TALLER REGRESIÓN LINEAL MÚLTIPLE
CARLOS ANDRÉS TORRES RICAURTE FERNANDO CARDONA HANSEN
22/3/2023
PUNTO 1
Antes de realizar el filtro a la base de datos se realiza análisis exploratorio del conjunto de datos llamado “vivienda” que cuenta con 8,322 registros y 12 columnas. Los datos cuentan con información de viviendas en venta en la ciudad de Cali en los últimos 3 meses. Al imprimir un resumen de los datos se observa que de los 12 atributos hay 10 que caracterizan a la vivienda, incluyendo la variable precio que es en este caso variable de interés, y 2 atributos de tipo coordenada, con la latitud y longitud de cada vivienda.
library(paqueteMOD)
data("vivienda")
vivienda <- as.data.frame(vivienda)
vivienda[vivienda == "NA"] <- NA
str(vivienda)## 'data.frame': 8322 obs. of 12 variables:
## $ Zona : chr "Zona Sur" "Zona Oeste" "Zona Sur" "Zona Sur" ...
## $ piso : chr "2" "2" "3" NA ...
## $ Estrato : num 6 4 5 6 6 6 6 5 4 6 ...
## $ precio_millon : num 880 1200 250 1280 1300 513 870 310 240 690 ...
## $ Area_contruida : num 237 800 86 346 600 160 490 82.5 80 150 ...
## $ parqueaderos : chr "2" "3" NA "4" ...
## $ Banos : num 5 6 2 6 7 4 6 2 2 5 ...
## $ Habitaciones : num 4 7 3 5 5 4 5 3 3 4 ...
## $ Tipo : chr "Casa" "Casa" "Apartamento" "Apartamento" ...
## $ Barrio : chr "pance" "miraflores" "multicentro" "ciudad jardín" ...
## $ cordenada_longitud: num -76.5 -76.5 -76.5 -76.5 -76.5 ...
## $ Cordenada_latitud : num 3.43 3.43 3.43 3.43 3.43 ...1.1 Análisis inicial
valores_na <- colSums(is.na(vivienda)) %>% as.data.frame()
print(valores_na)## .
## Zona 3
## piso 2638
## Estrato 3
## precio_millon 2
## Area_contruida 3
## parqueaderos 1605
## Banos 3
## Habitaciones 3
## Tipo 3
## Barrio 3
## cordenada_longitud 3
## Cordenada_latitud 3Se puede observar que las variables: Piso de la vivienda (Número de piso en el que queda ubicado la vivienda) y Parqueaderos (Número de parqueaderos disponibles en la vivienda), son los atributos que más cuentan con valores faltantes. Para efectos del presente ejercicio decidimos omitir el atributo Piso de la vivienda, puesto que no es requerido para el análisis. Para el atributo Parqueaderos asumiremos que los datos faltantes (1.605) corresponden a viviendas que no tienen parqueadero, puesto que tiene sentido que no todas las viviendas tengan un parqueadero propio.
summary(as.numeric(vivienda$parqueaderos))## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 1.000 1.000 2.000 1.835 2.000 10.000 1605Así pues, se excluye el atributo Piso, y se reemplazan aquellos valores de parqueaderos en NA iguales a 0, y se descartan los demás registros con algún valor NA.
df_viv <- vivienda[,-2]
df_viv$parqueaderos <- ifelse(is.na(df_viv$parqueaderos),
0,
as.numeric(df_viv$parqueaderos))
df_viv <- na.omit(df_viv)
print(dim(df_viv))## [1] 8319 11Finalmente, se imprime el dataset actualizado, y se observa que se eliminaron solo 3 registros en total (de 8322 a 8319 registros), identificando que que los valores de NA en los atributos de la tabla anterior correspondían a los 3 mismos registros.
1.2 Filtro y Mapeo Zona Norte
Como paso inicial en esta sección se filtra el subconjunto de viviendas clasificadas en la zona norte de la ciudad, llegando a un total hay 1920 registros. Corroboramos esta información imprimiendo la tabla de frecuencias de viviendas en cada zona, donde se observa que las viviendas en zona norte ocupan un 23,07%.
Además, La zona que más viviendas tiene es la Zona sur con el 56,8% y la que menos viviendas tiene es la Zona centro y Zona oriente con 1,49% y 4,21% respectivamente.
df_norte <- subset(df_viv, Zona == 'Zona Norte')
knitr::kable(head(df_norte,3), scrollable = TRUE)| Zona | Estrato | precio_millon | Area_contruida | parqueaderos | Banos | Habitaciones | Tipo | Barrio | cordenada_longitud | Cordenada_latitud | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 31 | Zona Norte | 3 | 135 | 56 | 1 | 1 | 3 | Apartamento | torres de comfandi | -76.46745 | 3.40763 |
| 58 | Zona Norte | 5 | 400 | 212 | 0 | 2 | 4 | Casa | santa mónica residencial | -76.47300 | 3.41800 |
| 71 | Zona Norte | 3 | 78 | 54 | 2 | 1 | 3 | Apartamento | chiminangos | -76.47820 | 3.44898 |
print(dim(df_norte))## [1] 1920 11cbind(table(df_viv$Zona),prop.table(table(df_viv$Zona))*100)## [,1] [,2]
## Zona Centro 124 1.490564
## Zona Norte 1920 23.079697
## Zona Oeste 1198 14.400769
## Zona Oriente 351 4.219257
## Zona Sur 4726 56.809713Mediante las funciones empleadas se imprime el encabezado de las primeras 3 viviendas en la zona norte. Además
head(df_norte,3)## Zona Estrato precio_millon Area_contruida parqueaderos Banos
## 31 Zona Norte 3 135 56 1 1
## 58 Zona Norte 5 400 212 0 2
## 71 Zona Norte 3 78 54 2 1
## Habitaciones Tipo Barrio cordenada_longitud
## 31 3 Apartamento torres de comfandi -76.46745
## 58 4 Casa santa mónica residencial -76.47300
## 71 3 Apartamento chiminangos -76.47820
## Cordenada_latitud
## 31 3.40763
## 58 3.41800
## 71 3.44898A continuación, procedemos a descargar el shape de las comunas de Cali seleccionando y descargando la capa de interés del geoportal de la [IDESC]{https://idesc.cali.gov.co/geovisor.php}. A continuación, realizamos proceso para cargar el shape, definiendo el reconocimiento de un objeto espacial de las coordenadas y la gráfica. Para las gráficas usamos las funciones de ggplot2.
# Cargamos el shp de comunas cali.
mapa <- readOGR(dsn = "/Users/fernando/Desktop/Maestria Ciencia de Datos/Maestría Ciencia de Datos/Métodos y simulación Estadística/Taller 2 Regresión lineal múltiple", layer = "Comunas")## Warning: OGR support is provided by the sf and terra packages among others## Warning: OGR support is provided by the sf and terra packages among others## Warning: OGR support is provided by the sf and terra packages among others## Warning: OGR support is provided by the sf and terra packages among others## Warning: OGR support is provided by the sf and terra packages among others## Warning: OGR support is provided by the sf and terra packages among others## OGR data source with driver: ESRI Shapefile
## Source: "/Users/fernando/Desktop/Maestria Ciencia de Datos/Maestría Ciencia de Datos/Métodos y simulación Estadística/Taller 2 Regresión lineal múltiple", layer: "Comunas"
## with 22 features
## It has 4 fields# Extracción de las coordenadas y conversión a puntos espaciales
puntos <- SpatialPointsDataFrame(coords = df_norte[,c("cordenada_longitud","Cordenada_latitud")],
data = df_norte,
proj4string = CRS(proj4string(mapa)))
# Grafica
gr1 <- ggplot() +
geom_polygon(data = mapa, aes(x = long, y = lat, group = group, fill = ""),
colour = alpha("black", 1/4), size = 0.2) + scale_fill_manual(values = c("white", "white")) +
geom_point(data = df_norte, aes(x = cordenada_longitud, y = Cordenada_latitud), color = "skyblue") +
ggtitle("Mapa de las viviendas clasificadas en Zona norte (n=1920)")## Regions defined for each Polygons## Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
## ℹ Please use `linewidth` instead.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.ggplotly(gr1)Se evidencia facilmente que hay viviendas que están localizadas fuera de la zona norte de la ciudad de Cali. Ahora bien, como datos adicionales tenemos las comunas almacenadas en los shapes y también los barrios. Para aproximamos a cuantificar la inconsistencia de la clasificación, primero asignamos unaa nueva columna: “comuna”.
# Asignamos la variable comuna :
df_norte$comuna <- over(puntos,mapa)$comunaDespués, se consideraron las comunas 6, 5, 4 y 2 como zona norte, según el mapa de comunas de cali ubicado aquí. De esta forma, se definiran como “fuera” aquellas viviendas con coordenadas localizadas fuera de estas comunas (“dentro” las que están dentro). Note que esta consideración de zona norte no es estricta, y solo se hace como metodología para ilustrar posibles incosistencias en la localización, con base en los poligonos de las comunas.
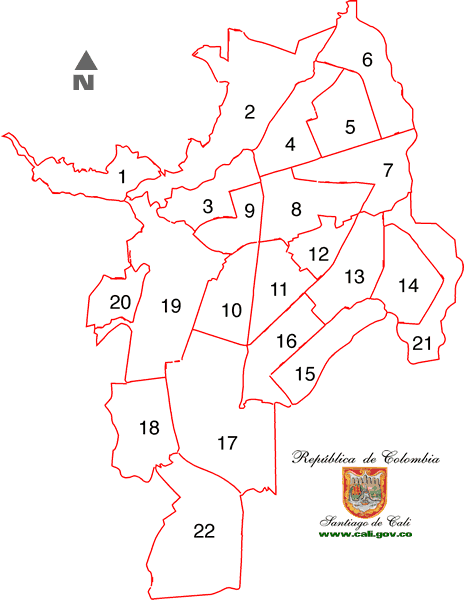{kind=link}
## Comunas 2, 4, 5 y 6 como Zona Norte. Se clasifican como aquellas que pertenecen a las comunas nombradas
df_norte$clasificacion <- ifelse(df_norte$comuna%in%c(6,5,4,2),"dentro","fuera")
tabla <- as.data.frame.matrix((table(df_norte$Barrio,df_norte$clasificacion)))
print(cbind(table(df_norte$clasificacion),prop.table(table(df_norte$clasificacion))*100))## [,1] [,2]
## dentro 1488 77.5
## fuera 432 22.5print(head(tabla[order(tabla$fuera, decreasing = TRUE),],10))## dentro fuera
## acopi 33 124
## la flora 324 41
## Cali 0 33
## prados del norte 107 17
## versalles 57 13
## urbanización la flora 71 12
## brisas de los 71 10
## el bosque 39 10
## san vicente 38 9
## torres de comfandi 48 7Se puede observar que del total de datos, un 22,5% quedaron fuera de la zona clasificada como Norte. A su vez, los barrios más afectados en la clasificación fueron Acopi, la Flora, Prados del norte y así sucesivamente. También se observan 33 viviendas que en lugar del barrio solo tienen “Cali”, dando mayor incertidumbre respecto a los origenes de las inconsistencias. Respecto a las fallas, se debe tener en cuenta:
Aspectos relacionados con el levantamiento y registro de la información: el atributo Zona puede verse afectado en su levantamiento, especialmente para Los registros que no tienen el atributo barrio (33 en total) y otros pocos registros que aún clasificados en la Zona Norte de la ciudad, tienen barrios localizados en el Sur como Valle del lili (4) y Ciudad Jardín (3) para dar un ejemplo.
La calidad de la geocodificación: el proceso de asignación de coordenadas a cada vivienda puede generar inconsistencias al asignar las coordenadas a nomenclaturas que se encuentren en ciertos lugares de la ciudad, por ejemplo, en el caso de viviendas de los barrios Acopi y la Flora que fueron las principales afectadas.
1.3 Análisis de correlación
En este caso se realiza el análisis descriptivo para el conjunto con todos los datos. Veamos la correlación lineal entre las variables numéricas:
library(corrplot)## corrplot 0.92 loadedlibrary(reshape)##
## Attaching package: 'reshape'## The following object is masked from 'package:plotly':
##
## rename## The following object is masked from 'package:dplyr':
##
## renamematriz_corr <- cor(df_viv[,c("precio_millon", "Area_contruida", "parqueaderos","Estrato", "Banos", "Habitaciones")])
# Crear gráfico en ggplot2
gg_cor_mat <- ggplot(data = as.data.frame(as.table(matriz_corr))) +
geom_tile(aes(Var1, Var2, fill = Freq)) +
scale_fill_gradient2(low = "#7fbf7b", high = "#d6604d", mid = "white", midpoint = 0, limit = c(-1, 1), space = "Lab", name="Pearson\nCorrelation") +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, vjust = 1, size = 12, hjust = 1))
# Convertir gráfico de ggplot2 a plotly
ggplotly(gg_cor_mat)Enfocándonos en el precio de las viviendas, se observa una correlación que varía de fuerte a moderada con varios atributos. En particular, encontramos una correlación fuerte entre el precio de las viviendas y el área construida (0.687), seguida por una correlación moderadamente fuerte con la cantidad de baños (0.66) y la cantidad de parqueaderos (0.639), y una correlación moderada con el estrato de la vivienda (0.60).
Sin embargo, observamos otras variables independientes que también tienen una correlación moderada o alta con otras variables. Por ejemplo, encontramos una correlación moderada entre el área construida y la cantidad de baños (0.64) y entre la cantidad de habitaciones y la cantidad de baños (0.58). Estas correlaciones podrían indicar la presencia de multicolinealidad, lo que podría generar problemas en los modelos de regresión y afectar la interpretación de los coeficientes de las variables.
plot_ly(data = df_viv, x = ~Zona, y = ~precio_millon, type = "box", color="")## Warning in RColorBrewer::brewer.pal(N, "Set2"): minimal value for n is 3, returning requested palette with 3 different levels
## Warning in RColorBrewer::brewer.pal(N, "Set2"): minimal value for n is 3, returning requested palette with 3 different levelsEl gráfico de cajas y alambres muestra que en la Zona Oriente se encuentra el precio mínimo global de la vivienda con un valor de $58 millones de pesos y en la zona oeste se encuentra la vivienda con el precio máximo con un total de $1.999 millones. También se observa que los precios tienen una menor variabilidad en la Zona centro de la ciudad y en la zona oriente, y en contraste, las zonas con precios más variables son la zona oeste y la zona sur. En genral, al observar la longitud mayor alambres superiores y los puntos superiores por fuera de los rangos intercuartilicos, se puede decir que, en todas las zonas, las distribuciones de precios de las viviendas es asimetrica hacia precios más bajos.
1.4 Modelos de Regresión
Propuesta 1
Según las variables solicitadas para ajustar el modelo, descartamos la zona, el barrio y el tipo de casa. Pero antes, para dar respuesta a la primera solicitud ajustamos un modelo con los datos filtrados dejando solo aquellas viviendas de tipo casa, en la zona norte de la ciudad, correpondiente a un total de 722 viviendas.
Se ajusta el modelo y se presentan sus resultados:
library(lmtest)## Loading required package: zoo##
## Attaching package: 'zoo'## The following objects are masked from 'package:base':
##
## as.Date, as.Date.numericdf_n_casas <-subset(df_norte, Tipo=='Casa')
mod_p1 <- lm(precio_millon ~ Area_contruida + parqueaderos + Estrato + Banos + Habitaciones, data= df_n_casas)
summary(mod_p1)##
## Call:
## lm(formula = precio_millon ~ Area_contruida + parqueaderos +
## Estrato + Banos + Habitaciones, data = df_n_casas)
##
## Residuals:
## Min 1Q Median 3Q Max
## -964.04 -80.10 -17.08 50.06 1069.45
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -236.47551 30.36582 -7.788 2.40e-14 ***
## Area_contruida 0.82677 0.04368 18.926 < 2e-16 ***
## parqueaderos -1.67672 4.31505 -0.389 0.698
## Estrato 86.42579 7.39747 11.683 < 2e-16 ***
## Banos 26.97978 5.34384 5.049 5.65e-07 ***
## Habitaciones 1.44443 4.16411 0.347 0.729
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 159.1 on 716 degrees of freedom
## Multiple R-squared: 0.6508, Adjusted R-squared: 0.6484
## F-statistic: 266.9 on 5 and 716 DF, p-value: < 2.2e-16En general, con una significancia del 5% concluimos que el modelo es significativo para explicar el precio de las viviendas, afirmandose que almenos uno de los coeficientes estimados es diferente de 0. Ahora bien, al mirar la prueba especifica para estos coeficientes, podemos concluir que las variables significativas son Area construida, Estrato y Baños, y las variables no significativas en el modelo son: Parqueaderos con un Pvalor de 0.69 y Habitaciones con un Pvalor de 0.72. Respecto a la coherencia de los signos, el único que no tiene lógica es el coeficiente de Parqueaderos que tiene signo negativo, asumiendo que existe una relación inversamente proporcional entre el número de parqueaderos y el precio de las viviendas.
La interpretación de los coeficientes de las variables significativas es la siguiente:
El intercepto: no tiene interpretación práctica en el ejercicio, puesto que no hay lógica en igualar a cero variables como Número de baños, Área construida, etc.
Área construida: manteniendo las demás variables constantes y aumentando en un metro cuadrado el área de la vivienda, se espera que el precio aumente en promedio $0,82 millones de pesos (aproximadamente $827.000).
Estrato: manteniendo las demás variables constantes y aumentando en un nivel el estrato socioeconómico, se espera que el precio de la vivienda aumente en promedio $86,42 millones de pesos.
Baños: Manteniendo las demás variables constantes y aumentando en uno el número de baños de la vivienda, se espera que su precio aumente en promedio $26,97 millones de pesos.
Respecto al ajuste del modelo, el R cuadrado nos indica que el modelo explica el 65,08% de las variaciones totales de los precios de las viviendas y que los errores del modelo tienden a dispersarse alrededor de más o menos 159.1 millones respecto a los valores observados.
Supuestos
graficos <- plot(mod_p1, which = 1:2)

shapiro.test(mod_p1$residuals)##
## Shapiro-Wilk normality test
##
## data: mod_p1$residuals
## W = 0.83823, p-value < 2.2e-16bptest(mod_p1)##
## studentized Breusch-Pagan test
##
## data: mod_p1
## BP = 139, df = 5, p-value < 2.2e-16En general, los supuestos del modelo no se cumplen: Los puntos de los valores esperados y los residuales muestra que los residuales presentan una mayor varianza a mayores valores ajustados, además el p-valor del test Breaush arroja un p-valor $ $ 0, rechazando la hipótesis de varianza constante. La normalidad, muestra un resultado similar, donde se observa que en los extremos de los residuales el comportamiento es diferente al hipoteticamente normal, además el test de Shapiro Wilk arroja resultados en contra del cumplimiento del supuesto (p-valor $ $ 0)
Propuestas para mejorar el modelo:
Se debería considerar inicialmente la inclusión de otras variables que, apriori, pueden estar relacionadas directamente con el precio de una vivienda. Variables como la antiguedad de la vivienda, la cercanía a vías principales o la seguridad en términos de número de robos en la comuna, por ejemplo. También se pueden descartar algunas variables independientes que están altamente relacionadas entre sí, para evitar inconsistencias en el análisis debido a problemas de multicolinealidad.
Si no hay acceso a otras variables, consideramos que deben realizarse procesos de transformación de variables, usando la metodología de Box y Cox, para generar estabilidad de la varianza y ajuste normal de los residuales.
Predicción.
Con los datos requeridos por el cliente se predice el precio de una vivienda con las siguientes caracteristicas: $ , Area =200 ,| ,parqueaderos=1,|,estrato = 4 ,o, 5,|, baños=2,|,habitaciones = 4 $.
## Prediccion
new_dat <- data.frame(
Area_contruida = 200,
parqueaderos = 1,
Estrato = c(4, 5),
Banos = 2,
Habitaciones = 4
)
predict(mod_p1,new_dat, level = 0.95, interval = "confidence")## fit lwr upr
## 1 332.6430 315.0703 350.2157
## 2 419.0688 394.1807 443.9569Con una confianza del 95% se puede afirmar que una vivienda tipo casa con 200 \(m^2\) 1 parqueadero, 2 baños, 4 habitaciones, y ubicada en el estrato 4 de la zona norte de la ciudad tendrá un precio esperado de $ 312,10 millones de pesos que puede variar entre $287,19 a $ 337,01 millones. Ahora bien, una vivienda con estas mismas caracteristicas en el estrato 5 tendría un precio esperado de $ 360,88 millones que variaría entre $ 360.88 a $ 424,59 millones.
Propuesta de compra:
df_n_casas$prediccion <- mod_p1$fitted.values
estrato4 <- df_n_casas %>%
filter(precio_millon <= 350 &
prediccion > 350 &
Estrato == 4 &
parqueaderos > 0) %>%
select(-Zona, -clasificacion, -Tipo) %>%
arrange(desc(prediccion))
estrato5 <- df_n_casas %>%
filter(precio_millon <= 350 &
prediccion > 350 &
Estrato == 5 &
parqueaderos > 0) %>%
select(-Zona, -clasificacion, -Tipo) %>%
arrange(desc(prediccion))
rbind(estrato4[1:5,],estrato5[1:5,])## Estrato precio_millon Area_contruida parqueaderos Banos Habitaciones
## 1 4 350 350 1 4 5
## 2 4 340 264 2 5 7
## 3 4 335 300 3 4 4
## 4 4 260 280 2 4 6
## 5 4 315 270 2 4 4
## 6 5 340 355 2 5 8
## 7 5 350 300 3 5 6
## 8 5 321 249 1 5 5
## 9 5 350 346 1 2 4
## 10 5 340 240 2 5 6
## Barrio cordenada_longitud Cordenada_latitud comuna prediccion
## 1 salomia -76.53464 3.44987 3 512.0631
## 2 vipasa -76.54980 3.37556 18 469.1525
## 3 el bosque -76.52600 3.43400 9 465.9265
## 4 los andes -76.54973 3.42484 19 453.9566
## 5 el bosque -76.53176 3.48780 2 442.8000
## 6 san vicente -76.52377 3.46384 2 632.2591
## 7 el bosque -76.53010 3.48577 2 582.2210
## 8 la merced -76.50291 3.46757 5 541.9645
## 9 vipasa -76.51847 3.47503 2 539.7778
## 10 la campiña -76.52640 3.48211 2 534.2913propuesta1 <- rbind(estrato4[1:5,],estrato5[1:5,])
puntos <- SpatialPointsDataFrame(coords = propuesta1[,c("cordenada_longitud","Cordenada_latitud")],
data = propuesta1,
proj4string = CRS(proj4string(mapa)))
# Grafica
gr2 <- ggplot() +
geom_polygon(data = mapa, aes(x = long, y = lat, group = group, fill = ""),
colour = alpha("black", 1/4), size = 0.2) + scale_fill_manual(values = c("white", "white")) +
geom_point(data = propuesta1, aes(x = cordenada_longitud, y = Cordenada_latitud), color = "skyblue") +
ggtitle("Propuesta de casas en Zona norte")## Regions defined for each Polygonsggplotly(gr2)Propuesta 2
Ahora se presenta el ajuste para encontrar las viviendas de la zona sur.
df_sur = subset(df_viv, df_viv$Zona == "Zona Sur")
puntos <- SpatialPointsDataFrame(coords = df_sur[,c("cordenada_longitud","Cordenada_latitud")],
data = df_sur,
proj4string = CRS(proj4string(mapa)))
# Grafica
gr3 <- ggplot() +
geom_polygon(data = mapa, aes(x = long, y = lat, group = group, fill = ""),
colour = alpha("black", 1/4), size = 0.2) + scale_fill_manual(values = c("white", "white")) +
geom_point(data = df_sur, aes(x = cordenada_longitud, y = Cordenada_latitud), color = "skyblue") +
ggtitle("Mapa de las viviendas clasificadas en Zona sur (n=4.726)")## Regions defined for each Polygonsggplotly(gr3)# Asignamos la variable comuna :
df_sur$comuna <- over(puntos,mapa)$comunaDespués, se consideraron las comunas 17, 18 y 22 como Zona Sur y se realiza la misma metodología para estudiar las casas fuera y dentro del rango establecido.
# Comunas 18, 17, 22 como sur. Se clasifican como aquellas que pertenecen a las comunas nombradas
df_sur$clasificacion <- ifelse(df_sur$comuna%in%c(10,18,17,22),"dentro","fuera")
tabla <- as.data.frame.matrix((table(df_sur$Barrio,df_sur$clasificacion)))
View(tabla)En este caso el barrio con más viviendas fuera de la Zona Sur es Valle del lilí, el Refugio y Ciudad 2000, con 140, 105 y 84 casos respectivamente.
Ajustamos el modelo y presentamos sus resultados:
df_s_apto <-subset(df_sur, Tipo=='Apartamento')
mod_p2 <- lm(precio_millon ~ Area_contruida + parqueaderos + Estrato + Banos + Habitaciones, data= df_s_apto)
summary(mod_p2)##
## Call:
## lm(formula = precio_millon ~ Area_contruida + parqueaderos +
## Estrato + Banos + Habitaciones, data = df_s_apto)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1252.31 -42.15 -2.06 36.32 934.06
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -221.04614 13.47771 -16.401 < 2e-16 ***
## Area_contruida 1.46061 0.04876 29.956 < 2e-16 ***
## parqueaderos 48.36353 3.02343 15.996 < 2e-16 ***
## Estrato 57.00608 2.79648 20.385 < 2e-16 ***
## Banos 48.60871 3.04050 15.987 < 2e-16 ***
## Habitaciones -22.71789 3.39549 -6.691 2.68e-11 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 95.17 on 2781 degrees of freedom
## Multiple R-squared: 0.7536, Adjusted R-squared: 0.7531
## F-statistic: 1701 on 5 and 2781 DF, p-value: < 2.2e-16En general, con una significancia del 5% se puede concluir que el modelo es significativo para explicar el precio de los apartamentos de la Zona Sur, ya que al menos uno de los coeficientes estimados es diferente de 0. Ahora bien, al mirar la prueba especifica para estos coeficientes, se puede concluir que todas las variables son significativas. Respecto a la coherencia de los signos, el único que no tiene lógica es el coeficiente de habitaciones que tienen signo negativo, asumiendo una relación inversamente proporcional negativa entre el número de habitaciones y el precio del apartamento.
A continuación, interpretamos los coeficientes:
El intercepto: no tiene interpretación práctica en el ejercicio, puesto que no hay lógica en igualar a cero variables como número de baños, área construida, etc.
Área construida: manteniendo las demás variables constantes y aumentando en un metro cuadrado el área de la vivienda, se espera que el precio de un apartamento aumente en promedio $1,4 millones de pesos.
Parqueaderos: manteniendo las demás variables constantes y aumentando en uno el número de parqueaderos, se espera que el precio de un apartamento aumente en promedio $48,36 millones de pesos.
Estrato: manteniendo las demás variables constantes y aumentando en un nivel el estrato socioeconómico, se espera que el precio del apartamento aumente en promedio $57,01 millones de pesos.
Baños: manteniendo las demás variables constantes y aumentando en uno el número de baños del apartamento, se espera que su precio aumente en promedio $48,6 millones de pesos.
Habitaciones: manteniendo las demás variables constantes y aumentando en uno el número de habitaciones, se espera que su precio disminuya en promedio $22.71 millones de pesos. Nota: En este caso el coeficiente de las habitaciones puede estar siendo afectado por problemas de multicolinealidad o falta de ajuste del modelo.
Respecto al ajuste del modelo, el R cuadrado indica que el modelo explica el 75,36% de las variaciones totales de los precios de los apartamentos de la zona sur y que los errores del modelo tienden a dispersarse alrededor de más o menos 95.17 millones respecto a los valores observados.
Supuestos
graficos <- plot(mod_p2, which = 1:2)

shapiro.test(mod_p2$residuals)##
## Shapiro-Wilk normality test
##
## data: mod_p2$residuals
## W = 0.78157, p-value < 2.2e-16bptest(mod_p2)##
## studentized Breusch-Pagan test
##
## data: mod_p2
## BP = 956.83, df = 5, p-value < 2.2e-16Igual que en el primer modelo, no se cumplen los supuestos de normalidad ni varianza constante.
Propuestas para mejorar el modelo:
Las mismas mejoras de modelo aplican para esta situación (Ver Propuesta 1).
Predicción:
Con los datos requeridos por el cliente se predice el precio de una vivienda con las siguientes caracteristicas: $ , Area =300 ,| ,parqueaderos=3,|, baños=3,|,habitaciones = 5 ,|,estrato = 5 , o , 6,|$. Recordando que el crédito máximo es de $850 millones de pesos.
## Prediccion
new_dat <- data.frame(
Area_contruida = 300,
parqueaderos = 3,
Estrato = c(5, 6),
Banos = 3,
Habitaciones = 5
)
predict(mod_p2,new_dat, level = 0.95, interval = "confidence")## fit lwr upr
## 1 679.4951 659.3575 699.6328
## 2 736.5012 716.2264 756.7760Con una confianza del 95% se puede afirmar que un apartamento con 300 \(m^2\) 3 parqueadero, 3 baños, 5 habitaciones, y ubicada en el estrato 5 de la Zona Sur de la ciudad tendrá un precio esperado de $ 679,49 millones de pesos que puede variar entre $659,35 a $ 699,6 millones. Ahora bien, un apartamento con estas mismas caracteristicas en el estrato 5 tendría un precio esperado de $ 736,50 millones que variaría entre $ 716.22 a $ 756.77 millones.
Propuesta de compra:
Con base en los valores ajustados se realiza un filtro por estrato de las viviendas, para aquellas que el modelo considera que están por encima del monto de 850 millones y que a su vez el precio real esté en menos de este monto. Los resultados se organizan de forma decreciente con respecto a las predicciones.
df_s_apto$prediccion <- mod_p2$fitted.values
estrato5_1 <- df_s_apto %>%
filter(precio_millon <= 850 &
prediccion > 850 &
Estrato == 5) %>%
select(-Zona, -clasificacion, -Tipo) %>%
arrange(desc(precio_millon))
estrato6 <- df_s_apto %>%
filter(precio_millon <= 850 &
prediccion > 850 &
Estrato == 6) %>%
select(-Zona, -clasificacion, -Tipo) %>%
arrange(desc(precio_millon))
rbind(estrato5_1[1:5,],estrato6[1:1,])## Estrato precio_millon Area_contruida parqueaderos Banos Habitaciones
## 1 5 730 573 3 8 5
## 2 5 690 486 2 4 4
## 3 5 650 600 2 4 5
## 4 5 299 932 1 3 3
## 5 5 170 605 1 2 2
## 6 6 850 352 4 3 3
## Barrio cordenada_longitud Cordenada_latitud comuna prediccion
## 1 guadalupe -76.54800 3.40800 19 1321.2857
## 2 el ingenio -76.53111 3.38292 17 974.1320
## 3 el ingenio -76.53400 3.38100 17 1117.9239
## 4 valle del lili -76.54087 3.37348 17 1551.3106
## 5 el limonar -76.54294 3.39992 17 1047.7997
## 6 pance -76.53729 3.34265 22 906.2523propuesta2 <- rbind(estrato5_1,estrato6)
puntos <- SpatialPointsDataFrame(coords = propuesta2[,c("cordenada_longitud","Cordenada_latitud")],
data = propuesta2,
proj4string = CRS(proj4string(mapa)))
# Grafica
gr2 <- ggplot() +
geom_polygon(data = mapa, aes(x = long, y = lat, group = group, fill = ""),
colour = alpha("black", 1/4), size = 0.2) + scale_fill_manual(values = c("white", "white")) +
geom_point(data = propuesta2, aes(x = cordenada_longitud, y = Cordenada_latitud), color = "skyblue") +
ggtitle("Propuesta de aptos clasificadas en Zona sur")## Regions defined for each Polygonsggplotly(gr2)