链上数据分析
Liam
2024-04-05
- 什么是链上数据
- 链上数据的重要性
- 链上数据分析谁来做
- 如何做链上数据分析
- Dune平台介绍
- Dune 数据分析教程
- 创建Dune 看板
- 熟悉数据表
- Dune V2数据引擎数据表介绍
- 原始数据表
- 已解析项目表
- 魔法表
- 价格信息表(prices.usd,prices.usd_latest)
- DeFi交易信息表(dex.trades,dex_aggregator.trades)
- Tokens表(tokens.erc20,tokens.nft)
- ERC代表信息表(erc20_ethereum.evt_Transfer,erc721_ethereum.evt_Transfer等)
- ENS域名信息表(ens.view_registrations等)
- 标签信息表(labels.all等)
- 余额信息表(balances_ethereum.erc20_latest等)
- NFT交易信息表(nft.trades等)
- 其他魔法表
- 社区贡献数据和用户生成数据表
- SixdegreeLab介绍
- 实践案例 : 制作Lens Protocol的数据看板
- 其他
#成为链上数据分析师
什么是链上数据
大部分人刚接触区块链时都会得到这样的概念:区块链是个公开的、不可篡改的记账本,一切的转账、交易记录是透明可信的。然而这一功能并不是区块链的全部,只是最初我们从“点对点的电子现金系统”,也就是“记账本”这个角度出发的。随着智能合约的发展,区块链实际上正在成为一个大型的数据库,下图从架构对比了传统web2和web3应用的区别:智能合约代替了后端,区块链也承担起一部分数据库的功能。越来越多的链上项目涌现,我们在链上的交互越来越频繁,比如在DeFi协议里添加了多少流动性,mint了哪些NFT,甚至关注哪个社交账号记录都能上链,我们一切与区块链的交互都将被记录在这个数据库中,这些记录就属于链上数据。

链上数据大致分为三类:
交易数据 如收发地址,转账金额,地址余额等
区块数据 例如时间戳,矿工费,矿工奖励等
智能合约代码 即区块链上的编码业务逻辑
链上数据分析就是从这三类数据中提取想要的信息进行解读。 从数据栈角度来看,区块链数据产品可以分为数据源、数据开发工具和数据app三类。

灵活运用各类数据产品,会为我们在crypto世界提供崭新的视角。
虽然我们一直在说链上数据是公开透明的,但是我们很难直接读取那些数据,因为一笔简单的swap交易在链上看起来可能是这样的:

我们能在区块链浏览器里看到一些原始链上数据,但是我的问题是想知道今天UniswapV3成交量是多少,这不解决我问题阿!我想看到的是下面这张图:

链上原始数据并不能给我们答案,我们需要通过索引 (indexing),处理 (processing),存储 (storage) 等等一系列数据摄取 (ingestion) 的处理过程,再根据所提问题来聚合运算对应的数据,才能得到问题的答案。

要从头做起,我们可能需要自己搭节点来接区块链数据,再作处理,但是这明显是非常耗时耗力的。还好,有许多数据平台,如Dune,Flipside,Footprint,他们将索引得到的原始链上数据,经过一系列处理后,存入由平台负责更新和管理的数据仓库,也就是说整个区块链数据被他们做成了好多张关系型数据表格,我们要做的就是从表格里选一些我们想要的数据构建我们的分析数据。更进一步地,有Nansen,Messari,DeBank这些数据类产品,不光整理好数据,还按照需求分门别类地封装起来,方便用户直接使用。
| 分类 | 应用示例 |
|---|---|
| 数据应用 | Nansen,Messari,DeBank |
| 数据平台 | Dune,FLipside,Footprint |
| 数据节点 | Infura,Quick Node |
链上数据的重要性
随着链上生态的繁荣,丰富的交互行为带来了海量数据。这些链上数据对应着链上价值的流动,对这些数据的分析和根据分析而得出的洞察和见解变得极为有价值。通过链上透明且不会说谎的数据,我们可以推断交易者,甚至市场整体的心理状态和心理预期,从而帮助自身做更有利的决策,也可以在黑暗森林前行中时为自己提起一盏明灯,照亮前方保护自己。
以大家熟悉的DeFi协议流动性挖矿为例:你添加流动性收获了奖励,池子增加了深度,用户享受了更低的滑点,大家都有光明的未来,你安心地将钱锁在合约里。可是某一天,黑天鹅悄然而至,聪明钱消息灵通立马撤退,而你只是个普通投资者,等你看到负面新闻再想到去提款时,手里的奖励几乎分文不值,猛烈的无常损失让你保本都难,直呼区块链骗局。

链上数据分析谁来做
对于大部分用户来说,成熟的数据产品已经够用,灵活组合多个数据工具就能取到不错的效果。比如使用Nansen帮助用户追踪巨鲸的实时动向;用Token Terminal查看各协议的收入;NFT类的数据监控平台更是五花八门。这些“成品”类数据产品虽然门槛低,使用方便,却也有无法满足高定制化要求的瓶颈。

举个例子, 你通过https://ultrasound.money/ 发现以太坊上Gas消耗突然上涨,是由这个没有听说过的XEN推动的,你敏锐地意识到,这可能是个早期机会!通过推特搜索,你了解了XEN采用PoP(Proof of Participation)挖矿机制,XEN挖矿参与者拥有挖出的XEN代币的所有权,随参与人数增加,挖矿难度加大,供应量降低。你想了解大家的参与情况,光靠个gas消耗可不够,你还想知道参与的人数,趋势,参与者都选择锁仓多久?同时你还发现,他好像没有防女巫?付个gas就能参与,冲进来的科学家多吗?我还有利润吗?分析到这你急需数据来支撑你“冲不冲”的决策,可是正因为早期,数据app中还没有对它的分析,同时数据app也很可能不会对每一个协议都进行监控分析。这就是为什么已经有很多数据产品的情况下,我们仍然需要自己会写一些数据分析:现成的产品难以满足定制化的需求。

通过自己分析数据:https://dune.com/sixdegree/xen-crypto-overview, 我得知了大部分人都选择的是短期质押,且接近百分70的都是新钱包,说明被大家撸坏了,那我就明白了短期抛售压力会非常大,所以我如果想选择参与,就选质押最短的时间,尽快卖出,比谁跑得快。 至此,你已经完成了链上数据分析的整个流程:发现项目,研究项目机制,抽象出评估项目的标准,最后才是动手做数据处理、可视化,辅助决策。
如何做链上数据分析
数据分析提供一个可量化的视角最终去支撑决策,分析只是过程而不是目的。简单的步骤是厘清三个问题,构建数据思维:
- 我的目的是什么?
是判断一个币现在是否是买入的好时机?决定是否为AAVE添加流动性赚取收益?还是想知道现在入场Stepn是否为时已晚?
- 我的策略是什么?
买币的策略就是紧跟Smart money,买啥跟啥,他进我进他出我出;观察如果协议运作情况良好,存款利率满意,就把暂时不动的币存进去吃利息;Stepn最近大火,如果势头仍然向上,那我就参与其中。
- 我需要什么数据帮我做决策?
需要监控Smart money地址的持仓动向,甚至考量代币的交易量和持仓分布;要查一下协议的TVL,未偿债务数额,资金利用率,APR等;考虑每日新增用户数,增长趋势,每日活跃用户数,交易笔数,玩家出入金情况,NFT市场里道具的销售情况。

这三个问题的难度逐渐增加,一二还容易回答,想明白第三个问题需要大量的学习和理解,这也是区分数据分析师们水平高低的小门槛。一名优秀的分析师应该具备以下三种特点:
- 对赛道或者协议有理解与认识
即分析的是什么赛道?这个项目的运行机制是什么?会产生哪些数据,分别代表什么含义?
- 抽象事物的能力
将一个模糊的概念变成可量化的指标,即
“这个DEX协议好不好” =>“流动性”+“成交量”+“活跃用户量”+“资本利用率”+“协议产生的收益”
再回到上一点,通过你对协议的了解找到对应的数据。
- 处理数据的能力
这里包含取数据(链上数据从哪来),处理数据(怎么筛选想要的滤除无关的),以及数据可视化的能力。

总的来说,数据分析只是支撑研究的工具,不要为了分析而分析。这个过程首先是出于你想对某个项目、概念、赛道进行研究、投资,然后学习、了解项目的运行机制,抽象出对定性概念的定量分析,最后才是找数据,做可视化。
数据分析最重要的始终是数据思维,至于最后动手做这一步,无非是熟练功,可以分为两部分:
- 对区块链数据结构的了解。比如在EVM链中,只有EOA账户能发起交易,但是智能合约在被调用时可以转账ETH,这些内部调用就是通过traces 表来记录的,所以查表时查transactions会遗漏内部调用的交易。
- 掌握R ,Python、SQL等语言。掌握基本的数据库语言,无论是自己接数据或者用数据平台,都可以比较得心应手。
Dune平台介绍
前文提到从数据栈角度来看,区块链数据产品可以分为数据源、数据开发工具和数据app三类,直接接入数据源成本太高,难度也更大,而数据app又是固定好的,我们要想分析数据, 需要一个开发工作量不大,又能接获取各种数据的平台,这类数据开发工具中,最便捷的便是Dune平台。
Dune是一个链上的数据分析平台,用户可以在平台上面书写SQL语句,从Dune解析的区块链数据库中筛选出自己需要的数据,并生成对应的图表,组成仪表盘。
本教程的全部查询示例和引用的相关查询(完整的数据看板和第三方账号的查询除外)全部使用Dune SQL查询引擎测试通过。Dune已经宣布2023年内全面过渡到Dune SQL引擎,所以大家直接学习Dune SQL的语法即可。
页面介绍
在注册完Dune平台后,平台的主界面如下,具体的各项功能:
- Discover:是展示平台的各个方面趋势
- Dashboard:显示当前关注量最多的dashboard,在这个界面,可以左上角的搜索/右侧的搜索框搜索自己感兴趣的关键词,这也是最重要的一个部分,可以点击一个dashboard,查看别人制作的dashboard
- Queries:显示的是当前关注量最多的query,在这个界面,可以左上角的搜索/右侧的搜索框搜索自己感兴趣的关键词;
- Wizards:平台中收藏量最高的用户排名;
- Teams:平台中收藏量最高的团队排名;
- Favorites:
- Dashboard:自己收藏的dashboard,可以在右侧搜索框搜索
- Queries:自己收藏的query,可以在右侧搜索框搜索
- My Creations:
- Dashboard:自己创建的dashboard,可以在右侧搜索框搜索,如果你有团队,仪表盘可以在不同的团队中
- Queries:自己创建的query,可以在右侧搜索框搜索
- Contracts:自己提交解析的合约,可以在右侧搜索框搜索
- New Query:新建一个查询
- 其它
- Docs:链接到帮助文档
- Discord:链接到社区讨论组

核心功能
查询Query
在点击New Query 之后,会进入一个新的界面,界面包含三个主要部分:
数据表目录:在左侧有一个数据搜索框和数据列表,展开数据列表后可以看到具体的每一张表。(注:在第一次进入显示的是v1版本的,已弃用,请在上面选择Dune Engine v2(SparkSQL))
- Raw:记录了各个区块链的原始数据表,主要为区块信息blocks、交易信息transactions、事件日志信息logs和traces表等;目前支持的链有:Ethereum、Polygon、Arbitrum、Solana、Optimism、Gnosis Chain、Avalanche
- Decoded projects:各个项目/合约的直接解析表,解析出来的表会更加清晰易懂,如果分析具体项目用这里的表会更加合适
- Spells:是从raw和Decoded projects中提取的综合数据表,比如Dex,NFT,ERC20等等
- Community:社区用户贡献的数据表
代码编辑器:位于右上方的黑色区域,用于写自己的SQL语句,写完可以点击右下角的Run执行
结果&图表可视化:位于右下方,查询结果会显示在Query results,可以依次在后面新建新的子可视化页面

平台的query可以通过分支fork的方式,将别人的query复制到自己的账户下,进行修改和编辑。
spellbook
spellbook是Dune平台非常重要的一个数据表,它是由社区用户贡献的一系列加工后的数据表,可以在github页面duneanalytics/spellbook贡献自己定义的数据表,dune平台会通过该定义,在后台生成相应的数据,在上图的前端页面中可以直接使用这些定义好的数据表,这些数据表的定义和字段意义可以到这里查看:https://spellbook-docs.dune.com/#!/overview
目前spellbook中已经由社区用户贡献了几百张各种各样的表,比如nft.trades, dex.trades, tokens.erc20等等

参数
在query中还可以设置一个可变的输入参数,改变查询条件,比如可以设置不同的用户地址,或者设置不同的时间范围,参数设置是以’{{参数名称}}’形式嵌入到查询语句中的。

图表可视化Visualization
在图表可视化中,Dune平台提供了散点图、柱状图、折线图、饼状图、面积图和计数器以及二维数据表。在执行完查询,得到结果之后,可以选择New visualization 创建一个新可视化图,在图中可以选择想要显示的数据字段,可以立刻得到对应的可视化图,图中支持显示多个维度的数据,在图表下方是设置图表样式的区域,包括名称、坐标轴格式、颜色等信息。

仪表盘Dashboard
上一小节的单个图表可视化,可以在仪表盘中灵活的组合,形成一个数据指标的聚合看板,并附带解释说明,这样可以从一个更加全面的角度去说明。在Discover中找到New Dashboard可以新建一个仪表盘,在仪表盘中可以添加所有query中生成的图表,并且可以添加markdown格式的文本信息,每个可视化的控件都可以拖拽并调整大小。

Dune相关资料
- 官方资料
- Dune官方文档(包括中文文档) : https://dune.com/docs/ -Discord : https://discord.com/invite/ErrzwBz
- Youtube : https://www.youtube.com/channel/UCPrm9d2hLd_YxSExH7oRyAg
- Github Spellbook : https://github.com/duneanalytics/spellbook
- 社区教程
- Dune 数据看板零基础极简入门指南 : https://twitter.com/gm365/status/1525013340459716608
- Dune入门指南——以Pooly为例,做一个NFT看板 : https://mirror.xyz/0xa741296A1E9DDc3D6Cf431B73C6225cFb5F6693a/iVzr5bGcGKKCzuvl902P05xo7fxc2qWfqfIHwmCXDI4
- 从0到1构建你的Dune V1 Analytics看板(基础篇): https://mirror.xyz/0xbi.eth/6cbedGOx0GwZdvuxHeyTAgn333jaT34y-2qryvh8Fio
- 从0到1构建你的Dune V1 Analytics看板(实战篇): https://mirror.xyz/0xbi.eth/603BIaKXn7s2_7A84oayY_Fn5XUPh6zDsv2OlQTdzCg
- 从0到1构建你的Dune V1 Analytics看板(常用表结构): https://mirror.xyz/0xbi.eth/uSr336PzXtqMuE_LPBewbJ1CHN2oUs40-TDET2rnkqU
Dune 数据分析教程
Dune是一个强大的区块链数据分析平台,以SQL数据库的方式提供原始区块链数据和已解析的数据。通过使用SQL查询,我们可以从Dune的数据库中快速搜索和提取各种区块链信息,然后将其转换为直观的可视化图表。以此来获得信息和见解。数据看板(Dashboard)是Dune上内容的载体,由各种小部件(Widget)组成。这些小部件可以是从Query查询结果生成的可视化图表或文本框,你还可以在文本框中嵌入图像、链接等。查询(Query)是Dune数据面板的主要数据来源。我们通过编写SQL语句,执行查询并在结果集上生成可视化图表,再将图表添加到对应的数据看板中。
使用Dune处理数据的一般过程可以概括为:
编写SQL查询显示数据 ->可视化查询结果 ->在数据看板中组装可视化图表 -> 调整美化数据看板。
2. 数据库基础知识
在开始编写我们的数据看板所需的第一个SQL查询之前,我们需要先了解一些必备的SQL查询基础知识。
数据库的基本概念介绍
数据库(Database):数据库是结构化信息或数据的有序集合,是按照数据结构来组织、存储和管理数据的仓库。Dune平台目前提供了多个数据库,分别支持来自不同区块链的数据。本教程使用Dune平台的“v2 Dune SQL”数据库查询引擎。所有示例查询和引用的例子链接(第三方的query除外)均以更新到Dune SQL。
模式(Schema):同一个数据库中,可以定义多个模式。我们暂时可以将模式简单理解为数据表的拥有者(Owner)。不同的模式下可以存在相同名称的数据表。
数据表(Table):数据表是由表名、表中的字段和表的记录三个部分组成的。数据表是我们编写SQL查询访问的主要对象。Dune将来自不同区块链的数据分别存贮到不同模式下的多个数据表中供我们查询使用。使用数据表编写查询时,我们用schema_name.table_name的格式来指定查询要使用的数据表名称。例如ethereum.transactions表示ethereum模式下的transactions表,即以太坊的交易表。同一个模式下的数据表名称必须唯一,但是相同名称的数据表可以同时存在于多个不同的模式下。例如V2中同时存在ethereum.transactions和bnb.transactions表。
数据列(Column):数据列也称为字段(Field),有时也简称为“列”,是数据表存贮数据的基本单位。每一个数据表都包含一个或多个列,分别存贮不同类型的数据。编写查询时,我们可以返回全部列或者只返回需要的数据列。通常,只返回需要的最少数据可以提升查询的效率。
数据行(Row):数据行也称为记录(Record)。每一个记录包括数据表定义的多个列的数据。SQL查询执行得到的结果就是一个或多个记录。查询输出的记录集通常也被称为结果集(Results)。
本教程使用的数据表
在本节的SQL查询示例中,我们使用ERC20代币表tokens.erc20做例子。ERC20代币表是由Dune社区用户通过魔法书(Spellbook)方式生成的抽象数据表(Spells,也称为Abstractions)。除了生成方式不同,这种类型的数据表的使用方式跟其他表完全一样。ERC20代币表保存了Dune支持检索的不同区块链上面的兼容ERC20标准的主流代币的信息。对于每种代币,分别记录了其归属的区块链、代币合约地址、代币支持的小数位数和代币符号信息。
ERC20代币表tokens.erc20的结构如下:
| 列名 | 数据类型 | 说明 |
|---|---|---|
| blockchain | string | 代币归属的区块链名称 |
| contract_address | string | 代币的合约地址 |
| decimals | integer | 代币支持的小数位数 |
| symbol | string | 代币的符号 |
SQL查询快速入门
广义的SQL查询语句类型包括新增(Insert)、删除(Delete)、修改(Update)、查找(Select)等多个类型。狭义的SQL查询主要指使用Select语句进行数据检索。链上数据分析绝大多数时候只需使用Select语句就能完成工作,所以我们这里只介绍Select查询语句。后续内容中我们会交替使用查询、Query、Select等词汇,如无特别说明,都是指使用Select语句编写Query进行数据检索。
- 编写第一个查询 下面的SQL可以查询所有的ERC20代币信息:
select * from tokens.erc20
limit 10- Select 查询语句基本语法介绍 一个典型的SQL查询语句的结构如下所示:
select 字段列表
from 数据表
where 筛选条件
order by 排序字段
limit 返回记录数量字段列表可以逐个列出查询需要返回的字段(数据列),多个字段之间用英文逗号分隔,比如可以这样指定查询返回的字段列表contract_address, decimals, symbol。也可以使用通配符*来表示返回数据表的全部字段。如果查询用到了多个表并且某个字段同时存在于这些表中,我们就需要用table_name.field_name的形式指定需要返回的字段属于哪一个表。
数据表以schema_name.table_name的格式来指定,例如tokens.erc20。我们可以用as alias_name的语法给表指定一个别名,例如:from tokens.erc20 as t。这样就可以同一个查询中用别名t来访问表tokens.erc20和其中的字段。
筛选条件用于按指定的条件筛选返回的数据。对于不同数据类型的字段,适用的筛选条件语法各有不同。字符串(varchar)类型的字段,可以用=,like等条件做筛选。日期时间(datetime)类型的字段可以用>=,<=,between … and …等条件做筛选。使用like条件时,可以用通配符%匹配一个或多个任意字符。多个筛选条件可以用and(表示必须同时满足)或or(表示满足任意一个条件即可)连接起来。
排序字段用于指定对查询结果集进行排序的判断依据,这里是一个或多个字段名称,加上可选的排序方向指示(asc表示升序,desc表示降序)。多个排序字段之间用英文逗号分隔。Order By排序子句还支持按照字段在Select子句中出现的位置来指定排序字段,比如order by 1表示按照Select子句中出现的第一个字段进行排序(默认升序)。
返回记录数量用于指定(限制)查询最多返回多少条满足条件的记录。区块链保存的是海量数据,通常我们需要添加返回记录数量限制来提高查询的效率。
下面我们举例说明如何使用查询的相关部分。注意,在SQL语句中,我们可以–添加单行注释说明。还可以使用/开头和/结尾将多行内容标记为注释说明。注释内容不会被执行。
- 指定返回的字段列表:
select blockchain, contract_address, decimals, symbol -- 逐个指定需要返回的列
from tokens.erc20
limit 10- 添加筛选条件:
select blockchain, contract_address, decimals, symbol
from tokens.erc20
where blockchain = 'ethereum' -- 只返回以太坊区块链的ERC20代币信息
limit 10- 使用多个筛选条件:
select blockchain, contract_address, decimals, symbol
from tokens.erc20
where blockchain = 'ethereum' -- 返回以太坊区块链的ERC20代币信息
and symbol like 'E%' -- 代币符号以字母E开头- 指定排序字段:
select blockchain, contract_address, decimals, symbol
from tokens.erc20
where blockchain = 'ethereum' -- 返回以太坊区块链的ERC20代币信息
and symbol like 'E%' -- 代币符号以字母E开头
order by symbol asc -- 按代币符号升序排列- 指定多个排序字段:
select blockchain, contract_address, decimals, symbol
from tokens.erc20
where blockchain = 'ethereum' -- 返回以太坊区块链的ERC20代币信息
and symbol like 'E%' -- 代币符号以字母E开头
order by decimals desc, symbol asc -- 先按代币支持的小数位数降序排列,再按代币符号升序排列- 使用Limit子句限制返回的最大记录数量:
select *
from tokens.erc20
limit 10Select查询常用的一些函数和关键词
- As定义别名
可以通过使用“as”子句给表、字段定义别名。别名对于表名(或字段名)较长、包含特殊字符或关键字等情况,或者需要对输出字段名称做格式化时,非常实用。别名经常用于计算字段、多表关联、子查询等场景中。
select t.contract_address as "代币合约地址",
t.decimals as "代币小数位数",
t.symbol as "代币符号"
from tokens.erc20 as t
limit 10实际上为了书写更加简洁,定义别名时as关键词可以省略,可以直接将别名跟在表名或字段名后,用一个空格分隔。下面的查询,功能和上一个查询完全相同。
-- 定义别名时,as 关键词可以省略
select t.contract_address "代币合约地址",
t.decimals "代币小数位数",
t.symbol "代币符号"
from tokens.erc20 t
limit 10- Distinct筛选唯一值 通过使用distinct关键词,我们可以筛选出出现在Select子句列表中的字段的唯一值。当Select子句包含多个字段时,返回的是这些字段的唯一值当组合。
select distinct blockchain
from tokens.erc20- Now 获取当前系统日期时间 使用now()可以获得当前系统的日期时间值。我们还可以使用current_date来得到当前系统日期,注意这里不需要加括号。
select now(), current_date- Date_Trunc 截取日期 区块链中的日期时间字段通常是以“年-月-日 时:分:秒”的格式保存的。如果要按天、按周、按月等进行汇总统计,可以使用date_trunc()函数对日期先进行转换。例如:date_trunc(‘day’, block_time)将block_time的值转换为以“天”表示的日期值,date_trunc(‘month’, block_time)将block_time的值转换为以“月”表示的日期值。
select now(),
date_trunc('day', now()) as today,
date_trunc('month', now()) as current_month- Interval获取时间间隔 使用interval ‘2 days’这样的语法,我们可以指定一个时间间隔。支持多种不同的时间间隔表示方式,比如:’12 hours’,‘7 days’,‘3 months’, ’1 year’等。时间间隔通常用来在某个日期时间值的基础上增加或减少指定的间隔以得到某个日期区间。
select now() as right_now,
(now() - interval '2' hour) as two_hours_ago,
(now() - interval '2' day) as two_days_ago,
(current_date - interval '1' year) as one_year_ago- Concat连接字符串 我们可以使用concat()函数将多个字符串连接到一起的到一个新的值。还可以使用更简洁的连接操作符||。
select concat('Hello ', 'world!') as hello_world,
'Hello' || ' ' || 'world' || '!' as hello_world_again- Cast转换字段数据类型 SQL查询种的某些操作要求相关的字段的数据类型一致,比如concat()函数就需要参数都是字符串varchar类型。如果需要将不同类型的数据连接起来,我们可以用cast()函数强制转换为需要的数据类型,比如:cast(25 as string)将数字25转换为字符串“25”。还可以使用data_type ’value string’操作符方式完成类型转换,比如:integer ’123’将字符串转换为数值类型。
select (cast(25 as varchar) || ' users') as user_counts,
integer '123' as intval,
timestamp '2023-04-28 20:00:00' as dt_time- Power求幂 区块链上的ERC20代币通常都支持很多位的小数位。以太坊的官方代币ETH支持18位小数,因为相关编程语言的限制,代币金额通常是以整数形式存贮的,使用时必须结合支持的小数位数进行换算才能得到正确的金额。使用power()函数,或者pow()可以进行求幂操作实现换算。在Dune V2中,可以用简洁的形式表示10的N次幂,例如1e18等价于power(10, 18)。
select 1.23 * power(10, 18) as raw_amount,
1230000000000000000 / pow(10, 18) as original_amount,
7890000 / 1e6 as usd_amountSelect查询进阶
Group By分组与常用汇总函数
SQL中有一些常用的汇总函数,count()计数,sum()求和,avg()求平均值,min()求最小值,max()求最大值等。除了对表中所有数据汇总的情况外,汇总函数通常需要结合分组语句group by来使用,按照某个条件进行分组汇总统计。Group By分组子句的语法为group by field_name,还可以指定多个分组字段group by field_name1, field_name2。与Order By子句相似,也可以按字段在Select子句中出现的位置来指定分组字段,这样可以让我们的SQL更加简洁。例如group by 1表示按第一个字段分组,group by 1, 2表示同时按第一个和第二个字段分组。我们通过一些例子来说明常用汇总函数的用法。
- 统计目前支持的各个区块链的ERC20代币类型数量:
select blockchain, count(*) as token_count
from tokens.erc20
group by blockchain- 统计支持的所有区块链的代币类型总数量、平均值、最小值、最大值:
-- 这里为了演示相关函数,使用了子查询
select count(*) as blockchain_count,
sum(token_count) as total_token_count,
avg(token_count) as average_token_count,
min(token_count) as min_token_count,
max(token_count) as max_token_count
from (
select blockchain, count(*) as token_count
from tokens.erc20
group by blockchain
)- 子查询(Sub Query) 子查询(Sub Query)是嵌套在一个Query中的Query,子查询会返回一个完整的数据集供外层查询(也叫父查询、主查询)进一步查询使用。当我们需要必须从原始数据开始通过多个步骤的查询、关联、汇总操作才能得到理想的输出结果时,我们就可以使用子查询。将子查询放到括号之中并为其赋予一个别名后,就可以像使用其他数据表一样使用子查询了。
在前面的例子中就用到了子查询from ( 子查询语句 ),这里不再单独举例。
- 多表关联(Join) 当我们需要从相关的多个表分别取数据,或者从同一个表分别取不同的数据并连接到一起时,就需要使用多表关联。多表关联的基本语法为:from table_a inner join table_b on table_a.field_name = table_b.field_name。其中table_a和table_b可以是不同的表,也可以是同一个表,可以有不同的别名。
下面的查询使用tokens.erc20与其自身关联,来筛选出同时存在于以太坊区块链和币安区块链上且代币符号相同的记录:
select a.symbol,
a.decimals,
a.blockchain as blockchain_a,
a.contract_address as contract_address_a,
b.blockchain as blockchain_b,
b.contract_address as contract_address_b
from tokens.erc20 a
inner join tokens.erc20 b on a.symbol = b.symbol
where a.blockchain = 'ethereum'
and b.blockchain = 'bnb'
limit 100- 集合(Union) 当我们需要将来自不同数据表的记录合并到一起,或者将由同一个数据表取出的包含不同字段的结果集合并到一起时,可以使用Union或者Union All集合子句来实现。Union会自动去除合并后的集合里的重复记录,Union All则不会做去重处理。对于包括海量数据的链上数据库表,去重处理有可能相当耗时,所以建议尽可能使用Union All以提升查询效率。
因为暂时我们尽可能保持简单,下面演示集合的SQL语句可能显得意义不大。不过别担心,这里只是为了显示语法。后续我们在做数据看板的部分有更合适的例子:
select contract_address, symbol, decimals
from tokens.erc20
where blockchain = 'ethereum'
union all
select contract_address, symbol, decimals
from tokens.erc20
where blockchain = 'bnb'
limit 100- Case 语句 使用Case语句,我们可以基于某个字段的值来生成另一种类型的值,通常是为了让结果更直观。举例来说,ERC20代币表有一个decimals字段,保存各种代币支持的小数位数。如果我们想按支持的小数位数把各种代币划分为高精度、中等精度和低精度、无精度等类型,则可以使用Case语句进行转换。
select (case when decimals >= 10 then 'High precision'
when decimals >= 5 then 'Middle precision'
when decimals >= 1 then 'Low precision'
else 'No precision'
end) as precision_type,
count(*) as token_count
from tokens.erc20
group by 1
order by 2 desc- TE公共表表达式 公共表表达式,即CTE(Common Table Expression),是一种在SQL语句内执行(且仅执行一次)子查询的好方法。数据库将执行所有的WITH子句,并允许你在整个查询的后续任意位置使用其结果。
CTE的定义方式为with cte_name as ( sub_query ),其中sub_query就是一个子查询语句。我们也可以在同一个Query中连续定义多个CTE,多个CTE之间用英文逗号分隔即可。按定义的先后顺序,后面的CTE可以访问使用前面的CTE。在后续数据看板部分的“查询6”中,你可以看到定义多个CTE的示例。将前面子查询的例子用CTE格式改写:
with blockchain_token_count as (
select blockchain, count(*) as token_count
from tokens.erc20
group by blockchain
)
select count(*) as blockchain_count,
sum(token_count) as total_token_count,
avg(token_count) as average_token_count,
min(token_count) as min_token_count,
max(token_count) as max_token_count
from blockchain_token_count创建Dune 看板
背景知识
开始创建看板之前,我们还需要了解一些额外的背景知识。Uniswap是最流行的去中心化金融(DeFi)协议之一,是一套持久的且不可升级的智能合约,它们共同创建了一个自动做市商(AMM),该协议主要提供以太坊区块链上的点对点ERC20代币的交换。Uniswap工厂合约(Factory)部署新的智能合约来创建流动资金池(Pool),将两个ERC20代币资产进行配对,同时设置不同的费率(fee)。流动性(Liquidity)是指存储在Uniswap资金池合约中的数字资产,可供交易者进行交易。流动性提供者(Liquidity Provider,简称LP)是将其拥有的ERC20代币存入给定的流动性池的人。流动性提供者获得交易费用的补偿作为收益,同时也承担价格波动带来的风险。普通用户(Swapper)通过可以在流动资金池中将自己拥有的一种ERC20代币兑换为另一种代币,同时支付一定的服务费。比如你可以在费率为0.30%的USDC-WETH流动资金池中,将自己的USDC兑换为WETH,或者将WETH兑换为USDC,仅需支付少量的服务费即可完成兑换。Uniswap V3协议的工作方式可以简要概括为:工厂合约创建流动资金池(包括两种ERC20代币) -》 LP用户添加对应资产到流动资金池 -》 其他用户使用流动资金池兑换其持有的代币资产,支付服务费 -》 LP获得服务费奖励。
初学者可能对这部分引入的一些概念比较陌生,不过完全不用紧张,你无需了解更多DeFi的知识就可以顺利完成本教程的内容。本篇教程不会深入涉及DeFi协议的各种细节,我们只是想通过实际的案例,让你对“链上数据分析到底分析什么”有一个更感性的认识。在我们将要创建的这个数据看板中,主要使用Uniswap V3的流动资金池作为案例. 对应的数据表为uniswap_v3_ethereum.Factory_evt_PoolCreated。同时,部分查询也用到了前面介绍过的tokens.erc20表。开始之前,你只需要了解这些就足够了:可以创建很多个不同的流动资金池(Pool),每一个流动资金池包含两种不同的ERC20代币(称之为代币对,Pair),有一个给定的费率;相同的代币对(比如USDC-WETH)可以创建多个流动资金池,分别对应不同的收费费率。
Uniswap流动资金池表
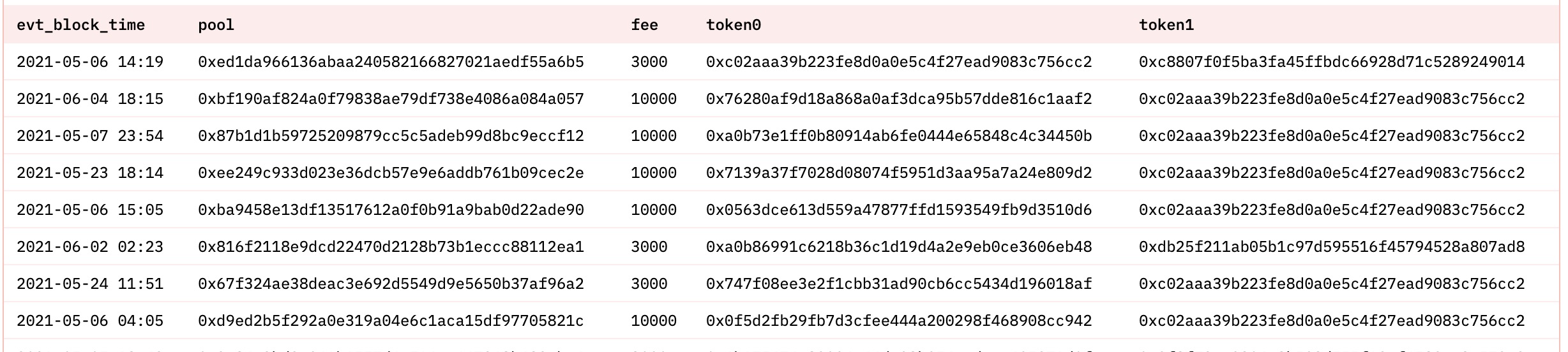
流动资金池表uniswap_v3_ethereum.Factory_evt_PoolCreated的结构如下:
| 列名 | 数据类型 | 说明 |
|---|---|---|
| contract_address | string | 合约地址 |
| evt_block_number | long | 区块编号 |
| evt_block_time | timestamp | 区块被开采的时间 |
| evt_index | integer | 事件的索引编号 |
| evt_tx_hash | string | 事件归属交易的唯一哈希值 |
| fee | integer | 流动资金池的收费费率 |
| pool | string | 流动资金池的地址 |
| tickSpacing | integer | 刻度间距 |
| token0 | string | 资金池中的第一个ERC20代币地址 |
| token1 | string | 资金池中的第二个ERC20代币地址 |
流动资金池表的部分数据如下图所示:
https://decert.me/tutorial/assets/images/image_00-bd5e11fbbbe5d4a3c3ba3b619e957a60.png
{kind=link}
数据看板的主要内容
我们的第一个Dune数据看板将包括以下查询内容。每个查询会输出1个或多个可视化图表。
- 查询流动资金池总数
- 不同费率的流动资金池数量
- 按周汇总的新建流动资金池总数
- 最近30天的每日新建流动资金池总数
- 按周汇总的新建流动资金池总数-按费率分组
- 统计资金池数量最多的代币Token
- 最新的100个流动资金池记录
查询1: 查询流动资金池总数
通过使用汇总函数Count(),我们可以统计当前已创建的全部资金池的数量。
select count(*) as pool_count
from uniswap_v3_ethereum.Factory_evt_PoolCreated我们建议你复制上面的代码,创建并保存查询。保存查询时为其起一个容易识别的名称,比如我使用“uniswap-pool-count”作为这个查询的名称。当然你也可以直接Fork下面列出的参考查询。Fork查询的便利之处是可以了解更多可视化图表的细节。
创建数据看板并添加图表
创建看板
首先请登录进入Dune网站。然后点击头部导航栏中的“My Creation”,再点击下方的“Dashboards”,进入到已创建的数据看板页面https://dune.com/browse/dashboards/authored。要创建新的数据看板,点击右侧边栏中的“New dashboard”按钮即可。在弹出对话框中输入Dashboard的名称,然后点击“Save and open”按钮即可创建新数据看板并进入预览界面。我这里使用“Uniswap V3 Pool Tutorial”作为这个数据看板的名称。
添加查询图表
新创建的数据看板是没有内容的,预览页面会显示“This dashboard is empty.”。我们可以将上一步“查询1”中得到的资金池数量转为可视化图表并添加到数据看板中。在一个新的浏览器Tab中打开“My Creations”页面https://dune.com/browse/queries/authored,找到已保存的“查询1”Query,点击名称进入编辑页面。因为查询已经保存并执行过,我们可以自己点击“New visualization”按钮来新建一个可视化图表。单个数值类型的的查询结果,通常使用计数器(Counter)类型的可视化图表。从下拉列表“Select visualization type”中选择“Counter”,再点击“Add Visualization”按钮。然后可以给这个图表命名,将Title值从默认的“Counter”修改为“流动资金池总数”。最后,通过点击“Add to dashboard“按钮,并在弹出对话框中点击对应数据看板右边的“Add”按钮,就把这个计数器类型的图表添加到了数据看板中。
此时我们可以回到数据看板页面,刷新页面可以看到新添加的可视化图表。点击页面右上方的“Edit”按钮可以对数据看板进行编辑,包括调整各个图表的大小、位置,添加文本组件等。下面是对“流动资金池总数”这个计数器图表调整了高度之后的截图。

添加文本组件
在数据看板的编辑页面,我们可以通过点击“Add text widget”按钮,添加文本组件到看板中。文本组件可以用来为数据看板的核心内容添加说明,添加作者信息等。文本组件支持使用Markdown语法实现一些格式化处理,在添加文本组件的对话框中点击“Some markdown is supported”展开可以看到支持的相关语法。请根据需要自行添加相应的文本组件,这里就不详细说明了。
查询2:不同费率的流动资金池数量
根据我们需要的结果数据的格式,有不同的方式来统计。如果想使用计数器(Counter)类型的可视化图表,可以把相关统计数字在同一行中返回。如果想用一个扇形图(Pie Chart)来显示结果,则可以选择使用Group By分组,将结果数据以多行方式返回。
使用Filter子句:
select count(*) filter (where fee = 100) as pool_count_100,
count(*) filter (where fee = 500) as pool_count_500,
count(*) filter (where fee = 3000) as pool_count_3000,
count(*) filter (where fee = 10000) as pool_count_10000
from uniswap_v3_ethereum.Factory_evt_PoolCreated本查询在Dune上的参考链接:https://dune.com/queries/1454947
这个查询返回了4个输出值,我们为他们添加相应的计数器组件,分别命名为“0.01%资金池数量”、“0.05%资金池数量”等。然后添加到数据看板中,在数据看板编辑界面调整各组件的大小和顺序。调整后的显示效果如下图所示:

使用Group By子句:
select fee,
count(*) as pool_count
from uniswap_v3_ethereum.Factory_evt_PoolCreated
group by 1费率“fee”是数值形式,代表百万分之N的收费费率。比如,3000,代表3000/1000000,即“0.30%”。用fee的值除以10000 (1e4)即可得到用百分比表示的费率。 将数值转换为百分比表示的费率更加直观。我们可以使用修改上面的查询来做到这一点:
select concat(format('%,.2f', fee / 1e4), '%') as fee_tier,
count(*) as pool_count
from uniswap_v3_ethereum.Factory_evt_PoolCreated
group by 1
其中,concat(format(‘%,.2f’, fee / 1e4), ‘%’) as fee_tier部分的作用是将费率转换为百分比表示的值,再连接上“%”符号,使用别名fee_tier输出。关于format()函数的具体语法,可以查看Trino 的帮助(Trino是Dune SQL的底层引擎)。Trino帮助链接:https://trino.io/docs/current/functions.html 。
本查询在Dune上的参考链接:https://dune.com/queries/1455127
我们为这个查询添加一个扇形图图表。点击“New visualization”,从图表类型下拉列表选择“Pie Chart”扇形图类型,点击“Add visualization”。将图表的标题修改为“不同费率的资金池数量”。图表的水平坐标轴(X Column)选择“fee_tier“,垂直坐标轴“Y Column 1”选择“pool_count”。勾选左侧的“Show data label”选项。然后用“Add to dashboard”把这个可视化图表添加到数据看板中。其显示效果如下:

查询3:按周汇总的新建流动资金池总数
要实现汇总每周新建的流动资金池数量的统计,我们可以先在一个子查询中使用date_trunc()函数将资金池的创建日期转换为每周的开始日期(星期一),然后再用Group By进行汇总统计。
select block_date, count(pool) as pool_count
from (
select date_trunc('week', evt_block_time) as block_date,
evt_tx_hash,
pool
from uniswap_v3_ethereum.Factory_evt_PoolCreated
)
group by 1
order by 1本查询在Dune上的参考链接:https://dune.com/queries/1455311
按时间统计的数据,适合用条形图、面积图、折线图等形式来进行可视化,这里我们用条形图。点击“New visualization”,从图表类型下拉列表选择“Bar Chart”条形图类型,点击“Add visualization”。将图表的标题修改为“每周新建资金池数量统计”。图表的水平坐标轴(X Column)选择“block_date“,垂直坐标轴“Y Column 1”选择“pool_count”。取消勾选左侧的“Show chart legend”选项。然后用“Add to dashboard”把这个可视化图表添加到数据看板中。其显示效果如下:

查询4:最近30天的每日新建流动资金池总数
类似的,要实现汇总每天新建的流动资金池数量的统计,我们可以先在一个子查询中使用date_trunc()函数将资金池的创建日期转换为天(不含时分秒值),然后再用Group By进行汇总统计。这里我们使用公共表表达式(CTE)的方式来查询。与使用子查询相比,CTE能让查询逻辑更加直观易懂、定义后可以多次重用以提升效率、也更方便调试。后续的查询都会倾向于使用CTE方式。
with pool_details as (
select date_trunc('day', evt_block_time) as block_date, evt_tx_hash, pool
from uniswap_v3_ethereum.Factory_evt_PoolCreated
where evt_block_time >= now() - interval '29' day
)
select block_date, count(pool) as pool_count
from pool_details
group by 1
order by 1本查询在Dune上的参考链接:https://dune.com/queries/1455382
我们同样使用条形图来做可视化。添加一个条形图类型的新图表,将标题修改为“近30天每日新增资金池数量”。图表的水平坐标轴(X Column)选择“block_date“,垂直坐标轴“Y Column 1”选择“pool_count”。取消勾选左侧的“Show chart legend”选项,同时勾选上“Show data labels”选项。然后把这个可视化图表添加到数据看板中。其显示效果如下:

查询5:按周汇总的新建流动资金池总数-按费率分组
我们可以对分组统计的维度做进一步的细分,按费率来汇总统计每周内新建的流动资金池数量。这样我们可以对比不同费率在不同时间段的流行程度。这个例子中我们演示Group by多级分组,可视化图表数据的条形图的叠加等功能。
with pool_details as (
select date_trunc('week', evt_block_time) as block_date, fee, evt_tx_hash, pool
from uniswap_v3_ethereum.Factory_evt_PoolCreated
)
select block_date,
concat(format('%,.2f', fee / 1e4), '%') as fee_tier,
count(pool) as pool_count
from pool_details
group by 1, 2
order by 1, 2本查询在Dune上的参考链接:https://dune.com/queries/1455535
我们同样使用条形图来做可视化。添加一个条形图类型的新图表,将标题修改为“不同费率每周新建流动资金池数量”。图表的水平坐标轴(X Column)选择“block_date“,垂直坐标轴“Y Column 1”选择“pool_count”。同时,我们需要在“Group by”中选择“fee_tier”作为可视化图表的分组来实现分组显示,同时勾选左侧的“Enable stacking”选项让同一日期同一分组的数据叠加到一起显示。把这个可视化图表添加到数据看板中的显示效果如下:

查询6:统计资金池数量最多的代币Token
如果想分析哪些ERC20代币在Uniswap资金池中更流行(即它们对应的资金池数量更多),我们可以按代币类型来做分组统计。
每一个Uniswap流动资金池都由两个ERC20代币组成(token0和token1),根据其地址哈希值的字母顺序,同一种ERC20代币可能保存在token0中,也可能保存在token1中。所以,在下面的查询中,我们通过使用集合(Union)来得到完整的资金池详细信息列表。
另外,资金池中保存的是ERC20代币的合约地址,直接显示不够直观。Dune社区用户提交的魔法书生成的抽象数据表tokens.erc20保存了ERC20代币的基本信息。通过关联这个表,我们可以取到代币的符号(Symbol),小数位数(Decimals)等。这里我们只需使用代币符号。
因为Uniswap V3 一共有8000多个资金池,涉及6000多种不同的ERC20代币,我们只关注资金池最多的100个代币的数据。下面的查询演示以下概念:多个CTE,Union,Join,Limit等。
with pool_details as (
select token0 as token_address,
evt_tx_hash, pool
from uniswap_v3_ethereum.Factory_evt_PoolCreated
union all
select token1 as token_address,
evt_tx_hash, pool
from uniswap_v3_ethereum.Factory_evt_PoolCreated
),
token_pool_summary as (
select token_address,
count(pool) as pool_count
from pool_details
group by 1
order by 2 desc
limit 100
)
select t.symbol, p.token_address, p.pool_count
from token_pool_summary p
inner join tokens.erc20 t on p.token_address = t.contract_address
order by 3 desc本查询在Dune上的参考链接:https://dune.com/queries/1455706
我们同样使用条形图来做可视化。添加一个条形图类型的新图表,将标题修改为“不同ERC20代币的资金池数量(Top 100)”。图表的水平坐标轴(X Column)选择“symbol“,垂直坐标轴“Y Column 1”选择“pool_count”。为了保持排序顺序(按数量从多到少),取消勾选右侧的“Sort values”选项。虽然我们限定了只取前面的100个代币的数据,从查询结果中仍然可以看到,各种Token的资金池数量差异很大,最多的有5000多个,少的则只有几个。为了让图表更直观,请勾选右侧的“Logarithmic”选项,让图表数据以对数化后显示。把这个可视化图表添加到数据看板中的显示效果如下:

由于对数化显示处理从视觉上弱化了差异值,我们可以同时添加一个“Table“数据表类型的可视化图表,方便用户查看实际的数值。继续为这个查询添加新的可视化图表,选择“Table”图表类型。标题设置为“前100种ERC20代币的资金池数量统计”。可以根据需要对这个可视化表格的相关选项做调整,然后将其添加到Dashboard中。

你可能留意到表格返回的数据实际上没有100行,这是因为部分新出现的代币可能还未被添加到到Dune到数据表中。
查询7:最新的100个流动资金池记录
当某个项目方发行了新的ERC20代币并支持上市流通时,Uniswap用户可能会在第一时间创建相应的流动资金池,以让其他用户进行兑换。比如,XEN代币就是近期的一个比较轰动的案例。
我们可以通过查询最新创建的资金池来跟踪新的趋势。下面的查询同样关联tokens.erc20表获,通过不同的别名多次关联相同的表来获取不同代币的符号。本查询还演示了输出可视化表格,连接字符串生成超链接等功能。
with last_crated_pools as (
select p.evt_block_time,
t0.symbol as token0_symbol,
p.token0,
t1.symbol as token1_symbol,
p.token1,
p.fee,
p.pool,
p.evt_tx_hash
from uniswap_v3_ethereum.Factory_evt_PoolCreated p
inner join tokens.erc20 t0 on p.token0 = t0.contract_address and t0.blockchain = 'ethereum'
inner join tokens.erc20 t1 on p.token1 = t1.contract_address and t1.blockchain = 'ethereum'
order by p.evt_block_time desc
limit 100
)
select evt_block_time,
token0_symbol || '-' || token1_symbol || ' ' || format('%,.2f', fee / 1e4) || '%' as pool_name,
'<a href=https://etherscan.io/address/' || cast(pool as varchar) || ' target=_blank>' || cast(pool as varchar) || '</a>' as pool_link,
token0,
token1,
fee,
evt_tx_hash
from last_crated_pools
order by evt_block_time desc本查询在Dune上的参考链接:https://dune.com/queries/1455897
我们为查询添加一个“Table“数据表类型的可视化图表,将标题设置为“最新创建的资金流动池列表”。可以根据需要对这个可视化表格的相关选项做调整,然后将其添加到Dashboard中。

熟悉数据表
以Dune为代表的数据平台将区块链数据解析保存到数据库中。数据分析师针对具体的分析需求,编写SQL从相应的数据表中查询数据进行分析。目前市面上流行的区块链越来越多,新的区块链还在不断出现,部署到不同区块链上的各类项目也越来越丰富。如何快速找到待分析的项目对应的数据表,理解掌握对应数据表里每个字段的含义和用途,是每一个分析师必须掌握的技能。
Dune V2数据引擎数据表介绍
Dune 平台的数据集分为几种不同的类型:
- 原始数据(Raw):存储了未经编辑的区块链数据。包括blocks、transactions、traces等数据表。这些原始数据表保存了最原始的链上数据,可用于灵活的数据分析。
- 已解析项目(Decoded Projects):存储了经过解码后的智能合约事件日志及调用数据表。比如Uniswap V3相关的表,Opensea Seaport相关的表等。Dune使用智能合约的 ABI(Application Binary Interface) 和标准化代币智能合约的接口标准(ERC20、ERC721 等)来解析数据,并将每一个事件或者方法调用的数据单独保存到一个数据表中。
- 魔法表(Spells):魔法表在Dune V1中也叫抽象表(Abstractions),是Dune和社区用户一起通过spellbook github存储库来建设和维护,并通过dbt编译生成的数据表,这些数据表通常使用起来更为便捷高效。
- 社区贡献数据(Community):这部分是由第三方合作组织提供的数据源,自动接入到Dune的数据集里供分析师使用。目前Dune上主要有flashbots和reservoir两个社区来源数据集。
- 用户生成的数据表(User Generated Tables):目前Dune V2引擎尚未开放此功能,只能通过魔法表的方式来上传(生成)自定义数据表。
在Dune平台的Query编辑页面,我们可以通过左边栏来选择或搜索需要的数据表。这部分界面如下图所示:

图片中间的文本框可以用于搜索对应的数据模式(Schema)或数据表。比如,输入erc721将筛选出名称包含这个字符串的所有魔法表和已解析项目表。图片中上方的红框部分用于选择要使用的数据集,途中显示的“v2 Dune SQL”就是我们通常说的“Dune SQL引擎”。Dune 将于2023年下半年全面过渡到Dune SQL引擎,所以现在大家只需熟悉Dune SQL的语法即可。
上图中下方的红框圈出的是前面所述Dune V2 引擎目前支持的几大类数据集。点击粗体分类标签文字即可进入下一级浏览该类数据集中的各种数据模式以及各模式下的数据表名称。点击分类标签进入下一级后,你还可以看到一个默认选项为“All Chains”的下拉列表,可以用来筛选你需要的区块链下的数据模式和数据表。当进入到数据表层级时,点击表名可以展开查看表中的字段列表。点击表名右边的“》”图标可以将表名(格式为schema_name.table_name插入到查询编辑器中光标所在位置。分级浏览的同时你也可以输入关键字在当前浏览的层级进一步搜索过滤。不同类型的数据表有不同的层次深度,下图为已解析数据表的浏览示例。

原始数据表
区块链中典型的原始数据表包括:区块表(Blocks)、交易表(Transactions)、内部合约调用表(Traces)、事件日志表(Logs)以及合约创建跟踪表(creation_traces)。原始数据表的命名格式为blockchain_name.table_name,例如arbitrum.logs,bnb.blocks,ethereum.transactions,optimism.traces等。部分区块链有更多或者更少的原始数据表,我们使用以太坊为例做简单介绍。
区块表(ethereum.blocks)
区块(Block)是区块链的基本构建组件。一个区块包含多个交易记录。区块表记录了每一个区块生成的日期时间(block time)、对应的区块编号(block number)、区块哈希值、难度值、燃料消耗等信息。除了需要分析整个区块链的区块生成状况、燃料消耗等场景外,我们一般并不需要关注和使用区块表。其中最重要的是区块生成日期时间和区块编号信息,它们几乎都同时保存到了其他所有数据表中,只是对应的字段名称不同。
交易表(ethereum.transactions)
交易表保存了区块链上发生的每一个交易的详细信息(同时包括成功交易和失败交易)。以太坊的交易表结构如下图所示:

交易表中最常用的字段包括block_time(或block_number)、from、to、value、hash、success等。Dune V2引擎是基于列存贮的数据库,每个表里的数据是按列存贮的。按列存贮的数据表无法使用传统意义上的索引,而是依赖于保存有“最小值/最大值”属性的元数据来提升查询性能。对于数值类型或者日期时间类型,可以很容易计算出一组值中的最小值/最大值。相反,对于字符串类型,因为长度可变,很难高效计算出一组字符串数据中的最小值/最大值。这就导致V2引擎在做字符串类型的查询时比较低效,所以我们通常需要同时结合使用日期时间类型或者数值类型的过滤条件来提升查询执行性能。如前所述,block_time, block_number字段几乎存在于所有的数据表中(在不同类型数据表中名称不同),我们应充分利用它们来筛选数据,确保查询可以高效执行。更多的相关信息可以查看Dune V2查询引擎工作方式来了解。
内部合约调用表(ethereum.traces)
一个交易(Transactions)可以触发更多的内部调用操作,一个内部调用还可能进一步触发更多的内部调用。这些调用执行的信息会被记录到内部合约调用表。内部合约调用表主要包括block_time、block_number、tx_hash、success、from、to、value、type等字段。
内部合约调用表有两个最常见的用途:
- 用于跟踪区块链原生代币(Token)的转账详情或者燃料消耗。比如,对于以太坊,用户可能通过某个DAPP的智能合约将ETH转账到另一个(或者多个)地址。这种情况下,ethereum.transactions表的value字段并没有保存转账的ETH的金额数据,实际的转账金额只保存在内部合约调用表的value值中。另外,由于原生代币不属于ERC20代币,所以也无法通过ERC20协议的Transfer事件来跟踪转账详情。区块链交易的燃料费用也是用原生代币来支付的,燃料消耗数据同时保存于交易表和内部合约调用表。一个交易可能有多个内部合约调用,调用内部还可以发起新的调用,这就导致每个调用的from,to并不一致,也就意味着具体支付调用燃料费的账户地址不一致。所以,当我们需要计算某个地址或者一组地址的原生代币ETH余额时,只有使用ethereum.traces表才能计算出准确的余额。 这个查询有计算ETH余额的示例:ETH顶级持有者余额
- 用于筛选合约地址。以太坊上的地址分为两大类型,外部拥有的地址(External Owned Address, EOA)和合约地址(Contract Address)。EOA外部拥有地址是指由以太坊用户拥有的地址,而合约地址是通过部署智能合约的交易来创建的。当部署新的智能合约时,ethereum.traces表中对应记录的type字段保存的值为create。我们可以使用这个特征筛选出智能合约地址。Dune V2里面,Dune团队已经将创建智能合约的内部调用记录整理出来,单独放到了表ethereum.creation_traces中。通过直接查询这个表就能确定某个地址是不是合约地址。
事件日志表(ethereum.logs)
事件日志表存储了智能合约生成的所有事件日志。当我们需要查询分析那些尚未被解码或者无法解码(由于代码非开源等原因)的智能合约,事件日志表非常有用。通常,我们建议优先使用已解析的数据表,这样可以提高效率并降低在查询中引入错误的可能性。但是,有时由于时效性(合约还未来得及被解码)或者合约本身不支持被解码的原因,我们就不得不直接访问事件日志表来查询数据进行分析。
事件日志表主要包括block_time、block_number、tx_hash、contract_address、topic1、topic2、topic3、topic4、data等字段。使用时需要注意的要点包括:
- topic1 存贮的是事件对应的方法签名的哈希值。我们可以同时使用contract_address 和topic1筛选条件来找出某个智能合约的某个方法的全部事件日志记录。
- topic2、topic3、topic4 存贮的是事件日志的可索引参数(主题),每个事件最多支持3个可索引主题参数。当索引主题参数不足3个时,剩余的字段不保存任何值。具体到每一个事件,这几个主题参数所保存的值各不相同。我们可以结合EtherScan这样的区块链浏览器上显示的日志来对照确认每一个主题参数代表什么含义。或者也可以查阅对应智能合约的源代码来了解事件参数的详细定义。
- data存贮的是事件参数中没有被标记为索引主题类型的其他字段的16进制的组合值,字符串格式,以0x开头,每个参数包括64个字符,实际参数值不足64位则在左侧填充0来补足位数。当我们需要从data里面解析数据时,就要按照上述特征,从第3个字符开始,以每64个字符为一组进行拆分,然后再按其实际存贮的数据类型进行转换处理(转为地址、转为数值或者字符串等)。
这里是一个直接解析logs表的查询示例:https://dune.com/queries/1510688。你可以复制查询结果中的tx_hash值访问EtherScan站点,切换到“Logs”标签页进行对照。下图显示了EtherScan上的例子:

已解析项目表
已解析项目表是数量最庞大的数据表类型。当智能合约被提交到Dune进行解析时,Dune为其中的每一个方法调用(Call)和事件日志(Event)生成一个对应的专用数据表。在Dune的查询编辑器的左边栏中,这些已解析项目数据表按如下层级来逐级展示:
category name -> project name (namespace) -> contract name -> function name / event name
-- Sample
Decoded projects -> uniswap_v3 -> Factory -> PoolCreated已解析项目表的命名规则如下: 事件日志:projectname_blockchain.contractName_evt_eventName 函数调用:projectname_blockchain.contractName_call_functionName 例如,上面的Uniswap V3 的 PoolCreated 事件对应的表名为uniswap_v3_ethereum.Factory_evt_PoolCreated。
一个非常实用的方法是查询ethereum.contracts魔法表来确认你关注的智能合约是否已经被解析。这个表存贮了所有已解析的智能合约的记录。如果查询结果显示智能合约已被解析,你就可以用上面介绍的方法在查询编辑器界面快速浏览或搜索定位到对应的智能合约的数据表列表。如果查询无结果,则表示智能合约尚未被解析,你可以将其提交给Dune团队去解析处理:提交解析新合约。可以提交任意的合约地址,但必须是有效的智能合约地址并且是可以被解析的(Dune能自动提取到其ABI代码或者你有它的ABI代码)。
魔法表
魔法书(Spellbook)是一个由Dune社区共同建设的数据转换层项目。魔法(Spell)可以用来构建高级抽象表格,魔法可以用来查询诸如 NFT 交易表等常用概念数据。魔法书项目可自动构建并维护这些表格,且对其数据质量进行检测。 Dune社区中的任何人都可以贡献魔法书中的魔法,参与方式是提交github PR,需要掌握github源代码管理库的基本使用方法。如果你希望参与贡献魔法表,可以访问Dune Spellbook文档了解详情。
Dune社区非常活跃,已经创建了非常多的魔法表。其中很多魔法表已被广泛使用在我们的日常数据分析中,我们在这里对重要的魔法表做一些介绍。
价格信息表(prices.usd,prices.usd_latest)
价格信息表prices.usd记录了各区块链上主流ERC20代币的每分钟价格。当我们需要将将多种代币进行统计汇总或相互对比时,通常需要关联价格信息表统一换算为美元价格和金额后再进行汇总或对比。价格信息表目前提供了以太坊、BNB、Solana等链的常见ERC20代币价格信息,精确到每分钟。如果你需要按天或者按小时的价格,可以通过求平均值的方式来计算出平均价格。下面两个示例查询演示了两种同时获取多个token的每日价格的方式:
- 获取每日平均价格
- 获取每天的最后一条价格数据 最新价格表(prices.usd_latest)提供了相关ERC20代币的最新价格数据。
DeFi交易信息表(dex.trades,dex_aggregator.trades)
DeFi交易信息表dex.trades提供了主流DEX交易所的交易数据,因为各种DeFi项目比较多,Dune社区还在进一步完善相关的数据源,目前已经集成的有uniswap、sushiswap、curvefi、airswap、clipper、shibaswap、swapr、defiswap、dfx、pancakeswap_trades、dodo等DEX数据。DeFi交易信息表是将来自不同项目的交易信息合并到一起,这些项目本身也有其对应的魔法表格,比如Uniswap 有uniswap.trades,CurveFi有curvefi_ethereum.trades等。如果我们只想分析单个DeFi项目的交易,使用这些项目特有的魔法表会更好。
DEX聚合器交易表dex_aggregator.trades保存了来自DeFi聚合器的交易记录。这些聚合器的交易通常最终会提交到某个DEX交易所执行。单独整理到一起可以避免与dex.trades记录重复计算。编写本文时,暂时还只有cow_protocol的数据。
Tokens表(tokens.erc20,tokens.nft)
Tokens表目前主要包括ERC20代币表tokens.erc20和NFT表(ERC721)tokens.nft。tokens.erc20表记录了各区块链上主流ERC20代币的定义信息,包括合约地址、代币符号、代币小数位数等。tokens.nft表记录了各NFT项目的基本信息,这个表的数据源目前还依赖社区用户提交PR来进行更新,可能存在更新延迟、数据不完整等问题。由于区块链上数据都是已原始数据格式保存的,金额数值不包括小数位数,我们必须结合tokens.erc20中的小数位数才能正确转换出实际的金额数值。
ERC代表信息表(erc20_ethereum.evt_Transfer,erc721_ethereum.evt_Transfer等)
ERC代币信息表分别记录了ERC20, ERC721(NFT),ERC1155等几种代币类型的批准(Approval)和转账(Transfer)记录。当我们要统计某个地址或者一组地址的ERC代币转账详情、余额等信息是,可以使用这一组魔法表。
ENS域名信息表(ens.view_registrations等)
ENS域名信息相关的表记录了ENS域名注册信息、反向解析记录、域名更新信息等。
标签信息表(labels.all等)
标签信息表是一组来源各不相同的魔法表,允许我们将钱包地址或者合约地址关联到一个或者一组文字标签。其数据来源包括ENS域名、Safe钱包、NFT项目、已解析的合约地址等多种类型。当我们的查询中希望把地址以更直观更有可读性的方式来显示是,可以通过Dune内置的get_labels()函数来使用地址标签。
余额信息表(balances_ethereum.erc20_latest等)
余额信息表保存了每个地址每天、每小时、和最新的ERC20, ERC721(NFT),ERC1155几种代币的余额信息。如果我们要计算某组地址的最新余额,或者跟踪这些地址的余额随时间的变化情况,可以使用这一组表。
NFT交易信息表(nft.trades等)
NFT交易信息表记录了各NFT交易平台的NFT交易数据。目前集成了opensea、magiceden、looksrare、x2y2、sudoswap、foundation、archipelago、cryptopunks、element、superrare、zora、blur等相关NFT交易平台的数据。跟DeFi交易数据类似,这些平台也各自有对应的魔法表,比如opensea.trades。当只需分析单个平台时,可以使用它特有的魔法表。
其他魔法表
除了上面提到的魔法表之外,还有很多其他的魔法表。Dune的社区用户还在不断创建新的魔法表。要了解进一步的信息,可以访问Dune 魔法书文档网站。
社区贡献数据和用户生成数据表
如前文所述,目前Dune上主要有flashbots和reservoir两个社区来源数据集。Dune文档里面分别对这两个数据集做了简介
Dune社区来源数据表: https://dune.com/docs/reference/tables/community/
SixdegreeLab介绍
SixdegreeLab(@SixdegreeLab)是专业的链上数据团队,我们的使命是为用户提供准确的链上数据图表、分析以及洞见,并致力于普及链上数据分析。通过建立社区、编写教程等方式,培养链上数据分析师,输出有价值的分析内容,推动社区构建区块链的数据层,为未来广阔的区块链数据应用培养人才。
实践案例 : 制作Lens Protocol的数据看板
Lens协议是什么?
来自Lens官网的介绍整理如下: Lens协议(Lens Protocol,简称 Lens)是Polygon区块链上的 Web3 社交图谱生态系统。它旨在让创作者拥有自己与社区之间的联系,形成一个完全可组合的、用户拥有的社交图谱。该协议从一开始就考虑到了模块化,允许添加新功能和修复问题,同时确保用户拥有的内容和社交关系不可变。Lens旨在解决现有社交媒体网络中的一些主要问题。Web2 网络都从其专有的集中式数据库中读取数据。用户的个人资料、朋友关系和内容被锁定在特定网络中,其所有权归网络运营商拥有。各网络之间互相竞争,争夺用户注意力,变成一种零和游戏。Lens通过成为用户拥有的、任何应用程序都可以接入的开放社交图谱来纠正这一点。由于用户拥有自己的数据,他们可以将其带到任何基于Lens协议构建的应用程序中。作为其内容的真正所有者,创作者不再需要担心基于单个平台的算法和政策的突然变化而失去他们的内容、观众和收入来源。此外,使用Lens协议的每个应用程序都有益于整个生态系统,从而将零和游戏变成了协作游戏。
Lens协议里面主要涉及以下角色(实体):个人资料(Profile)、出版物(Publication)、评论(Comment)、镜像(Mirror)、收藏(Collect))、关注(Follow)。同时,协议里面存在3种类型的NFT,即:个人资料NFT(Profile NFT)、关注NFT(Follow NFT)、收藏NFT(Collect NFT)。
Lens上的典型使用场景包括:
- 创作者注册创建他们的Profile,铸造其专属的ProfileNFT。可以设置个性化名称(Profile Handle Name,可简单类比为域名,即“Lens域名”)。同时,可以设置账号头像图片URL、被关注时的规则(通过设置特殊的规则,可以产生收益,比如可以设置用户需要支付一定的费用才能关注Profile)。目前仅许可名单内的地址可以创建个人资料账号。
- 创作者发布内容出版物(Publication),包括文章(帖子,Post)、镜像(Mirror)、评论(Comment)等。
- 普通用户可以关注创作者,收藏感兴趣的出版物。
- 在相关操作步骤中,3种不同类型NFT被分别铸造并传输给不同的用户地址。
Lens 协议主要分析内容
针对Lens这样的项目,我们可以从整体上分析其概况,也可以从不同角度、针对其中的不同角色类型进行数据分析。以下是一些可以分析的内容的概况:
- 总用户数量、总的创作者数量、创作者占比等
- 总出版物数量、总评论数量、总镜像数量、总关注数量、总收藏数量等
- 用户相关的分析:每日新增用户数量、每日新增创作者数量、每日活跃用户数量、活跃创作者数量、用户整体活跃度的变化趋势等
- Lens账号个性化域名的相关分析:域名注册数量、不同类型域名的注册情况(纯数字、纯字母、不同长度)等
- 创作者的活跃度分析:发布出版物的数量、被关注的次数、被镜像的次数、最热门创作者等
- 出版物的相关分析:内容发布数量、增长趋势、被关注次数、被收藏次数、最热门出版物等
- 关注的相关分析:关注的数量及其变化趋势、关注者的成本分析、关注创作者最多的用户等
- 收藏的相关分析:每日收藏数量、热门收藏等
- 创作者的收益分析:通过关注产生的收益、其他收益等
- 从NFT的角度进行相关分析:每日铸造数量、涉及的成本(关注费用)等 可以分析的内容非常丰富。在这个看板中,我们仅使用部分内容做案例。其他内容请大家分别去尝试分析。
数据表介绍
在Lens的官方文档已部署的智能合约页面,提示使用LensHub代理(LensHub Proxy)这个智能合约作为交互的主要合约。除了少部分和NFT相关的查询需要用到智能合约FollowNFT下的数据表外,我们基本上主要关注LensHub这个智能合约下面的已解析表就可以了。下图列出了这个智能合约下部分数据表。

之前的教程提过,已解析的智能合约数据表有两大类型:事件日志表(Event Log)和函数调用表(Function Call)。两种类型的表分别以:projectname_blockchain.contractName_evt_eventName和:projectname_blockchain.contractName_call_functionName格式命名。浏览LensHub合约下的表格列表,我们可以看到下面这些主要的数据表:
- 收藏表(collect/collectWithSig)
- 评论表(comment/commentWithSig)
- 个人资料表(createProfile)
- 关注表(follow/followWithSig)
- 镜像表(mirror/mirrorWithSig)
- 帖子表(post/postWithSig)
- Token传输表(Transfer)
除了Token传输表是事件表之外,上述其他表格都是函数调用表。其中后缀带有WithSig的数据表,表示通过签名(Signature)授权来执行的操作。通过签名授权,可以方便地通过API或者允许其他授权方代表某个用户执行某项操作。当我们分析帖子表等类型时,需要将相关表里的数据集合到一起进行分析。
大家可以在列表中看到还有其他很多不同方法的数据表,由于这些表全部都是在LensHub智能合约下生成的,所以他们交互的contract_address全部都是LensHub这个地址,即0xdb46d1dc155634fbc732f92e853b10b288ad5a1d。当我们要分析Lens的总体用户数据时,应该使用polygon.transactions 原始表,查询其中与这个合约地址交互的数据,这样才能得到完整的数据。
Lens协议概览分析
通过查看LensHub智能合约创建交易详情,我们可以看到该智能合约部署与2022年5月16日。当我们查询polygon.transactions原始表这样的原始数据表时,通过设置日期时间过滤条件,可以极大地提高查询执行性能。
总交易数量和总用户数量
如前所述,最准确的查询用户数量的数据源是polygon.transactions原始表,我们可以使用如下的query来查询Lens当前的交易数量和总用户数量。我们直接查询发送给LensHub智能合约的全部交易记录,通过distinct关键字来统计独立用户地址数量。由于我们已知该智能合约的创建日期,所以用这个日期作为过滤条件来优化查询性能。
select count(*) as transaction_count,
count(distinct "from") as user_count -- count unique users
from polygon.transactions
where "to" = 0xdb46d1dc155634fbc732f92e853b10b288ad5a1d -- LensHub
and block_time >= date('2022-05-16') -- contract creation date创建一个新的查询,使用上面的SQL代码,运行查询得到结果后,保存Query。然后为其添加两个Counter类型到可视化图表,标题分别设置为“Lens Total Transactions”和“Lens Total Users”。
现在我们可以将可视化图表添加到数据看板。由于这是我们的第一个查询,我们可以在添加可视化图表到数据看板的弹出对话框中创建新的数据看板。切换到第一个Counter,点击“Add to dashboard”按钮,在对话框中,点击底部的“New dashboard”按钮,输入数据看板的名称后,点击“Save dashboard”按钮创建空白的数据看板。我这里使用“Lens Protocol Ecosystem Analysis”作为看板的名称。保存之后我们就可以在列表中看到刚创建的数据看板,点击其右边的“Add”按钮,就可以将当前Counter添加到数据看板中。关闭对话框后切换到另一个Counter,也将其添加到新创建的数据看板。
此时,我们可以点击Dune网站头部的“My Creations”链接,再选择“Dashboards” Tab来切换到数据看板列表。点击我们新创建的看板名称,进入看板的预览界面。我们可以看到刚才添加的两个Counter类型可视化图表。在这里,通过点击“Edit”按钮进入编辑模式,你可以对图表的大小、位置做相应的调整,可以通过点击“”按钮来添加文本组件,对数据看板做一些说明或者美化。下图是调整后的数据看板的界面示例。

按天统计的交易数量和独立用户数量
要想分析Lens协议在活跃度方面的增长变化趋势,我们可以创建一个查询,按日期来统计每天的交易数量和活跃用户地址数量。通过在查询中添加block_time字段并使用date_trunc()函数将其转换为日期(不含时分秒数值部分),结合group by查询子句,我们就可以统计出每天的数据。查询代码如下所示:
select date_trunc('day', block_time) as block_date,
count(*) as transaction_count,
count(distinct "from") as user_count
from polygon.transactions
where "to" = 0xdb46d1dc155634fbc732f92e853b10b288ad5a1d -- LensHub
and block_time >= date('2022-05-16') -- contract creation date
group by 1
order by 1保存查询并为其添加两个Bar Chart类型的可视化图表,Y column 1对应的字段分别选择transaction_count和user_count,可视化图表的标题分别设置为“Lens Daily Transactions”和“Lens Daily Users”。将它们分别添加到数据看板中。效果如下图所示:

通常在按日期统计查询到时候,我们可以按日期将相关数据汇总到一起,计算其累计值并将其与每日数据添加到同一张可视化图表中,以便对整体的数据增长趋势有更直观的认识。通过使用sum() over ()窗口函数,可以很方便地实现这个需求。为了保持逻辑简单易懂,我们总是倾向于使用CTE来将复杂的查询逻辑分解为多步。将上面的查询修改为:
with daily_count as (
select date_trunc('day', block_time) as block_date,
count(*) as transaction_count,
count(distinct "from") as user_count
from polygon.transactions
where "to" = 0xdb46d1dc155634fbc732f92e853b10b288ad5a1d -- LensHub
and block_time >= date('2022-05-16') -- contract creation date
group by 1
order by 1
)
select block_date,
transaction_count,
user_count,
sum(transaction_count) over (order by block_date) as accumulate_transaction_count,
sum(user_count) over (order by block_date) as accumulate_user_count
from daily_count
order by block_date查询执行完毕后,我们可以调整之前添加的两个可视化图表。分别在Y column 2下选择accumulate_transaction_count和accumulate_user_count将它们作为第二个指标值添加到图表中。由于累计值跟每天的数值往往不在同一个数量级,默认的图表显示效果并不理想。我们可以通过选择“Enable right y-axis”选项,然后把新添加的第二列设置为使用右坐标轴,同时修改其“Chart Type”为“Area”(或者“Line”,“Scatter”),这样调整后,图表的显示效果就比较理想了。
为了将每日交易数量与每日活跃用户数量做对比,我们可以再添加一个可视化图表,标题设置为“Lens Daily Transactions VS Users”,在Y轴方向分别选择transaction_count和user_count列。同样,因为两项数值不在同一个数量级,我们启用右侧坐标轴,将user_count设置为使用右坐标轴,图表类型选择“Line”。也将这个图表添加到数据看板。通过查看这个图表,我们可以看到,在2022年11月初的几天里,Lens的每日交易量出现了一个新的高峰,但是每日活跃用户数量的增长则没有那么明显。
这里需要额外说明的是,因为同一个用户可能中不同的日期都有使用Lens,当我们汇总多天的数据到一起时,累计得到的用户数量并不代表实际的独立用户总数,而是会大于实际用户总数。如果需要统计每日新增的独立用户数量及其总数,我们可以先取得每个用户最早的交易记录,然后再用相同的方法按天汇总统计。具体这里不再展开说明,请大家自行尝试。另外如果你想按周、按月来统计,只需Fork这个查询,修改date_trunc()函数的第一个参数为“week”或者“month”即可实现。作为对比,我们Fork并修改了一个按月统计的查询,只将其中的“”加到了数据看板中。
调整完成后,数据看板中的图表会自动更新为最新的显示结果,如下图所示。

创作者个人资料(Profile)数据分析
Lens的创作者个人资料账号目前仅限于许可白名单内的用户来创建,创建个人资料的数据保存在createProfile表中。用下面的查询,我们可以计算出当前已经创建的个人资料的数量。
select count(*) as profile_count
from lens_polygon.LensHub_call_createProfile
where call_success = true -- Only count success calls创建一个Counter类型的可视化图表,Title设置为“Total Profiles”,将其添加到数据看板中。
我们同样关心创作者个人资料随日期的变化和增长情况。用下面的查询可以统计出每日、每月的个人资料创建情况。
with daily_profile_count as (
select date_trunc('day', call_block_time) as block_date,
count(*) as profile_count
from lens_polygon.LensHub_call_createProfile
where call_success = true
group by 1
order by 1
)
select block_date,
profile_count,
sum(profile_count) over (order by block_date) as accumulate_profile_count
from daily_profile_count
order by block_date用类似的方法创建并添加可视化图表到数据看板。显示效果如下图所示:

创作者个人资料域名分析
Lens致力于打造一个社交图谱生态系统,每个创作者可以给自己的账号设置一个个性化的名称(Profile Handle Name),这也是通常大家说的Lens域名。与ENS等其他域名系统类似,我们会关注一些短域名、纯数字域名等的注册情况、不同字符长度的域名已注册数量等信息。在createProfile表中,字段vars以字符串格式保存了一个json对象,里面就包括了用户的个性化域名。在Dune V2中,我们可以直接使用:符号来访问json字符串中的元素的值,例如用vars:handle获取域名信息。
使用下面的SQL,我们可以获取已注册Lens域名的详细信息:
select json_value(vars, 'lax $.to') as user_address,
json_value(vars, 'lax $.handle') as handle_name,
replace(json_value(vars, 'lax $.handle') , '.lens', '') as short_handle_name,
call_block_time,
output_0 as profile_id,
call_tx_hash
from lens_polygon.LensHub_call_createProfile
where call_success = true为了统计不同长度、不同类型(纯数字、纯字母、混合)Lens域名的数量以及各类型下已注册域名的总数量,我们可以将上面的查询放到一个CTE中。使用CTE的好处是可以简化逻辑(你可以按顺序分别调试、测试每一个CTE)。同时,CTE一经定义,就可以在同一个查询的后续SQL脚本中多次使用,非常便捷。鉴于查询各类域名的已注册总数量和对应不同字符长度的已注册数量都基于上面的查询,我们可以在同一个查询中将它们放到一起。因为前述统计都需要区分域名类型,我们在这个查询中增加了一个字段handle_type来代表域名的类型。修改后的查询代码如下:
with profile_created as (
select json_value(vars, 'lax $.to') as user_address,
json_value(vars, 'lax $.handle') as handle_name,
replace(json_value(vars, 'lax $.handle'), '.lens', '') as short_name,
(case when regexp_like(replace(json_value(vars, 'lax $.handle'), '.lens', ''), '^[0-9]+$') then 'Pure Digits'
when regexp_like(replace(json_value(vars, 'lax $.handle'), '.lens', ''), '^[a-z]+$') then 'Pure Letters'
else 'Mixed'
end) as handle_type,
call_block_time,
output_0 as profile_id,
call_tx_hash
from lens_polygon.LensHub_call_createProfile
where call_success = true
),
profiles_summary as (
select (case when length(short_name) >= 20 then 20 else length(short_name) end) as name_length,
handle_type,
count(*) as name_count
from profile_created
group by 1, 2
),
profiles_total as (
select count(*) as total_profile_count,
sum(case when handle_type = 'Pure Digits' then 1 else 0 end) as pure_digit_profile_count,
sum(case when handle_type = 'Pure Letters' then 1 else 0 end) as pure_letter_profile_count
from profile_created
)
select cast(name_length as varchar) || ' Chars' as name_length_type,
handle_type,
name_count,
total_profile_count,
pure_digit_profile_count,
pure_letter_profile_count
from profiles_summary
join profiles_total on true
order by handle_type, name_length将上述可视化图表全部添加到数据看板中,调整显示顺序后,如下图所示:

已注册域名搜索
除了对已注册Lens域名的分布情况的跟踪,用户也关注已注册域名的详细情况。为此,可以提供一个搜索功能,允许用户搜索已注册域名的详细列表。因为目前已经注册了约10万个Lens账号,我们在下面的查询中限制最多返回10000条搜索结果。
首先,我们可以在查询中定义一个参数{{name_contains}}(Dune 使用两个花括号包围住参数名称,默认参数类型为字符串Text类型)。然后使用like关键词以及%通配符来搜索名称中包含特定字符的域名:
with profile_created as (
select json_value(vars, 'lax $.to') as user_address,
json_value(vars, 'lax $.handle') as handle_name,
replace(json_value(vars, 'lax $.handle'), '.lens', '') as short_name,
call_block_time,
output_0 as profile_id,
call_tx_hash
from lens_polygon.LensHub_call_createProfile
where call_success = true
)
select call_block_time,
profile_id,
handle_name,
short_name,
call_tx_hash
from profile_created
where short_name like '%{{name_contains}}%' -- 查询名称包含输入的字符串的域名
order by call_block_time desc
limit 1000在查询执行之前,Dune 引擎会用输入的参数值替换SQL语句中的参数名称。当我们输入“john”时,where short_name like ‘%{{name_contains}}%’子句会被替换为where short_name like’%john%’,其含义就是搜索short_name包含字符串john的所有域名。注意虽然参数类型是字符串类型,但是参数替换时不会字段给我们添加前后的单引号。单引号需要我们直接输入到查询中,如果忘记输入了则会引起语法错误。
如前所述,域名的长度也很关键,越短的域名越稀缺。除了搜索域名包含的字符,我们可以再添加一个域名长度过滤的参数{{name_length}},将其参数类型修改为下拉列表类型,同时填入数字5-20的序列作为参数值列表,每行一个值。因为Lens域名目前最少5个字符,而且超过20个字符的域名很少,所以我们选择5到20作为区间。参数设置如下图所示。

添加了新的参数后,我们调整SQL语句的WHERE子句为如下所示。其含义为查询名称包含输入的关键字,同时域名字符长度等于选择的长度值的域名列表。注意,虽然我们的name_length参数的值全部是数字,但List类型参数的默认类型是字符串,所以我们使用cast()函数转换其类型为整数类型后再进行比较。
where short_name like '%{{name_contains}}%' -- 名称包含输入的字符串的域名
and length(short_name) = cast('{{name_length}}' as integer) -- 域名长度等于选择的长度值同样,我们可以再添加一个域名字符串模式类型的参数{{name_pattern}},用来过滤纯数字域名或纯字母域名。这里同样设置参数为List类型,列表包括三个选项:Any、Pure Digits、Pure Letters。SQL语句的WHERE子句相应修改为如下所示。跟之前的查询类似,我们使用一个CASE语句来判断当前查询域名的类型,如果查询纯数字或者纯字母域名,则使用相应的表达式,如果查询任意模式则使用1 = 1这样的总是返回真值的相等判断,相当于忽略这个过滤条件。
where short_name like '%{{name_contains}}%' -- 名称包含输入的字符串的域名
and length(short_name) = cast('{{name_length}}' as integer) -- 域名长度等于选择的长度值
and (case when '{{name_pattern}}' = 'Pure Digits' then regexp_like(short_name, '^[0-9]+$')
when '{{name_pattern}}' = 'Pure Letters' then regexp_like(short_name, '^[a-z]+$')
else 1 = 1
end)因为我们在这几个搜索条件之间使用了and连接条件,相当于必须同时满足所有条件,这样的搜索有一定的局限性。我们对其做适当调整,name_length参数也再增加一个默认选项“0”。当用户未输入或者未选择某个过滤条件时,我们忽略它。这样搜索查询就变得非常灵活了。完整的SQL语句如下:
with profile_created as (
select json_value(vars, 'lax $.to') as user_address,
json_value(vars, 'lax $.handle') as handle_name,
replace(json_value(vars, 'lax $.handle'), '.lens', '') as short_name,
call_block_time,
output_0 as profile_id,
call_tx_hash
from lens_polygon.LensHub_call_createProfile
where call_success = true
)
select call_block_time,
profile_id,
handle_name,
short_name,
'<a href=https://polygonscan.com/tx/' || cast(call_tx_hash as varchar) || ' target=_blank>Polyscan</a>' as link,
call_tx_hash
from profile_created
where (case when '{{name_contains}}' <> 'keyword' then short_name like '%{{name_contains}}%' else 1 = 1 end)
and (case when cast('{{name_length}}' as integer) < 5 then 2 = 2
when cast('{{name_length}}' as integer) >= 20 then length(short_name) >= 20
else length(short_name) = cast('{{name_length}}' as integer)
end)
and (case when '{{name_pattern}}' = 'Pure Digits' then regexp_like(short_name, '^[0-9]+$')
when '{{name_pattern}}' = 'Pure Letters' then regexp_like(short_name, '^[a-z]+$')
else 3 = 3
end)
order by call_block_time desc
limit 1000我们给这个查询增加一个表格(Table)类型的可视化图表,并将其添加到数据看板中。当添加代参数的查询到数据看板时,所有的参数也被自动添加到看板头部。我们可以进入编辑模式,拖拽参数到其希望出现的位置。将图表加入数据看板后的效果图如下所示。
