| itle: “ANLY 512 Problem Set 2” |
| ubtitle: Introduction to Data Visualization |
| uthor: “Md Hasan Shahriar Simanto” |
| ate: “2023-02-14” |
| utput: |
| html_document: default |
Directions
In this chapter we discussed why well-designed data graphics are important and we described a taxonomy for understanding their composition.
The objective of this assignment is for you to understand what characteristics you can use to develop a great data graphic.
Each question is worth 5 points.
To submit this homework you will create the document in Rstudio, using the knitr package (button included in Rstudio) and then submit the document to your Rpubs account. Once uploaded you will submit the link to that document on Canvas. Please make sure that this link is hyper linked and that I can see the visualization and the code required to create it.
Question #1
Answer the following questions for this graphic Relationship between ages and psychosocial maturity
{kind=link}
- Identify the visual cues, coordinate system, and scale(s)
- How many variables are depicted in the graph? Explicitly link each variable to a visual cue that you listed above.
- Critique this data graphic using the taxonomy described in the lecture.
#Answer
#a. the green bars represent the range of age for menarche and the red bars represent the range of age for psychosocial maturation, the y-axis represents age in years and x-axis represents Time in years
#b. Two variables are presented in the graph, the age range for menarche and the age range for psychosocial maturation on each timeframe
#c. Among the four taxonomy described in the lecture, visual cues, co-ordinate systems, and scales were relatively clear. Although the visual cues could have been easier on the eye if different color were chose. However, the context were not super clear. Perhaps a well described title could help. Question #2
Answer the following questions for this graphic World’s top 10 best selling cigarette brands 2004-2007
- Identify the visual cues, coordinate system, and scale(s)
- How many variables are depicted in the graph? Explicitly link each variable to a visual cue that you listed above.
- Critique this data graphic using the taxonomy described in the lecture.
#Answer
#a. the 10 horizontal bars represent top 10 best selling cigarette brands between 2004 & 2007 timeframe, the x-axis represents sales in billion dollars and y-axis is the brand names (descending order, the most sold brand on the top)
#two variables, number of brands and their total sales in billion dollars. each color represents differen cigrate brands as well.
#co-ordinate system, context, and scale were clear. However, visual cues were not perfect. The color red, or visually similar color was used to represent multiple brandsQuestion #3
Find two data graphics published in a newspaper on on the internet in the last two years.
- Identify a graphical display that you find compelling. What aspects of the display work well, and how do these relate to the principles that we have just gone over in lecture. Include a screenshot of the display along with your solution (Hint:use the following in a code chunk: knitr::include_graphics(“your_graphic”).
knitr::include_graphics("C:/Users/SIMANTO/Desktop/HCID/Data Visualization/FT_22.10.17_GlobalTurnout_dot.png")
#I like this graph as it showed how voter turnout is lower in america compared to other countries. It also had added information on how that looks like for registered voters.
#The fact that it allows the comparison between non-registered and registered voter turnout for a specific country and the comparison of those two variables between all other countries in a really easy way, works really well. It provides solid context, visual cues are clear, co-ordinate is visually clear, and scale is well explained.- Identify a graphical display that you find less compelling. What aspects of the display don’t work well? Are there ways that the display might be improved? Include a screenshot of the display along with your solution (Hint:use the following in a code chunk: knitr::include_graphics(“your_graphic”).
knitr::include_graphics("C:/Users/SIMANTO/Desktop/HCID/Data Visualization/FT_21.05.18_GenderPayGapUpdate_new.png")
## the gender gap graph is also interesting because it used percentage of something to represent a concept. On the y-axis, the median hourly earnings of US women was represented as percentage of men's median earling. When the abosolute value of something doesn't beer much significance, rather the difference does, this type of graph works well. The scale, co-ordinates, context, and visual cues were also up to the mark.Question #4
Briefly (one paragraph) critique the designer’s choices. Would you have made different choices? Why or why not? Note: Link contains a collection of many data graphics, and I don’t expect (or want) you to write a full report on each individual graphic. But each collection shares some common stylistic elements. You should comment on a few things that you notice about the design of the collection.
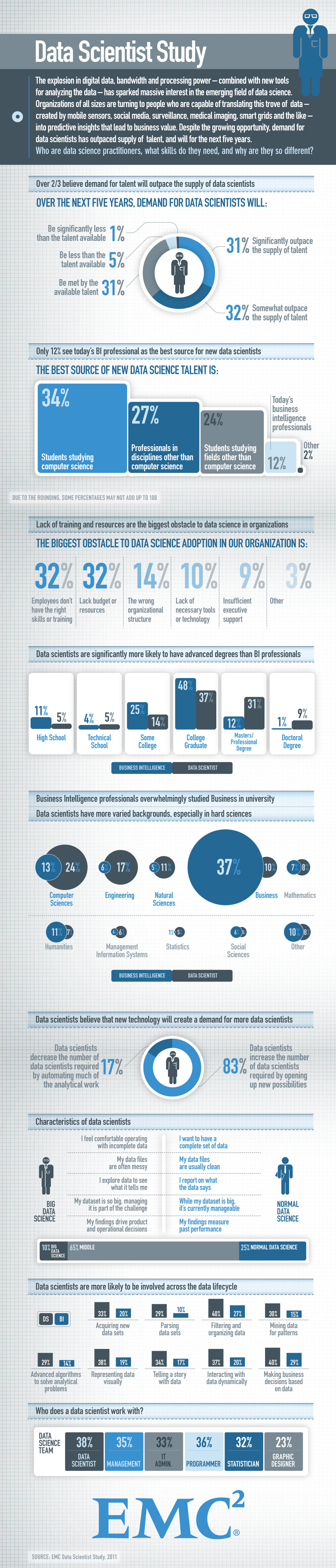{kind=link}
Answer:
#the graphic related to data science have used a few types of visual representations - bar plot, pie chart, and bubbles. Although the scale, co-ordinate, and the context was clear, the visual cues did not always clearly expressed what it means. For example, the label "Be significantly less than the talent available" beside 1% with a title that represent data scientist demand was not clear. A clear labeling could help, but if the goal was to represent the demand vs supply, pie chart isn't the best for that.
#similarly, bar charts were used when pie charts could have been more appropriate. For example, "Who does a data scientist work with?" graph would have been much easier to consume if it was a pie chart.
#last but not the least, most of the graphics looked like very difficult to consume because all the details needed to understand the meanings are in different places. For example, the involvement of different data lifecylce could have been much easily represented with a combined graph (x- axis all the lifecycle stages and y-axis the DS & BI percentage)Question #5
Briefly (one paragraph) critique the designer’s choices. Would you have made different choices? Why or why not? Note: Link contains a collection of many data graphics, and I don’t expect (or want) you to write a full report on each individual graphic. But each collection shares some common stylistic elements. You should comment on a few things that you notice about the design of the collection.
Charts that explain food in America
Answer:
#The article has a lot of graphs, majority of those are in maps. Map can be a really interesting way of representing distribution of geographic information. Different colors usually on a map represent different variables, or sometimes a single color with different sharpness represents the volume of something. For example, the graph #9 Farmers are getting older - graph has a single variable presented with a single color but with variation in the sharpness of the same color. Furthermore, graph #3 And we keep losing farms, had two different color dots for two different variable.
#The problem, however, arises when multiple colors are involved with different sharpness for each colors. It is really painful in the eye and different to measure anything (although it looks beautiful, artistically). Take graph #6 and #5, for example. Both of the graphs had multiple variables represented by multiple color and the volume of those variables were represented by the sharpness of the colors. Very difficult to understand.
#Some flat out bad graphs were also there. For example, #14 Total meat consumption, violates almost all the taxonomy best practices. No clear scale or co-ordinates, no tilte - the only context was that it looked like a map, somewhat!