argumento de Delimiter a
semicolon. Para ver los argumentos que admite la función
read_excel, o cualquier otra función, tenemos que
escribir
args(read_csv)## function (file, col_names = TRUE, col_types = NULL, col_select = NULL,
## id = NULL, locale = default_locale(), na = c("", "NA"), quoted_na = TRUE,
## quote = "\"", comment = "", trim_ws = TRUE, skip = 0, n_max = Inf,
## guess_max = min(1000, n_max), name_repair = "unique", num_threads = readr_threads(),
## progress = show_progress(), show_col_types = should_show_types(),
## skip_empty_rows = TRUE, lazy = should_read_lazy())
## NULLo si queremos la página de ayuda
help(read_csv)Comprobamos que por defecto read_csv carga las variables
asumiendo que la primera fila son los nombres de las columnas, y que el
tipo de datos de cada columna debe identificarlo la propia función.
Muchas veces es útil especficar skip, para ignorar las
primeras filas cuando los datos comienzan más abajo.
El resultado de read_csv ya es una tibble o
tbl_df preparada para trabajar con dplyrde 206
filas y 1008 columnas. Una de las utilidades añadidas de los objetos de
este tipo es que, cuando los imprimimos, no debemos temer que se nos
inunde la consola con un objeto enorme, sino que por defecto muestra las
primeras filas y las primeras columnas, y nos informa del resto. Podemos
también ver la estructura con str pero sólo de las primeras
columnas:
str(hdi)En este caso vemos que la estructura de los datos está en una forma muy ancha. Los nombres de las columnas tienen un prefijo que denota de qué variable se trata, a veces el sexo, separados por “_“, y el año de observación desde 1990. Las filas se corresponden con países, de modo que hay una única fila por país.
Ejemplo 2: Fichero pc-Axis desde el INE
En las páginas de datos del INE podemos ver que hay un enlace a
ficheros PC-AXIS. Estos ficheros los podemos leer en R con el paquete
pxR. Por ejemplo, en la página del
censo de población 2021 tenemos una serie de tablas que se pueden
descargar desde el enlace  con
una serie de opciones, entre ellas el formato Px-Axis. Este
formato es adecuado para tablas multidimensionales y los ficheros tienen
la extensión
con
una serie de opciones, entre ellas el formato Px-Axis. Este
formato es adecuado para tablas multidimensionales y los ficheros tienen
la extensión .px. Entre ellos Resultados
municipales: Población por sexo y país de nacimiento (grandes
grupos)
Usarlo en R es tan sencillo como sigue:
# install.packages("pxR") # Si no está ya instalado y nos da error la línea siguiente
censo2021 <- pxR::read.px("https://www.ine.es/jaxi/files/tpx/es/px/55243.px") |> as_tibble()Podríamos haber cargado el paquete entero con
library(pxR). No lo hemos hecho porque no lo volvemos a
necesitar, y porque al hacerlo, pxR carga un paquete que
tiene conflictos en los nombres de las funciones con el
tidyverse. Especificando el paquete en el que está la
función, no hace falta cargarlo: R sabe cómo encontrarlo.
Aquí vemos la utilidad del operador despues |> (o de
su análogo anterior, %>%). read.px carga
los datos con un formato interno del paquete pxR que
mantiene toda la información de un fichero pc-Axis. A veces nos puede
interesar, pero nosotros queremos poner los ficheros en formato
data.frame, o aún mejor, tiabla. La función
as_tibble nos permite pasar los datos directamente a
tiabla desde px.
El resultado es una tiabla en formato largo con 243960 filas y 5 columnas. Incluye los datos por país de nacimiento en cada municipio español.
Manejo de datos en el tidyverse
Vamos a utilizar estos dos ejemplos de datos para mostrar cómo estos
paquetes nos facilitan la vida. Bajaos la chuleta de manipulación de
datos de RStudio bien en inglés
o en español.
También tenéis el libro R for data
science,2e Las dos bibliotecas tienen en común que están diseñadas
para trabajar con el operador después |> al
tomar como primer elemento un objeto de datos.
Las tres funciones principales de tidyr son las
siguientes:
| Función | Utilidad | Argumentos |
|---|---|---|
pivot_longer |
Pasar a forma más larga | cols,names_to,values_to |
pivot_wider |
Pasar a forma más ancha | names_from,values_from |
separate |
Separar una columna en varias | col, into, sep |
Las funciones principales de dplyr, que se suelen
encadenar en general unas con otras, son:
| Función | Utilidad | Argumentos |
|---|---|---|
select |
Selecciona variables | a:x, -var1, … |
filter |
Selecciona observaciones | V1>5, !is.na(V2),… |
mutate |
Muta variables | ratio=V1/V2 |
rename |
Renombra variables | año = fecha, … |
arrange |
Ordena observaciones | desc(V2), V1, … |
Otros dos tipos de operaciones de dplyr son básicos.
left_join: Una primera es la de juntar objetos distintos que comparten al menos una variable. Para ello se utilizan las funcionesxxx_joinde dplyr, sobre todoleft_join.group_by+summarise:group_byindica que queremos descomponer el objeto de datos en grupos más pequeños de acuerdo a una/s dimensiones.summarisenos indica cómo resumir los datos para cada uno de los grupos definidos porgroup_by. También es posible utilizarmutatedespuès de haber agrupado. Esto sirve para definir una mutación que utiliza información específica de cada grupo de datos. Por último, si queremos eliminar la agrupación, debemos hacerungroup.
Además de estas funciones básicas hay otras funciones de
dplyr que son útiles
| Función | Utilidad | Ejemplos |
|---|---|---|
pull |
Extrae variable como vector | df |
slice |
Selecciona filas por posición | slice(df,10:20) |
tally |
Cuenta observaciones en cada grupo | … group_by(V) |
count |
Recuentos sin necesidad de group_by | … tally(Pais) |
bind_rows |
Junta observaciones de 2 objetos | bind_rows(obj1,obj2) |
across |
Transforma varias variables a la vez | across(starts_with(“Pob”),log) |
Cambios iniciales: poniendo los datos en la forma adecuada
Para este propósito las funciones más útiles son las del paquete
tidyr (más las auxiliares necesarias de
dplyr). Veamos dos ejemplos:
Ejemplo 1: Cambios iniciales en la variables del censo con
separate
Podemos ver cómo está guardada la información del censo con
str(censo2021)## tibble [243,960 × 5] (S3: tbl_df/tbl/data.frame)
## $ Unidades.de.medida : Factor w/ 1 level "Personas": 1 1 1 1 1 1 1 1 1 1 ...
## $ Sexo : Factor w/ 3 levels "Ambos sexos",..: 1 2 3 1 2 3 1 2 3 1 ...
## $ Municipio.de.residencia : Factor w/ 8132 levels "Total Nacional",..: 1 1 1 2 2 2 3 3 3 4 ...
## $ País.de.nacimiento..grandes.grupos.: Factor w/ 10 levels "TOTAL","España",..: 1 1 1 1 1 1 1 1 1 1 ...
## $ value : num [1:243960] 47400798 23248611 24152187 5022 2525 ...Comprobamos que las variables con caracteres han sido guardadas como
factores. Esto es algo típico de paquetes más antiguos, como {pxR}, a
diferencia de los paquetes más ligados al {tidyverse} como {readr} o
{haven}. Una buena práctica es convertir todos los factores en
caracteres utilizando across. Si no, en cualquier caso,
necesitaríamos convertir en carácter la variable código del municipio,
que incluye tanto el código INE de cinco números como el nombre del
municipio. Por otra parte, los nombres de los municipios vienen
precedidos de un código de 5 números. Es el llamado
código INE, análogo al código postal. Los códigos son muy
importantes en el manejo de datos puesto que permiten identificar a la
unidad sin ambiguedad. Sin embargo, necesitamos tener separados el
código del municipio y su nombre para poder hacer busquedas relevantes.
Para ello utilizaremos la función separate
La función separate sirve para pasar variables de tipo
character que incluyen informaciones diversas en la misma cadena, a dos
o más variables. Toma los siguientes argumentos:
args(separate)## function (data, col, into, sep = "[^[:alnum:]]+", remove = TRUE,
## convert = FALSE, extra = "warn", fill = "warn", ...)
## NULLdata: El objeto de datos. En nuestro casocenso2021.col: La columna que queremos separar en dos o más partes. En nuestro caso,Municipio.de.residencia. Hay que escribir directamente el nombre de la variable, sin ponerla entre comillas. Existe otra función si queremos especificar la columna como carácter, entre comillas: la funciónseparate_. En caso de que el nombre de la variable incluya caracteres no estándar como eñes, acentos o espacios, también funciona escribirla entre comillas graves:variable rárà.into: Los nombres de las nuevas columnas que se crean. En nuestro caso podemos llamarcoda la parte con el código ymunicipioal nombre del municipio. Para ello hay que especificarlo comoc("cod","municipio").sep: Especifica por donde separar la columna original. Si es un número, es la posición en que separar. En nuestro queremos separar en el primer espacio. Hay que darse cuenta que hay muchos municipios donde hay más de un espacio (ej:17901 Cruïlles, Monells i Sant Sadurní de l'Heura). Un problema es el primer valor,Total Nacionalque no incluye código, pero tiene “Total” antes del primer espacio.remove: Por defecto es cierto. Controla si la variable col es reemplazada por las nuevas, o si se mantienen todas. Nos va bien la opción por defecto.convert: Si deben tratar de convertirse las variables nuevas a su tipo en caso de que sean numéricas o lógicas. En nuestro caso nos va bien el valor por defecto FALSE.extra: Qué hacer cuando al separar con sep encontramos más piezas que la longitud de into. Es nuestro caso. Hay dos opciones que podríamos utilizar:dropprescindiría de la tercera y sucesivas (dejándonos con el primer nombre del municipio),mergenos deja junto lo que venga después de la primera separación. Esta será nuestra opción. La opción por defecto eswarn: utilizardroppero dar un mensaje de precaución.fill: Qué hacer cuando hay menos piezas de las que indica into, pegarlas a la derecha, rellenando en la izquierda (left), o pegarlas a la derecha rellenando en la derecha (right).
Por otro lado, el nombre de la 4ª variable
País.de.nacimiento..grandes.grupos., es excesivamente
complejo. Lo podemos cambiar a nacimiento con
rename utilizando la posición. También la variable
value recoge la población. Podemos cambiarla el nombre a
“pob”.
En definitiva, el código para generar las variables separadas es:
censo2021 <- censo2021 |> mutate(across(where(is.factor),as.character)) |>
dplyr::rename("nacimiento"=4, "pob"=value) |>
separate(Municipio.de.residencia,c("cod","municipio"),sep=" ", extra="merge") donde hemos reemplazado el objeto anterior por éste.
Por otro lado queremos generar una variable provincial y cambiar el
nombre de la variable value a pob con
rename. ¿Cómo generar una variable provincial a partir de
los códigos INE? Los códigos INE incluyen dos primeros números que
representan la provincia. Para poder generar el código provincial
hacemos una mutación con mutate. Ambas funciones
corresponden al paquete dplyr.
censo2021 <- censo2021 |> mutate(prov=as.numeric(cod)%/%1000)Primero lo hemos definido dividiendo pasándolo a número, haciendo la
división entera por 1000 (al ser todos códigos del 1000 al 52000). Los
datos correspondientes al total han quedado marcados como
NA (Not Available = No disponible).
Ejemplo 2: Pasando datos de formato ancho a
largo en los datos del Índice de Desarrollo Humano
Los datos del índice de desarrollo humano incluye un número muy elevado de columnas, 1008 que no son verdaderas variables: no están en forma ordenada.
Vamos a seleccionar las columnas del HDI correspondientes a los años desde 2000 a 2021, y después a pasarlos a forma larga, en la que cada fila corresponda a la combinación de municipio y año. Por último, con separate generamos la variable numérica año.
La función básica para pasar de forma ancha a larga es
pivot_longer, que nos pide como argumentos principales:
data: El objeto de datos, en nuestro casoAE13muncols: Las columnas que pivotamos a formato largo. En nuestro caso son columnas que empiezan porhdi_seguido de un número entre 2000 y 2021. Para ello utilizaremos la función auxiliar del tidyverse,num_range, aunque también las podríamos seleccionar por posición conhdi_2000:hdi_2021.names_to: El nombre que asignamos a la columna que incluya las etiquetas de las columnas en formato ancho. La podemos llamar"año"names_prefix: Prefijo que quitar del nombre de las variables. En nuestro caso, si especificamosnames_prefix="hdi_", nos ahorramos la necesidad de unseparate.values_to: El nombre que asignamos a la columna que incluye los valores de dichas columnas, los numeros. La podemos llamar"hdi".
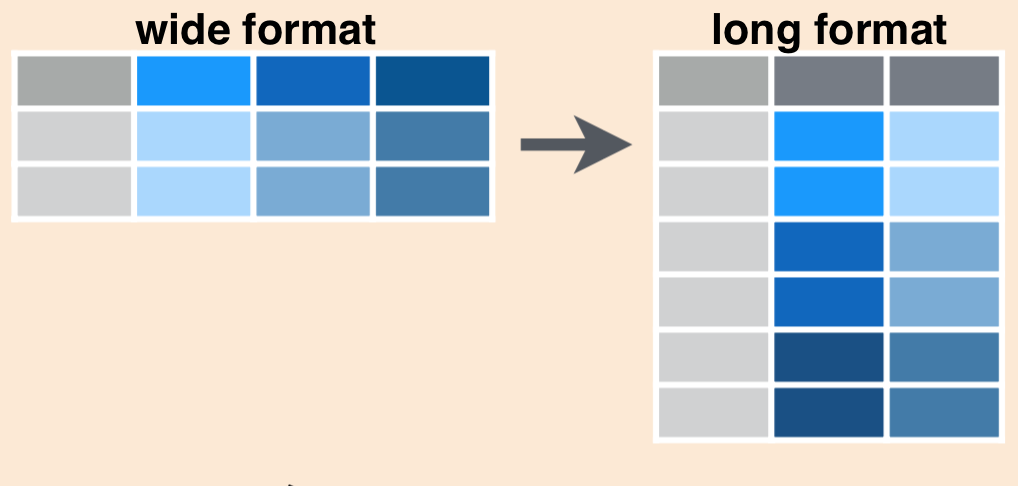
idh = hdi |> select(1:3, num_range("hdi_",2000:2021)) |> pivot_longer(-(1:3), names_to="año",names_prefix="hdi_", values_to="hdi") |>
mutate(año=parse_number(año))
idh## # A tibble: 4,532 × 5
## iso3 country hdicode año hdi
## <chr> <chr> <chr> <dbl> <dbl>
## 1 AFG Afghanistan Low 2000 0.335
## 2 AFG Afghanistan Low 2001 0.337
## 3 AFG Afghanistan Low 2002 0.362
## 4 AFG Afghanistan Low 2003 0.376
## 5 AFG Afghanistan Low 2004 0.392
## 6 AFG Afghanistan Low 2005 0.4
## 7 AFG Afghanistan Low 2006 0.409
## 8 AFG Afghanistan Low 2007 0.424
## 9 AFG Afghanistan Low 2008 0.43
## 10 AFG Afghanistan Low 2009 0.44
## # ℹ 4,522 more rowsYa tenemos creado el objeto en forma larga. Un detalle: hemos tenido
que utilizar num_range("hdi_",2000:2021) y no
starts_with("hdi_") porque hay otras variables que empiezan
por hdi, como hdi_rank o los índices separados
para hombres y mujeres. La ventaja de num_range es que
podemos especificar el rango de años que queremos sin necesidad de
cargar todos los que hay. También utilizamos parse_number
para convertir a número. Es más fuerte que as.numeric:
fuerza la conversión a número de cualquier cosa que parezca un número en
la cadena.
Este tipo de objetos en formato largo son muy útiles, por ejemplo,
para hacer gráficos con ggplot. Este sería el gráfico de la
evolución del IDH a lo largo del tiempo en los
distintos países utilizando un color distinto según el nivel de
desarrollo actual:
idh |>
ggplot(aes(x=año,y=hdi,group=country,color=hdicode)) + geom_line()
Este gráfico es muy parecido al que está en la página web del IDH
Sin entrar en detalles se nota un cierto aumento en los IDH a lo largo del tiempo en todo tipo de países, pero con pocos países que crucen a otros en el rango. También una caída en el 2020 por el COVID.
Resumenes de los datos: Uso reiterado de las funciones del
tidyverse
Habitualmente para responder a una pregunta que nos interese necesitaremos aplicar varias funciones del tidyverse de forma sucesiva. Aprender a utilizarlo es preguntarse qué operaciones sucesivas tenemos que hacer en cada caso. Después escribir los comandos.
Ejemplo 1: Municipios salmantinos mayores de 5000 habitantes ordenados por población (de mayor a menor)
Tenemos que hacer dos cosas: primero filtrar (filter), y
después ordenar (arrange). Salamanca tiene código
provincial 37, y nos queremos fijar en toda la población. Este es el
código:
library(knitr) # Para poder sacar una tabla bonita en html con kable
censo2021 |> filter(nacimiento=="TOTAL",prov==37,
pob>5000,Sexo=="Ambos sexos") |>
select(municipio,pob) |>
arrange(desc(pob)) |>
kable ()| municipio | pob |
|---|---|
| Salamanca | 143549 |
| Santa Marta de Tormes | 14632 |
| Béjar | 12258 |
| Ciudad Rodrigo | 12056 |
| Villamayor | 7387 |
| Carbajosa de la Sagrada | 7345 |
| Villares de la Reina | 6490 |
| Peñaranda de Bracamonte | 6151 |
| Guijuelo | 5581 |
| Alba de Tormes | 5164 |
La función select dispone de un montón de
especificidades que se pueden consultar, por ejemplo, en Sánchez(2019).
arrange permite ordenar de acuerdo a las variables que se
especifiquen. Por defecto, de menor a mayor. Si queremos cambiar el
orden hay que utilizar la función auxiliar desc, como en
este caso, o, desde la última versión de tidyverse, cuando la variable
es numérica como es el caso, escribir con signo negativo,
-pob.
kable no hace falta para mostrar los resultados en una
sesión interactiva. Se trata de una función del paquete
knitr para dar formato sencillo al html o el
fichero que genere el Rmd. Sólo tiene sentido en ficheros
Rmarkdown. Una alternativa para tablas en publicaciones es
flextable() del paquete {flextable}.
Ejemplo 2: Obtener los 10 municipios salmantinos con mayor porcentaje de población extranjera (de ambos sexos)
Tenemos que filtrar primero (filter), seleccionando, de
todos los origenes, sólo “TOTAL” y “España”. Después pasar a forma ancha
(pivot_wider), mutar calculando la proporción extranjera
(mutate), ordenar de mayor a menor (arrange),
y seleccionar (select) columnas. Todas las operaciones las
encadenamos con el operador |> :
censo2021 |> filter(prov==37,Sexo=="Ambos sexos",
nacimiento%in%c("TOTAL","España")) |>
pivot_wider(names_from=nacimiento,
values_from=pob) |>
mutate(Extranjeros=TOTAL-España,
PropExtr=Extranjeros/TOTAL*100) |>
arrange(desc(PropExtr)) |>
select(municipio,TOTAL:PropExtr) |> head(10) |> kable(digits=2)| municipio | TOTAL | España | Extranjeros | PropExtr |
|---|---|---|---|---|
| Fuentes de Oñoro | 1111 | 650 | 461 | 41.49 |
| Aldea del Obispo | 259 | 196 | 63 | 24.32 |
| Villar de Gallimazo | 209 | 162 | 47 | 22.49 |
| Valverde de Valdelacasa | 67 | 52 | 15 | 22.39 |
| Armenteros | 195 | 152 | 43 | 22.05 |
| Beleña | 227 | 185 | 42 | 18.50 |
| Puebla de Azaba | 141 | 116 | 25 | 17.73 |
| Buenavista | 367 | 307 | 60 | 16.35 |
| Bouza, La | 56 | 47 | 9 | 16.07 |
| Campillo de Azaba | 153 | 129 | 24 | 15.69 |
Si queremos limitarnos a los municipios mayores de 1000 habitantes y con al menos 100 extranjeros se puede añadir un filter en el sitio adecuado:
censo2021 |> filter(prov==37,Sexo=="Ambos sexos",
nacimiento%in%c("TOTAL","España")) |>
pivot_wider(names_from=nacimiento,
values_from=pob) |>
mutate(Extranjeros=TOTAL-España,
PropExtr=Extranjeros/TOTAL*100) |>
filter(TOTAL>1000,Extranjeros>100) |>
arrange(desc(PropExtr)) |>
select(municipio,TOTAL:PropExtr) |> kable(digits=2)| municipio | TOTAL | España | Extranjeros | PropExtr |
|---|---|---|---|---|
| Fuentes de Oñoro | 1111 | 650 | 461 | 41.49 |
| Terradillos | 3096 | 2751 | 345 | 11.14 |
| Guijuelo | 5581 | 4963 | 618 | 11.07 |
| Salamanca | 143549 | 128717 | 14832 | 10.33 |
| Ledesma | 1555 | 1443 | 112 | 7.20 |
| Castellanos de Moriscos | 2818 | 2622 | 196 | 6.96 |
| Santa Marta de Tormes | 14632 | 13622 | 1010 | 6.90 |
| Ciudad Rodrigo | 12056 | 11359 | 697 | 5.78 |
| Cabrerizos | 4282 | 4035 | 247 | 5.77 |
| Villamayor | 7387 | 6965 | 422 | 5.71 |
| Villares de la Reina | 6490 | 6121 | 369 | 5.69 |
| Carbajosa de la Sagrada | 7345 | 6936 | 409 | 5.57 |
| Béjar | 12258 | 11583 | 675 | 5.51 |
| Alba de Tormes | 5164 | 4911 | 253 | 4.90 |
| Peñaranda de Bracamonte | 6151 | 5861 | 290 | 4.71 |
| Doñinos de Salamanca | 2224 | 2122 | 102 | 4.59 |
| Aldeatejada | 2311 | 2207 | 104 | 4.50 |
Para asegurarte de que comprendes bien estos ejemplos, una
recomendación: puedes ir aplicando de manera sucesiva las distintas
operaciones |>: Seleccionas primero y ejecutas hasta el
primer filter, luego incluyes el pivot_wider,
…
Ejemplo 3: Provincias españolas ordenadas por la proporción de municipios menores de 1000 habitantes respecto al total de municipios
censo2021 |> filter(!is.na(prov),Sexo=="Ambos sexos",
nacimiento=="TOTAL") |>
mutate(menor1000=(pob<1000)) |>
group_by(prov) |>
summarise(n=n(),menor1000=sum(menor1000)) |>
mutate(prop=menor1000/n*100) |>
arrange(desc(prop)) |> head(10) |> kable(digits=2)| prov | n | menor1000 | prop |
|---|---|---|---|
| 42 | 183 | 172 | 93.99 |
| 49 | 248 | 233 | 93.95 |
| 9 | 371 | 345 | 92.99 |
| 44 | 236 | 219 | 92.80 |
| 5 | 248 | 230 | 92.74 |
| 37 | 362 | 333 | 91.99 |
| 34 | 191 | 171 | 89.53 |
| 40 | 209 | 187 | 89.47 |
| 19 | 288 | 255 | 88.54 |
| 16 | 238 | 206 | 86.55 |
La función n() es otra de las funciones auxiliares del
tidyverse. Una dificultad para leer los resultados es que las provincias
aparecen por su código y no por su nombre. Vemos Salamanca en 6
posición. El argumento digits en kable permite
controlar cuántos decimales se imprimen en la tabla.
Ejemplo 4: Provincias españolas ordenadas por la proporción de población viviendo en municipios menores de 1000 habitantes
Es una variación del anterior. A priori, parece muy distinto, pero no
lo es. La idea es sencilla: añadir columnas en el summarise
del ejemplo 6:
censo2021 |> filter(!is.na(prov),Sexo=="Ambos sexos",
nacimiento=="TOTAL") |>
mutate(menor1000=(pob<1000),pobmenor=pob*menor1000) |>
group_by(prov) |> summarise(n=n(),menor1000=sum(menor1000),pob=sum(pob),pobmenor=sum(pobmenor)) |>
mutate(prop_Munic=menor1000/n*100,
prop_Pob=pobmenor/pob*100) |>
arrange(desc(prop_Pob)) |> head(10) |> kable(digits=2)| prov | n | menor1000 | pob | pobmenor | prop_Munic | prop_Pob |
|---|---|---|---|---|---|---|
| 49 | 248 | 233 | 169165 | 64993 | 93.95 | 38.42 |
| 44 | 236 | 219 | 134259 | 42962 | 92.80 | 32.00 |
| 5 | 248 | 230 | 158898 | 44530 | 92.74 | 28.02 |
| 40 | 209 | 187 | 153626 | 39695 | 89.47 | 25.84 |
| 16 | 238 | 206 | 196510 | 46713 | 86.55 | 23.77 |
| 37 | 362 | 333 | 327735 | 73856 | 91.99 | 22.54 |
| 42 | 183 | 172 | 88796 | 19978 | 93.99 | 22.50 |
| 22 | 202 | 174 | 223995 | 49869 | 86.14 | 22.26 |
| 34 | 191 | 171 | 159146 | 31009 | 89.53 | 19.48 |
| 10 | 223 | 155 | 390544 | 67869 | 69.51 | 17.38 |
Vemos como, aún habiendo provincias con más de un 90% de municipios menores de 1000 habitantes, la población que vive en estos no pasa nunca del 40% (el máximo es Zamora, provincia 49).
Ejercicios 1
Preguntas como las siguientes tienen respuestas relativamente simples con estos datos:
- ¿Cuál es el código INE de Miranda de Ebro?
- ¿Cuántos extranjeros viven en Toledo?
- ¿Qué proporción de extranjeros hay en Mijas, Málaga?
- ¿Cuántos municipios españoles tienen más de un 40% de extranjeros?
- Tabla con las provincias clasificadas por mediana entre los municipios de número de extranjeros.
- Municipios salmantinos ordenados por número de nacidos en Asia (de ambos sexos).
- ¿Cuál es el municipio español con mayor proporción de mujeres? ¿qué proporción?
- ¿En qué provincia española hay mayor proporción de nacidos en la Unión Europea (sin España)? ¿Cuál es esa proporción?
- ¿Para que nacionalidad de origen hay mayor desproporción entre los sexos?
- Os podéis hacer vuestra propias preguntas.
Leer datos de página web y juntar bases de datos.
Añadir datos provinciales o de CCAA al censo 2021
En esta página tenemos los códigos
provinciales INE. También los tenemos en ésta
en formato excel. Cargarlos en R será fácil con
read_excel
library(readxl)
download.file("https://alarcos.esi.uclm.es/per/fruiz/pobesp/dat/list-pro.xls",destfile = "list-pro.xls",mode="wb")
provs=read_excel("list-pro.xls")Aquí tenemos en CP el código provincial en formato
chr, y en PROVINCIA la provincia. Podemos
añadir prov que sea numérico como en
censo2021:
provs <- provs |> mutate(prov=as.numeric(CP))¿Cómo añadir el código de provincia a un objeto que tenga la variable
prov, tal como censo2021? Muy sencillo, con un
left_join. Podríamos utilizarlo para añadir las otras
variables, como número de municipios o superficie. Sólo nos interesa
añadir PROVINCIA, asi que seleccionamos sólo las dos
variables antes del join.
censo2021 <- censo2021 |>
left_join(provs |> select(PROVINCIA,prov),by="prov") Si repetimos el análisis de las provincias con más población en
municipios menores de 1000 habitantes, pero utilizando como variable de
grupo PROVINCIA, obtenemos:
censo2021 |> filter(!is.na(prov),Sexo=="Ambos sexos",
nacimiento=="TOTAL") |>
mutate(menor1000=(pob<1000),pobmenor=pob*menor1000) |>
group_by(PROVINCIA) |> summarise(n=n(),menor1000=sum(menor1000),pob=sum(pob),pobmenor=sum(pobmenor)) |>
mutate(prop_Munic=menor1000/n*100,
prop_Pob=pobmenor/pob*100) |>
arrange(desc(prop_Pob)) |> head(10) |> kable(digits=2)| PROVINCIA | n | menor1000 | pob | pobmenor | prop_Munic | prop_Pob |
|---|---|---|---|---|---|---|
| Zamora | 248 | 233 | 169165 | 64993 | 93.95 | 38.42 |
| Teruel | 236 | 219 | 134259 | 42962 | 92.80 | 32.00 |
| Ávila | 248 | 230 | 158898 | 44530 | 92.74 | 28.02 |
| Segovia | 209 | 187 | 153626 | 39695 | 89.47 | 25.84 |
| Cuenca | 238 | 206 | 196510 | 46713 | 86.55 | 23.77 |
| Salamanca | 362 | 333 | 327735 | 73856 | 91.99 | 22.54 |
| Soria | 183 | 172 | 88796 | 19978 | 93.99 | 22.50 |
| Huesca | 202 | 174 | 223995 | 49869 | 86.14 | 22.26 |
| Palencia | 191 | 171 | 159146 | 31009 | 89.53 | 19.48 |
| Cáceres | 223 | 155 | 390544 | 67869 | 69.51 | 17.38 |
que se entiende mucho más claro.
Añadir el IDH a un mapa con left_join
Una aplicación de la operación left_join que hemos visto
es la generación de mapas. Crear mapas con R es muy sencillo con el
formato de datos sf, básicamente una tiabla con
una columna especial que se llama geography y contiene las
siluetas (los polígonos) de las regiones. Para hacer un mapa del mundo
utilizamos un mapa ya existente en el paquete tmap y le
añadimos una columna con nuestros datos del idh antes de
hacer el gráfico. Para saber qué fila corresponde a cada país utilizamos
el código internacional iso_a3. En
el anterior left_join declaramos en by el
nombre de la variable común porque se llamaban igual. Si se llaman
distintas se pueden declarar con
by=join_by(iso_a3==iso3)
library(tmap)## Breaking News: tmap 3.x is retiring. Please test v4, e.g. with
## remotes::install_github('r-tmap/tmap')data(World) # Mapa del mundo en formato sf
mapa_idh <- World |>
left_join( idh |> filter(año==2021),by=join_by(iso_a3==iso3))
ggplot(data=mapa_idh) + geom_sf(aes(fill=hdi)) +
viridis::scale_fill_viridis()
Observamos cómo los valores más bajos se concentran en África sub-sahariana.
Ejercicios 2
- El fichero de excel de las provincias también incluye códigos de
Comunidades Autónomas, haz el
left_joincorrespondiente para incluir una columna de CCAA encenso2021y clasifica las CCAA por el porcentaje de municipios menores de 1000 habitantes. - Crea una variable que mida en qué porcentaje ha aumentado el IDH
entre 2000 y 2021, primero a partir del objeto ancho,
hdiconmutate, y despúes a partir del objeto largo,idh, congroup_by+summarize. Haz un mapa del mundo con lo que ha crecido cada país entre 2000 y 2021.